Die unendliche Schleife der KI-Sichtbarkeit: Ein 4-Schritte GEO-Optimierungszyklus
Letzte Aktualisierung: 15. August 2025
„Einrichten und vergessen" war kaum für SEO im Jahr 2010 zutreffend. Für GEO (Generative Engine Optimization) im Jahr 2026 ist es ein Todesurteil.
KI-Modelle aktualisieren sich wöchentlich — manchmal täglich. Retrieval-Architekturen verschieben sich ohne Vorwarnung. Die Trainingsdaten, die Ihre Marke in GPT-4 sichtbar machten, könnten in GPT-5 null Gewicht haben. Wenn Sie KI-Sichtbarkeit als Einmalprojekt behandeln — eine Checkliste, die Sie einmal durchgehen und abheften — bauen Sie auf Sand.
Die erfolgreichsten Marken, die wir bei AICarma verfolgen, teilen ein Merkmal: Sie behandeln GEO nicht als Projekt, sondern als Kreislauf — ein kontinuierliches Schwungrad, das mit jeder Umdrehung an Momentum gewinnt. Dieser Artikel zerlegt diesen Kreislauf in vier umsetzbare Phasen, untermauert durch Forschung und hart erarbeitete operationelle Daten.
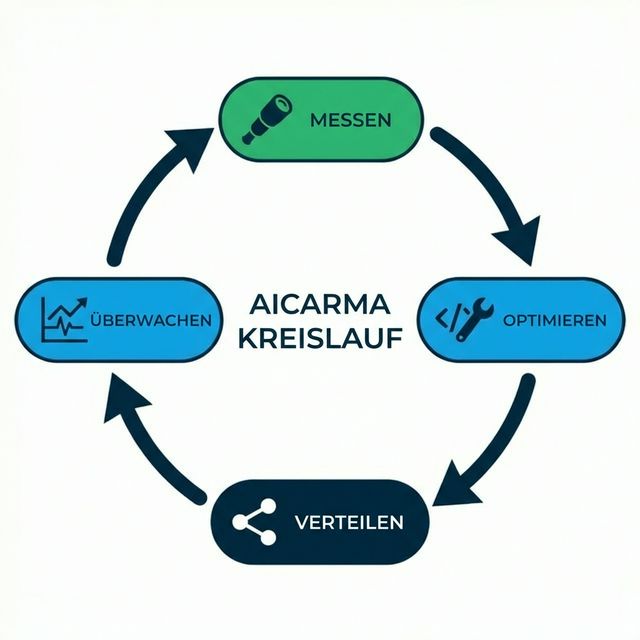
Inhaltsverzeichnis
- Warum lineare Optimierung scheitert
- Das 4-Schritte GEO-Schwungrad
- Schritt 1: Messen — Die Sonarphase
- Schritt 2: Engineeren — Die Strukturphase
- Schritt 3: Distribuieren — Die Signalphase
- Schritt 4: Monitoren — Die Pulsphase
- Zinseszinseffekte: Warum der Kreislauf beschleunigt
- Häufige Fehler, die den Kreislauf unterbrechen
- Das Schwungrad implementieren: Ein 30-Tage-Schnellstart
- FAQ
Warum lineare Optimierung scheitert
Traditionelles SEO-Denken folgt einem linearen Pfad: Audit → Fix → Ranken → Feiern. Es nimmt eine relativ stabile Umgebung an, in der Sie eine einmal verdiente Position behalten, bis ein Wettbewerber Sie überarbeitet oder ein Algorithmus-Update die Landschaft stört.
KI-Suche funktioniert nicht so. Forschung aus Stanfords Human-Centered AI Group hat dokumentiert, dass Large Language Models signifikanten temporalen Drift aufweisen — ihre Outputs verschieben sich messbar über die Zeit, selbst ohne explizites Retraining (Chen et al., „How is ChatGPT's behavior changing over time?," 2023). In praktischen Begriffen bedeutet das, dass eine Marke, die im März konsistent von GPT-4 zitiert wurde, bis Juni aus den Antworten verschwinden könnte — nicht weil die Marke etwas falsch gemacht hat, sondern weil sich die zugrundeliegenden Wahrscheinlichkeitsverteilungen verschoben haben.
