RAG SEO: La Guía Completa para Escribir Contenido para Generación Aumentada por Recuperación
Última actualización: 18 October 2025
Aquí un escenario que se repite miles de veces al día: Un cliente potencial pregunta a Perplexity, "¿Cuál es la mejor herramienta de gestión de proyectos para equipos remotos?" La IA busca en la web, recupera fragmentos de cientos de páginas y sintetiza una respuesta.
Tu página era #3 en Google para esa consulta exacta. Pero la IA no te citó. Citó a un competidor cuya página estaba optimizada para recuperación, no solo para ranking.
Bienvenido al mundo del RAG SEO — una disciplina que rápidamente se está volviendo tan importante como el SEO tradicional, pero que permanece casi completamente desconocida para la mayoría de equipos de marketing.
RAG (Retrieval-Augmented Generation / Generación Aumentada por Recuperación) es la tecnología que conecta modelos IA congelados con datos en vivo. Es cómo ChatGPT puede responder preguntas sobre eventos de ayer. Es cómo Perplexity proporciona resultados de búsqueda en tiempo real.
Si quieres que la IA cite tu contenido, necesitas entender cómo piensan los sistemas RAG — y reestructurar tu contenido en consecuencia. Las organizaciones enterprise están usando arquitecturas RAG para investigación de mercado sintética mediante multi-model polling.
Tabla de Contenidos
- ¿Qué es RAG y Por Qué Importa?
- El Pipeline RAG: Cómo la IA "Lee" Tu Contenido
- El Fenómeno "Perdido en el Medio"
- El Factor de Recuperabilidad
- Content Chunking: Escribiendo para Consumo IA
- Densidad Semántica
- Tablas, Listas y Formatos Estructurados
- Checklist de Optimización RAG
- Midiendo el Rendimiento RAG
- FAQ
¿Qué es RAG y Por Qué Importa?
La mayoría malentiende cómo funcionan los LLMs. Imaginan una vasta base de datos de hechos que la IA busca. Pero eso no es preciso.
Los LLMs son fundamentalmente sistemas generativos. Completan texto basándose en patrones aprendidos durante el entrenamiento. No "recuperan" hechos — alucinan texto que parece plausible.
Esto crea problemas:
- Información desactualizada: Los datos de entrenamiento tienen una fecha de corte
- Riesgo de alucinación: El modelo puede generar sinsentido con confianza
- Conocimiento estático: No puede responder sobre eventos recientes
RAG resuelve estos problemas añadiendo un paso de recuperación antes de la generación.
Dónde Se Usa RAG
| Sistema | Implementación RAG |
|---|---|
| Perplexity | RAG pesado — busca en la web para cada consulta |
| ChatGPT (Navegar con Bing) | RAG opcional — el usuario puede habilitar búsqueda web |
| Google AI Overviews | RAG integrado desde el índice de Google |
| Claude + Artifacts | RAG para documentos subidos |
| IA Enterprise | RAG personalizado sobre bases de conocimiento |
Si no estás optimizado para RAG, eres cada vez más invisible para la búsqueda asistida por IA.
El Pipeline RAG
Entender el pipeline técnico te ayuda a optimizar para él:

Paso 1: Rastreo e Indexación
El sistema IA rastrea páginas web y las divide en "chunks" — típicamente de 200-500 tokens cada uno. Estos chunks se convierten en embeddings vectoriales (representaciones matemáticas del significado).
Tu oportunidad: Asegura que tu contenido sea rastreable (optimización de robots.txt) y estructurado de formas que creen chunks coherentes.
Paso 2: Procesamiento de Consulta
Cuando un usuario hace una pregunta, esa pregunta también se convierte en un embedding vectorial.
Tu oportunidad: Escribe contenido que semánticamente coincida con cómo los usuarios formulan preguntas.
Paso 3: Recuperación
El sistema encuentra chunks cuyos embeddings son matemáticamente similares al embedding de la pregunta. Usualmente se recuperan los 5-20 chunks más relevantes.
Tu oportunidad: Crea chunks que respondan directamente preguntas comunes.
Paso 4: Ensamblaje de Contexto
Los chunks recuperados se ensamblan en una "ventana de contexto" que el LLM usará para generar su respuesta.
Tu oportunidad: Escribe párrafos autocontenidos que proporcionen valor incluso fuera de contexto.
Paso 5: Generación
El LLM genera una respuesta basada en el contexto proporcionado más su conocimiento de entrenamiento.
Tu oportunidad: Incluye declaraciones citables y autoritativas que el LLM querrá citar.
