Ja, Sie können für LLMs optimieren: Den 'Black Box'-Irrtum widerlegen
Letzte Aktualisierung: 20. August 2025
„KI ist nur Mathematik. Milliarden von Parametern. Eine Black Box. Man kann dafür kein SEO machen."
Wir hören diesen Mythos von klugen Leuten — Ingenieuren, Data Scientists, sogar Marketern, die stolz darauf sind, datengetrieben zu sein. Und oberflächlich klingt das vernünftig. Schließlich kommt ein neuronales Netzwerk mit 175 Milliarden Parametern nicht gerade mit einer Bedienungsanleitung.
Aber hier ist die Sache: Suche war auch eine „Black Box". Niemand außerhalb von Google kannte den genauen Algorithmus. Das hat eine ganze Branche nicht davon abgehalten, ihn zurückzuentwickeln und einen 68 Milliarden Dollar schweren SEO-Markt aufzubauen. Das Prinzip hat sich nicht geändert — nur die Box.
KI ist nicht zufällig. Sie ist probabilistisch. Und probabilistische Systeme können per Definition beeinflusst werden. Wenn Sie die Variablen verstehen, die die Wahrscheinlichkeitsverteilung formen, können Sie die Chancen zu Ihren Gunsten verschieben.
Dieser Artikel zerlegt den Black-Box-Mythos Stück für Stück — mit Forschungszitierungen, nicht mit Spekulation — und gibt Ihnen das Framework, um klar über KI-Optimierung nachzudenken.
Inhaltsverzeichnis
- Der Ursprung des Mythos
- Probabilistisch ≠ Zufällig: Die kritische Unterscheidung
- Die drei Ebenen, die Sie beeinflussen können
- Ebene 1: Trainingsdaten — Das Langzeitgedächtnis
- Ebene 2: RAG-Kontext — Das Kurzzeitgedächtnis
- Ebene 3: Systemarchitektur — Die Persönlichkeit
- Der Beweis: Optimierung funktioniert
- Was Optimierung NICHT bedeutet
- Von der Theorie zur Praxis: Die AICarma-Methodik
- FAQ
Der Ursprung des Mythos
Der „Nicht-Optimierbarkeits"-Mythos entsteht aus einem fundamentalen Missverständnis dessen, wofür wir optimieren.
Kritiker beobachten korrekt, dass man die exakten Token, die ein LLM generiert, nicht vorhersagen kann. Das stimmt. LLMs verwenden Nucleus Sampling (Holtzman et al., „The Curious Case of Neural Text Degeneration", ICLR 2020), das kontrollierte Zufälligkeit in die Textgenerierung einführt. Derselbe Prompt kann bei aufeinanderfolgenden Durchläufen unterschiedliche Ausgaben produzieren.
Aber diese Kritik verwechselt Token-Level-Vorhersage mit Verteilungsebene-Beeinflussung. Sie müssen nicht den exakten Satz vorhersagen, den ein LLM schreiben wird. Sie müssen die Wahrscheinlichkeit erhöhen, dass Ihre Marke in der Verteilung wahrscheinlicher Ausgaben für einen gegebenen Prompt erscheint.
Betrachten Sie die Analogie mit dem Wetter. Sie können nicht die exakte Temperatur um 15:47 Uhr nächsten Dienstag vorhersagen. Aber Sie können mit hoher Sicherheit sagen, dass der Juli wärmer sein wird als der Januar. Das System hat Varianz, aber es hat Struktur — und diese Struktur kann analysiert und genutzt werden.
Probabilistisch ≠ Zufällig: Die kritische Unterscheidung
Diese Unterscheidung ist so wichtig, dass sie einen eigenen Abschnitt verdient.
Zufällig bedeutet, jedes Ergebnis ist gleich wahrscheinlich. Werfen Sie einen fairen Würfel: Jede Seite hat eine 1/6-Chance. Keine Strategie kann das ändern.
Probabilistisch bedeutet, Ergebnisse haben unterschiedliche Wahrscheinlichkeiten basierend auf Bedingungen. Poker ist probabilistisch. Die Karten werden zufällig verteilt, aber die besten Spieler gewinnen konsistent, weil sie Wahrscheinlichkeiten verstehen und den Informationsfluss managen.
LLMs sind auf eine sehr strukturierte Weise probabilistisch. Bei der Textgenerierung berechnet das Modell eine Wahrscheinlichkeit für jedes mögliche nächste Token (Wortfragment). Das Token „Salesforce" könnte eine 23%ige Wahrscheinlichkeit haben nach dem Prompt „das beste CRM ist...", während „Monday" eine 4%ige Wahrscheinlichkeit hat.