Das schafft zwei unbequeme Realitäten:
- Es gibt keine „Ziellinie." Sie „erreichen" nie KI-Sichtbarkeit. Sie pflegen sie oder verlieren sie.
- Statische Strategien verfallen. Eine fixe Content-Bibliothek verliert in einem probabilistischen System schneller an Relevanz als in einem deterministischen.
Die Antwort ist nicht, härter zu arbeiten. Es ist, in Kreisläufen zu arbeiten.
Das 4-Schritte GEO-Schwungrad
Das Schwungrad besteht aus vier Phasen, die ineinander greifen: Messen → Engineeren → Distribuieren → Monitoren → (Wiederholen). Jede Phase generiert Daten, die die nächste schärfen. Über die Zeit wird der Zyklus schneller und präziser — wie ein Schwungrad, das Rotationsenergie gewinnt.
Lassen Sie uns jede Phase aufschlüsseln.
Schritt 1: Messen — Die Sonarphase
Sie können nicht optimieren, was Sie nicht sehen können. Und anders als bei Google, wo Sie Ihr Ranking mit einer einzigen Suche prüfen können, ist KI-Sichtbarkeit probabilistisch und multidimensional.
Was messen
| Dimension | Was es Ihnen verrät | Wie tracken |
|---|---|---|
| Sichtbarkeitsrate | % relevanter Prompts, in denen Sie erscheinen | Multi-Modell-Polling über ChatGPT, Claude, Gemini, Perplexity |
| Stimmung | Ob KI Sie positiv beschreibt | Natürliche Sprachanalyse der KI-Antworten |
| Zitierungsquellen | Woher KI über Sie „lernt" | Quellenzuordnung in RAG-basierten Systemen |
| Wettbewerberanteil | Wie Sie sich in Ihrer Kategorie vergleichen | Wettbewerbsanalyse-Dashboards |
Der Multi-Modell-Faktor
Eine kritische Erkenntnis aus unserer KI-Sichtbarkeits-Score-Forschung ist, dass die Sichtbarkeit dramatisch zwischen Modellen variiert. Sie könnten in 70% der Perplexity-Antworten erscheinen, aber nur in 20% der Claude-Antworten — weil jedes Modell verschiedene Quellen und Trainingsdaten gewichtet.
Einzelmodell-Messung erzeugt blinde Flecken. Systematische Befragung über Modelle hinweg — was wir Model Polling nennen — gibt Ihnen wahre Abdeckung. Forschung der University of Washington NLP Group bestätigt, dass verschiedene LLMs „minimale Überlappung in faktischen Abrufmustern" zeigen, was die Notwendigkeit von Cross-Modell-Monitoring unterstreicht (Sun et al., „Head-to-Tail: How Knowledgeable are Large Language Models?," 2023).
Eine Baseline etablieren
Bevor Sie etwas optimieren, führen Sie ein umfassendes Audit durch:
- 10+ Modelle mit 20-30 kategorierelevanten Prompts befragen
- Ihre Sichtbarkeitsrate, Stimmung und Positionsverteilung dokumentieren
- Die Performance Ihrer Wettbewerber bei denselben Prompts mappen
- Ihre stärksten und schwächsten Modelle identifizieren
Diese Baseline ist Ihr „Vorher"-Snapshot. Ohne sie können Sie später keinen ROI beweisen. Unser ROI-von-GEO-Leitfaden zeigt genau, wie Sie den Wert der Verbesserung dieser Metriken berechnen.
Schritt 2: Engineeren — Die Strukturphase
Sobald Sie die Lücken kennen, „schreiben Sie nicht einfach Content." Sie engineeren Informationsarchitektur, damit sie maschinenlesbar, abrufbar und eindeutig ist.