El Fenómeno "Perdido en el Medio"
Uno de los hallazgos más importantes en investigación RAG es el efecto "perdido en el medio". Cuando los LLMs reciben ventanas de contexto largas, prestan más atención a:
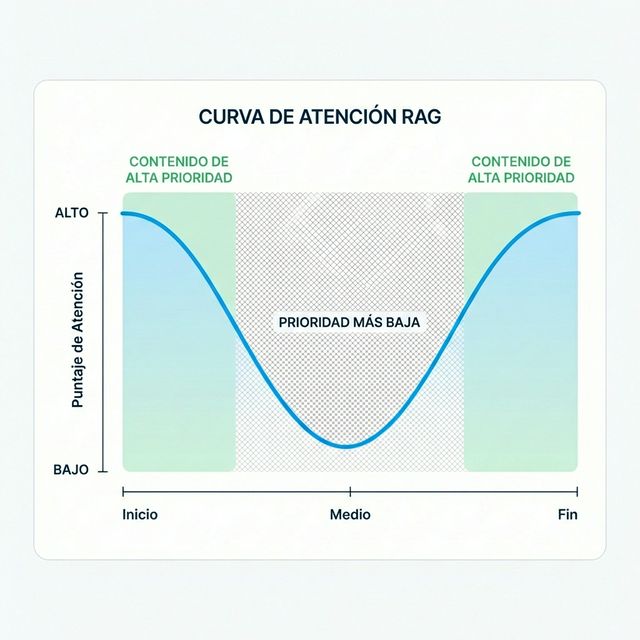
- El inicio del contexto
- El final del contexto
- Mucho menos atención al medio
Implicaciones Estratégicas
| Posición del Contenido | Nivel de Atención IA | Qué Poner Aquí |
|---|---|---|
| Primer 10% del artículo | ALTO | Definiciones clave, claims principales, TL;DR |
| 80% del medio | MENOR | Evidencia de soporte, ejemplos, profundidad |
| Último 10% | ALTO | Resumen, conclusiones clave, calls to action |
El Factor de Recuperabilidad
En Optimización para Motores Generativos, no solo optimizamos para "legibilidad" — optimizamos para recuperabilidad.
El SEO tradicional pregunta: "¿Rankea esta página para la keyword?" El RAG SEO pregunta: "¿Se recuperarán chunks de esta página para consultas relevantes?"
Qué Hace al Contenido Recuperable
| Factor | Descripción | Cómo Optimizar |
|---|---|---|
| Relevancia Semántica | Similitud de embedding con consulta | Usa headers enfocados en preguntas |
| Densidad de Información | Ratio datos-a-palabras | Elimina relleno, empaca datos en cada párrafo |
| Especificidad | Concreto vs. genérico | Incluye números, nombres, ejemplos específicos |
| Señales de Recencia | Indicadores de frescura | Fecha el contenido, referencia el año actual |
| Marcadores de Autoridad | Indicadores de credibilidad | Cita fuentes, muestra expertise |
La Brecha de Recuperación
Puedes rankear #1 en Google y aún tener baja recuperabilidad. ¿Por qué?
- Tu contenido puede estar optimizado para keyword matching, no significado semántico
- Tus datos clave pueden estar enterrados en párrafos rellenos
- Tu página puede no responder directamente la pregunta
Ejemplo:
- Usuario pregunta: "¿Cuál es el mejor CRM para PYMES por menos de $50/mes?"
- Tu página rankea #1 para "mejor CRM pequeña empresa"
- Pero tu página dice "Contacta ventas para precios"
- La IA recupera al competidor que dice "HubSpot Starter: $45/mes"
- El competidor es citado, tú no.
Content Chunking
El cambio más radical en optimización RAG es pensar en tu contenido como chunks, no páginas.
La Regla del Párrafo Autocontenido
Cada párrafo (o pequeño grupo) debe ser comprensible por sí solo:
| ❌ Evitar | ✅ Preferir |
|---|---|
| "Como mencionamos en la sección anterior..." | Reafirmar el punto clave |
| "Esta herramienta tiene varias ventajas..." (vago) | "[Nombre] ofrece tres ventajas core: [listarlas]" |
| "La solución a este problema es..." | "La solución al [problema específico] es [solución específica]" |
| Referencias a "arriba" o "abajo" | Enlaces explícitos o contexto completo |
El Patrón Header-Respuesta
Para cada header H2 o H3, el párrafo inmediatamente siguiente debe responder directamente la pregunta implícita en el header.
## ¿Qué es la Optimización para Motores Generativos?
La Optimización para Motores Generativos (GEO) es la práctica de
optimizar contenido y presencia digital para aparecer en respuestas
generadas por IA de LLMs como ChatGPT, Claude y Gemini. A diferencia
del SEO tradicional que se enfoca en rankings, GEO se enfoca en
frecuencia de citación e inclusión en recomendaciones.
Guías de Longitud de Chunks
La mayoría de sistemas RAG usan chunks de 200-500 tokens (~150-400 palabras):
- Cada sección mayor (H2) debe cubrir ~300-500 palabras
- Subsecciones (H3) deben ser ~150-250 palabras
- Mantén párrafos de 3-5 oraciones
Más largo no significa mejor para RAG. Una mega-guía de 5,000 palabras puede funcionar peor que cinco artículos enfocados de 1,000 palabras.
Densidad Semántica
La densidad semántica se refiere a la cantidad de información meaningful y específica por unidad de texto. Es quizás el factor más importante en optimización RAG.