Diese Wahrscheinlichkeiten sind nicht zufällig. Sie werden geformt durch:
- Was das Modell während des Trainings gelernt hat (Trainingsdaten)
- Welche Informationen in Echtzeit abgerufen wurden (RAG-Kontext)
- Welche Anweisungen das System steuern (System-Prompts und Sicherheitsfilter)
Jede dieser Ebenen kann beeinflusst werden. Schauen wir uns an, wie.
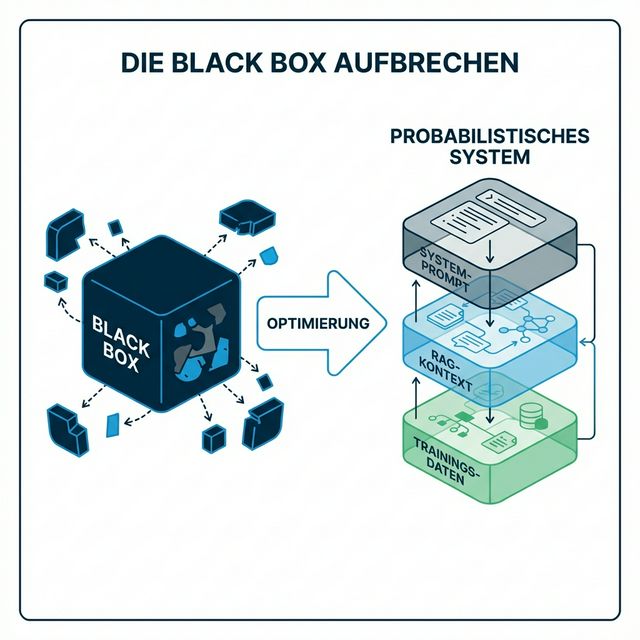
Die drei Ebenen, die Sie beeinflussen können
Denken Sie an moderne KI-Suche als dreischichtigen Stack. Jede Ebene arbeitet unabhängig, aber sie kombinieren sich zur endgültigen Ausgabe. Optimierung bedeutet, alle drei Ebenen gleichzeitig zu bearbeiten.
Ebene 1: Trainingsdaten — Das Langzeitgedächtnis
Was es ist: Der riesige Textkorpus, den das Modell während des Pre-Trainings aufgenommen hat. Für GPT-4 umfasst dies Bücher, Websites, Code, akademische Arbeiten, Wikipedia, Reddit und mehr — Hunderte Milliarden Token.
Warum es wichtig ist: Trainingsdaten formen die „Standardüberzeugungen" des Modells. Wenn Ihre Marke häufig und positiv in hochwertigen Trainingsquellen erscheint, entwickelt das Modell eine starke Vorab-Assoziation zwischen Ihrer Marke und Ihrer Kategorie.
Die Wissenschaft: Carlini et al. zeigten in „Quantifying Memorization Across Neural Language Models" (2022), dass LLMs Trainingsdaten in Raten memorieren und reproduzieren, die proportional zur Datenhäufigkeit und -unterscheidbarkeit sind. Marken, die häufiger in Trainingskorpora erscheinen, werden wahrscheinlicher während der Inferenz generiert.
Ihre Einflussstrategie: Trainingsdaten-SEO. Sie können GPT-4s Trainingsdaten nicht rückwirkend ändern — sie sind eingefroren. Aber Sie können beeinflussen, was in GPT-5s Training eingeht, indem Sie sicherstellen, dass Ihre Marke heute in hochgewichteten Quellen präsent ist:
- Wikipedia: Die einzelne höchstgewichtete Quelle in den meisten Trainingskorpora
- Common Crawl: Das Rückgrat der Web-Trainingsdaten (dokumentiert vom Allen Institute)
- Reddit: Massiv überrepräsentiert in neueren Trainingsdatensätzen. Unsere Reddit GEO-Strategie behandelt dies im Detail
- Akademische Publikationen: Zitierte Inhalte werden durch akademische Indexierungs-Pipelines verstärkt
Das ist das langfristige Spiel. Änderungen an Trainingsdaten brauchen Monate, um sich zu manifestieren — typischerweise wenn eine neue Modellversion veröffentlicht wird. Aber der Impact ist grundlegend und dauerhaft.
Ebene 2: RAG-Kontext — Das Kurzzeitgedächtnis
Was es ist: Retrieval-Augmented Generation. Wenn Sie Perplexity eine Frage stellen, durchsucht es das Web in Echtzeit, ruft relevante Passagen ab und verwendet sie als Kontext für die Generierung seiner Antwort. Googles AI Overviews, Bing Chat und sogar ChatGPTs Browsing-Modus funktionieren ähnlich.