Technische Infrastruktur
Das Fundament besteht darin, Ihren Content für KI-Systeme zugänglich zu machen:
- llms.txt implementieren: Dieser aufkommende Standard erzeugt eine maschinenlesbare Karte Ihres Contents und sagt KI-Crawlern, was am wichtigsten ist.
- robots.txt für KI-Crawler optimieren: Sicherstellen, dass GPTBot, ClaudeBot und PerplexityBot auf Ihre kritischen Seiten zugreifen können.
- Schema-Markup einsetzen: Strukturierte Daten geben KI deterministische Fakten — Ihr Gründungsjahr, Ihre Preise, Ihre Kategorie — und reduzieren das Halluzinationsrisiko.
Content-Architektur
Content für KI-Retrieval zu engineeren erfordert das Verständnis, wie RAG-Systeme Information verarbeiten:
- Schlüsselaussagen voranstellen. LLMs zeigen einen „Primacy-Bias", dokumentiert in Liu et al.s „Lost in the Middle" (2023): Information am Anfang und Ende abgerufener Passagen bekommt mehr Aufmerksamkeit als Information in der Mitte.
- Dichte, faktische Prosa verwenden. KI-Zusammenfassung bevorzugt statistisch distinktive Sätze gegenüber generischem Füller. Quantitative Aussagen wie „reduziert Deployment-Zeit um 47%" werden eher zitiert als „verbessert die Effizienz erheblich."
- Für Kontextfenster optimieren. Strukturieren Sie Ihren Content so, dass jeder Abschnitt unabhängig wertvoll ist — weil RAG-Systeme oft Chunks abrufen, nicht ganze Seiten.
Entity-Engineering
Über Content hinaus müssen Sie Ihre Markenentität im Knowledge Graph engineeren. Forschung aus Googles eigenen Publikationen zeigt, dass Entity-Erkennung stark beeinflusst, wie Modelle Marken mit Kategorien assoziieren (Noy & Zhang, „The Entity Linking Problem"). Unser Entity-SEO-Leitfaden behandelt dies im Detail.
Schritt 3: Distribuieren — Die Signalphase
KI-Modelle lesen nicht nur Ihre Website. Sie lesen die Meinung des Internets über Ihre Website. Distribution dreht sich nicht nur um Traffic — es geht darum, Korroboration über mehrere autoritative Quellen zu schaffen.
Warum Korroboration zählt
Wenn ein LLM eine Behauptung auf einer einzigen Quelle findet, ist das Vertrauen moderat. Wenn es dieselbe Behauptung auf Ihrer Website, in G2-Bewertungen, Wikipedia-Referenzen, Reddit-Diskussionen und TechCrunch-Artikeln findet — schießt das Vertrauen in die Höhe.
Das ist das Prinzip der Multi-Quellen-Triangulation, und es ist fundamental dafür, wie LLMs Information bei der Generierung gewichten. Das Phänomen ist gut dokumentiert in der Knowledge-Graph-Literatur: Entitäten mit mehr „korroborierenden Triples" über Quellen hinweg erhalten höhere Vertrauens-Scores (Dong et al., „Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion," KDD 2014).
Hochimpakt-Distributionskanäle
| Kanal | KI-Gewicht | Strategie |
|---|---|---|
| Wikipedia | Sehr hoch | Sicherstellen, dass Ihre Marke einen genauen Wikipedia-Eintrag hat oder in relevanten Kategorieartikeln erwähnt wird |
| Hoch | Authentische Community-Präsenz aufbauen (Reddit-GEO-Strategie) | |
| Bewertungsplattformen | Hoch | G2, Capterra, Trustpilot — KI liebt strukturierte Bewertungen |
| Fachpresse | Hoch | Gastbeiträge in autoritativen Publikationen Ihrer Branche |
| Stack Overflow / Foren | Mittel | Technische Communities, in denen Ihr Produkt reale Probleme löst |
| Social Media | Niedrig-Mittel | Twitter/LinkedIn für Aktualitätssignale, nicht direkte KI-Zitierung |
Die Trainingsdaten-Pipeline
Distribution füttert auch das Long Game: Trainingsdaten-SEO. Der Content, den Sie heute distribuieren, könnte in Common Crawl landen, das die Trainingsdaten für zukünftige Modellversionen speist. Die Veröffentlichung eines gut zitierten Forschungsberichts 2025 könnte Ihre Marke permanent in GPT-6s Gewichte einbetten.