Baja vs. Alta Densidad Semántica
| Baja Densidad (Malo para RAG) | Alta Densidad (Bueno para RAG) |
|---|---|
| "Nuestra solución líder provee resultados best-in-class" | "AICarma monitorea 12 plataformas IA incluyendo ChatGPT, Claude y Gemini" |
| "Hemos ayudado a muchas empresas a tener éxito" | "Incrementamos visibilidad IA en 340% para 127 empresas B2B SaaS" |
| "Precios competitivos disponibles" | "Planes desde $299/mes para hasta 50 consultas rastreadas" |
| "Funciones incluyen capacidades avanzadas" | "Funciones: monitoreo en tiempo real, análisis de sentimiento, tracking competitivo, acceso API" |
La Auditoría de Relleno
Revisa tu contenido e identifica:
- Frases de relleno: "En el mundo acelerado de hoy," "Es obvio que"
- Claims vagos: "confiado por empresas líderes," "best-in-class"
- Redundancia: Decir lo mismo de múltiples formas
- Preámbulos: Introducciones que retrasan la información real
Tablas, Listas y Formatos Estructurados
Los sistemas RAG extraen y usan información estructurada más fácilmente. Las tablas y listas son oro.
Por Qué las Tablas Funcionan
Las tablas comprimen información de formas fáciles de parsear programáticamente:
| Producto | Precio | Funciones | Mejor Para |
|---|---|---|---|
| HubSpot | $45/mes | CRM, Email | equipos pequeños |
| Salesforce | $75/mes | Suite completa | Enterprise |
| Pipedrive | $29/mes | Enfoque ventas | Startups |
Tipos de Contenido Estructurado
- Tablas de comparación (función vs. función, producto vs. producto)
- Tablas de precios con números claros
- Hojas de specs con detalles técnicos
- Tablas de timeline (cuándo, qué, quién)
- Formatos de checklist para procesos
- Listas de definición para terminología
Checklist de Optimización RAG
Estructura de Contenido
- [ ] Definición/claim clave en el primer párrafo
- [ ] Párrafos autocontenidos (sin "como mencionamos arriba")
- [ ] Patrón header-respuesta para todas las secciones H2/H3
- [ ] Resumen/conclusiones al final
- [ ] Breaks de sección cada 300-500 palabras
Densidad Semántica
- [ ] Eliminadas todas las frases de relleno
- [ ] Cada párrafo contiene al menos un dato específico
- [ ] Todos los claims están cuantificados donde sea posible
- [ ] Nombres de producto/servicio son explícitos (no "nuestra solución")
- [ ] Precios visibles y específicos
Datos Estructurados
- [ ] Al menos una tabla de comparación/datos por artículo
- [ ] Listas con viñetas para claims multi-punto
- [ ] Schema markup en la página
- [ ] Sección FAQ con FAQ schema
Midiendo el Rendimiento RAG
Pruebas Directas
- Pregunta a Perplexity tus consultas objetivo
- Nota si tu contenido es citado
- Rastrea frecuencia de citación en el tiempo
Indicadores Indirectos
| Métrica | Dónde Encontrar | Qué Buscar |
|---|---|---|
| AI Visibility Score | AICarma | Tasa de citación creciente |
| Uso de Fuentes | Módulo de Atribución de AICarma | Qué dominios influyen en recomendaciones |
| Featured Snippets | Google Search Console | Apariciones P0 |
| Referral desde dominios IA | Analytics | Referrers de perplexity.ai, chat.openai.com |
FAQ
¿RAG SEO es lo mismo que SEO tradicional?
No. El SEO tradicional te ayuda a ser encontrado por rastreadores y rankear para keywords. El RAG SEO ayuda a que tu contenido sea seleccionado por el LLM después de ser recuperado. Necesitas ambos: SEO para ser rastreado e indexado, optimización RAG para ser citado una vez recuperado.
¿La longitud del contenido importa para RAG?
Contraintuitivamente, más corto frecuentemente gana sobre más largo. El "relleno" perjudica el rendimiento RAG porque diluye la señal semántica de tus chunks. Una guía concisa de 800 palabras puede superar a un post extenso de 3,000 palabras.
¿Cómo pruebo si mi contenido es RAG-friendly?
Pega tu contenido en la ventana de contexto de ChatGPT y hazle preguntas específicas. Si la IA tiene dificultad para responder, tu estructura de contenido puede necesitar trabajo.
¿Debo dividir artículos largos en piezas más cortas?
Frecuentemente sí. Una serie de 5 artículos interenlazados de 1,000 palabras típicamente funciona mejor que una mega-guía de 5,000 palabras. Cada pieza más corta crea chunks más limpios. Usa enlaces internos para mantener la relación.
¿Cómo interactúa RAG con Schema Markup?
Schema Markup y optimización RAG son complementarios. Schema ayuda al rastreador a entender qué representa tu contenido. La optimización RAG asegura que tu contenido sea seleccionado para consultas relevantes. Usa ambos.