Warum es wichtig ist: RAG ist die Verbindung der KI zu aktuellen Informationen. Ihre SEO-Rankings, Ihre Content-Struktur und Ihre technische Zugänglichkeit beeinflussen direkt, ob das Retrieval-System Ihre Inhalte in das Kontextfenster des Modells zieht.
Die Wissenschaft: Die wegweisende RAG-Arbeit von Lewis et al. („Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", NeurIPS 2020) zeigte, dass retrieval-augmentierte Modelle Dokumente stark bevorzugen, die sowohl bei Relevanz als auch bei Abrufbarkeit gut abschneiden. Kritischerweise zeigten Liu et al. später in „Lost in the Middle" (2023), dass die Position innerhalb des abgerufenen Kontexts wichtig ist — Modelle schenken Informationen am Anfang und Ende des abgerufenen Sets mehr Aufmerksamkeit.
Ihre Einflussstrategie: RAG-SEO-Optimierung und Kontextfenster-Optimierung. Schlüsseltaktiken:
- Semantische Dichte: Schreiben Sie Inhalte, die maximale Bedeutung in minimale Token packen — dies erhöht die Retrieval-Relevanz-Scores
- Wertversprechen voranstellen: Platzieren Sie Ihre wichtigsten Aussagen in den ersten 100 Wörtern jedes Seitenabschnitts
- Für Chunking strukturieren: Verwenden Sie klare H2/H3-Überschriften, damit Retrieval-Systeme fokussierte, eigenständige Passagen extrahieren können
- Schema-Markup implementieren: Geben Sie KI deterministische Fakten und reduzieren Sie die Notwendigkeit des Modells, zu schlussfolgern oder zu halluzinieren
Anders als Trainingsdaten erzeugt RAG-Optimierung schnelle Ergebnisse. Ändern Sie Ihre Inhalte heute, und Perplexity könnte Sie morgen anders zitieren.
Ebene 3: Systemarchitektur — Die Persönlichkeit
Was es ist: Die verborgenen Anweisungen und Leitplanken, die formen, wie KI-Produkte sich verhalten. System-Prompts sagen ChatGPT, es solle „hilfreich sein", „autoritative Quellen priorisieren", „medizinische Ratschläge ohne Haftungsausschluss vermeiden". Sicherheitsfilter unterdrücken bestimmte Ausgaben. Produktebene-Entscheidungen (wie ob im Web gesucht oder auf Trainingsdaten vertraut wird) beeinflussen, was das Modell „sieht".
Warum es wichtig ist: Selbst wenn Sie in den Trainingsdaten sind und perfekt für Retrieval optimiert sind, kann die Systemarchitektur Ihre Präsenz unterdrücken oder verstärken. Wenn ChatGPTs System-Prompt sagt „priorisiere etablierte medizinische Institutionen für Gesundheitsanfragen" und Sie ein Startup-Gesundheitsblog sind — werden Ihre Inhalte ungeachtet der Qualität herabgestuft.
Die Wissenschaft: OpenAIs eigene Forschung zu „Behavior of Large Language Models as System Prompt Consumers" (2023) zeigt, dass System-Prompts die Ausgabeverteilungen signifikant beeinflussen, einschließlich Quellenpräferenzen und Autoritätsgewichtung.
Ihre Einflussstrategie: Sich an die Ziele des Systems anpassen. Das bedeutet:
- Autoritätssignale aufbauen: Für YMYL-Inhalte (Your Money or Your Life) ist Autorität keine Option — sie ist der Torwächter
- Entity-Präsenz etablieren: Marken mit klaren, strukturierten Entity-Daten werden vom System als „bekannte" Entitäten behandelt
- Zitierungen verdienen: Von anderen autoritativen Quellen zitiert zu werden, schafft eine Vertrauenskaskade, die mit systemebene Sicherheitspräferenzen übereinstimmt
Diese Ebene ist am schwierigsten direkt zu optimieren, belohnt aber langfristigen Markenaufbau gegenüber kurzfristigen Taktiken.
Der Beweis: Optimierung funktioniert
Wenn Sie immer noch skeptisch sind, betrachten Sie die empirischen Belege.