Schritt 4: Monitoren — Die Pulsphase
Der Kreislauf schließt sich mit kontinuierlichem Monitoring. Hat Ihr Engineering funktioniert? Hat die Distribution neue Zitierungen erzeugt? Hat ein Modellupdate Ihren Fortschritt gestört?
Was Monitoring erkennt
| Signal | Implikation | Reaktion |
|---|---|---|
| Sichtbarkeitseinbruch über alle Modelle | Technisches Problem (Crawling blockiert?) | Notfall-Audit von robots.txt und Website-Gesundheit |
| Sichtbarkeitseinbruch in einem Modell | Modellspezifisches Update | Prüfen, ob das Modell Retrieval-Quellen geändert hat |
| Stimmungswechsel negativ | Markenreputationsproblem | Aktuelle Presse, Bewertungen, Social-Erwähnungen prüfen |
| Wettbewerber-Sichtbarkeitsspike | Wettbewerber hat GEO-Zug gemacht | Wettbewerbsintelligenz-Analyse |
Die wöchentliche Kadenz
Wir empfehlen eine wöchentliche Review-Kadenz, nicht täglich. Wie wir in unserem Volatilitäts-Leitfaden dokumentiert haben, sind tägliche Schwankungen in KI-Outputs meist Rauschen. Wöchentliche Durchschnitte zeigen Signal.
Das wöchentliche Review sollte drei Fragen beantworten:
- Was hat sich verändert? (Sichtbarkeit, Stimmung, Zitierungen)
- Warum hat es sich verändert? (Modellupdate? Neuer Content? Wettbewerberzug?)
- Was machen wir als nächstes? (Engineeren? Distribuieren? Untersuchen?)
Diese letzte Frage führt direkt zurück zu Schritt 1: Messen — und schließt den Kreislauf.
Zinseszinseffekte: Warum der Kreislauf beschleunigt
Hier zeigt sich, warum die Schwungrad-Metapher zählt: Jede Umdrehung macht die nächste schneller.
Umdrehung 1: Sie messen von Grund auf, engineeren grundlegende Infrastruktur, distribuieren über offensichtliche Kanäle und etablieren Monitoring. Das erfordert erheblichen Aufwand.
Umdrehung 2: Ihre Messung ist jetzt vergleichend (Sie haben die Baseline des letzten Monats). Engineering ist gezielt (Sie wissen genau, welche Lücken zu füllen sind). Distribution ist strategisch (Sie wissen, welche Kanäle den Needle bewegt haben). Monitoring erkennt Anomalien schneller.
Umdrehung 5: Das System läuft praktisch von selbst. Monitoring alarmiert Sie am Dienstag über einen Sichtbarkeitseinbruch. Bis Mittwoch haben Sie die Ursache identifiziert (ein Modellupdate verschob die Quellengewichtung). Bis Donnerstag haben Sie einen Engineering-Fix deployed (Schema aktualisiert, Schlüsselseiten aufgefrischt). Bis Freitag distribuieren Sie den aktualisierten Content über hochgewichtete Kanäle.
Das ist der Zinseszinsvorteil, der Marken, die ihre KI-Präsenz besitzen, von denen trennt, die nur darauf reagieren.
Häufige Fehler, die den Kreislauf unterbrechen
Selbst gut gemeinte Teams unterbrechen das Schwungrad. Achten Sie auf diese Muster:
- Messung überspringen. Teams springen direkt zu „Content erstellen", ohne zu wissen, was tatsächlich funktioniert. Das ist Bauen im Dunkeln.
- Distribuieren ohne Engineering. Content auf Reddit und in der Presse zu pushen, ohne ihn erst für KI-Retrieval zu strukturieren, bedeutet, ein schlechtes Produkt schneller zu distribuieren.
- Monitoring ohne Handlungsbefugnis. Dashboards beobachten, ohne befugt zu sein zu handeln, verwandelt Monitoring in Frustration.
- Jährliche Kadenz. Den Kreislauf einmal im Jahr (oder vierteljährlich) durchzuführen, ist zu langsam. Die Modelle ändern sich schneller als Ihr Berichtszyklus.
Das Schwungrad implementieren: Ein 30-Tage-Schnellstart
| Woche | Phase | Aktionen |
|---|---|---|
| Woche 1 | Messen | Vollständiges Multi-Modell-Audit durchführen, Baselines etablieren, Wettbewerber mappen |
| Woche 2 | Engineeren | llms.txt implementieren, Schema optimieren, Top-5-Seiten für RAG umstrukturieren |
| Woche 3 | Distribuieren | 2 autoritative Content-Stücke veröffentlichen, Bewertungsprofile aktualisieren, in 3 Community-Threads beitragen |
| Woche 4 | Monitoren + Kreislauf | Wöchentliche Metriken reviewen, mit Woche-1-Baseline vergleichen, Umdrehung 2 planen |
Nach 30 Tagen haben Sie eine Baseline, einen ersten Optimierungszyklus abgeschlossen und ein klares Verständnis davon, welche Hebel Ihre Metriken bewegen.
FAQ
Wie lange dauert eine volle Umdrehung?
Für die meisten Teams dauert die erste Umdrehung 4-6 Wochen. Nachfolgende Umdrehungen können in 1-2 Wochen stattfinden, wenn Prozesse reifen und Messwerkzeuge kalibriert sind. Der Schlüssel ist nicht Geschwindigkeit, sondern Konsistenz — ein langsamer, stetiger Kreislauf schlägt gelegentliche Aktivitätsbursts.
Kann ich mit nur einer Phase beginnen?
Sie können, aber die Rendite wird begrenzt sein. Ohne Messung können Sie keinen Impact beweisen. Ohne Distribution bleibt Engineering unsichtbar. Die Phasen sind darauf ausgelegt, sich gegenseitig zu verstärken. Wenn Sie priorisieren müssen, beginnen Sie mit Messen — denn ohne Daten ist jede andere Entscheidung ein Ratespiel.
Wie unterscheidet sich das von traditionellen SEO-Zyklen?
Traditionelle SEO-Zyklen operieren auf einer monatlichen oder vierteljährlichen Kadenz in einer relativ stabilen Umgebung. Das GEO-Schwungrad operiert wöchentlich in einer volatilen, probabilistischen Umgebung. Der größte Unterschied ist, dass traditionelles SEO davon ausgeht, dass Ihre Position bestehen bleibt, bis sie verdrängt wird; GEO geht davon aus, dass Ihre Position verfällt, wenn sie nicht aktiv gepflegt wird.
Welche Tools brauche ich?
Mindestens: Multi-Modell-Polling-Fähigkeit, Content-Analytics und Wettbewerber-Tracking. Plattformen wie AICarma kombinieren diese in einem einzigen Dashboard mit automatisiertem Monitoring und wöchentlichen Digests — speziell für die Schwungrad-Kadenz gebaut.
Funktioniert das Schwungrad für kleine Unternehmen?
Absolut. Der Umfang skaliert herunter; die Prinzipien nicht. Ein lokales Restaurant kann das Schwungrad betreiben, indem es seine Sichtbarkeit bei „Beste Restaurants in meiner Nähe"-Anfragen monitort, sein Google-Unternehmensprofil und Menü-Content engineert, über Yelp und lokale Food-Blogs distribuiert und wöchentlich prüft.