Eine Meilensteinstudie von Georgia Tech, IIT Delhi und anderen (Aggarwal et al., „GEO: Generative Engine Optimization", 2024) testete spezifische Optimierungsstrategien an generativen Engines und fand:
| Strategie | Sichtbarkeitsverbesserung |
|---|---|
| Zitierungen zu Aussagen hinzufügen | +30-40% |
| Relevante Statistiken einbeziehen | +20-30% |
| Autoritative Fachsprache verwenden | +15-25% |
| Mit klaren Zitaten strukturieren | +10-20% |
Das sind messbare, reproduzierbare Verbesserungen. Nicht theoretisch. Nicht anekdotisch. Wissenschaftlich validiert.
Unsere eigenen Daten über 1.000+ AICarma-Markenmonitors bestätigen diese Ergebnisse. Marken, die systematisches GEO implementieren — über alle drei Ebenen — sehen eine durchschnittliche 35%ige Verbesserung ihres KI-Sichtbarkeits-Scores innerhalb von 90 Tagen.
Was Optimierung NICHT bedeutet
Lassen Sie uns klar über Grenzen sein. Optimierung ist keine Manipulation:
- Sie können nicht garantieren, dass ChatGPT sagt „Marke X ist die beste." Sie können die Wahrscheinlichkeit erhöhen.
- Sie können das Modell nicht „hacken" mit Prompt-Injection oder adversarialen Techniken. Diese werden erkannt und bestraft.
- Sie können Temperatur-Einstellungen nicht kontrollieren. Wenn das Modell mit hoher Temperatur läuft, werden Ausgaben variabler, ungeachtet Ihrer Optimierung.
- Sie können keine falschen Aussagen durchsetzen. LLMs gleichen Quellen ab. Unbelegte Behauptungen werden gefiltert oder halluzinations-geprüft.
Optimierung bedeutet, KI-Systemen die hochwertigsten, am besten strukturierten, am meisten bestätigten Informationen über Ihre Marke zu liefern — damit wenn das Modell eine Antwort generiert, der Weg des geringsten Widerstands durch Ihre Inhalte führt.
Von der Theorie zur Praxis: Die AICarma-Methodik
Die drei Ebenen zu verstehen ist die Theorie. Sie zu operationalisieren erfordert Methodik:
- Messen Sie Ihren aktuellen Zustand über alle drei Ebenen mit Multi-Modell-Monitoring
- Identifizieren Sie, welche Ebene Ihre schwächste ist (Trainingsdaten? RAG? Autorität?)
- Priorisieren Sie Optimierungen nach Ebene — RAG für schnelle Gewinne, Trainingsdaten für langfristiges Compounding, Autorität für Nachhaltigkeit
- Ausführen unter Verwendung des GEO-Kreislaufs zur Aufrechterhaltung kontinuierlicher Verbesserung
- Verfolgen Sie Ergebnisse gegen Ihre Wettbewerbs-Benchmarks, um den relativen Fortschritt zu messen
Die Black Box ist gar nicht so schwarz, wenn Sie ihre Architektur verstehen. Und die Marken, die diese Wahrheit am frühesten verinnerlichen, werden ihren Vorteil über Jahre akkumulieren.
FAQ
Wenn KI optimierbar ist, warum machen das nicht mehr Leute?
Weil das Feld neu ist. SEO brauchte 10 Jahre, um sich von „Keywords in Meta-Tags stopfen" zu einer ausgereiften Disziplin zu entwickeln. GEO ist im zweiten Jahr. Die Vorreiter — genau wie die frühen SEOs — werden überproportionale Belohnungen ernten, bevor der Markt überfüllt wird.
Bedeutet Optimierung für KI nicht einfach „gutes SEO machen"?
Teilweise, aber nicht vollständig. Gutes SEO hilft bei Ebene 2 (RAG-Retrieval). Aber es adressiert nicht Ebene 1 (Trainingsdaten-Präsenz) oder Ebene 3 (Systemebene-Autoritätsanpassung). GEO ist eine Obermenge von SEO, kein Synonym.
Werden KI-Unternehmen Optimierung verhindern?
Sie haben SEO in 25 Jahren nicht verhindert. KI-Unternehmen wollen, dass hochwertige, autoritative Inhalte erscheinen — es macht ihre Produkte besser. Was sie nicht wollen, ist Manipulation und Spam. Legitime Optimierung, die die Inhaltsqualität verbessert, ist mit ihren Anreizen abgestimmt.
Wie messe ich, ob Optimierung funktioniert?
Verfolgen Sie Ihren KI-Sichtbarkeits-Score im Zeitverlauf. Aussagekräftige Verbesserungen zeigen sich in 4-8 Wochen für RAG-Optimierung und 3-6 Monaten für Trainingsdaten-Effekte. Verwenden Sie Wettbewerbsbenchmarking, um Ihre Gewinne von allgemeinen Marktverschieibungen zu trennen.