Sim, Você Pode Otimizar para LLMs: Quebrando a Falácia da 'Caixa Preta'
Última atualização: 20 August 2025
"IA é só matemática. Bilhões de parâmetros. Uma caixa preta. Você não pode fazer SEO nela."
Ouvimos esse mito de pessoas inteligentes — engenheiros, cientistas de dados, até profissionais de marketing que se orgulham de serem orientados por dados. E na superfície, parece razoável. Afinal, uma rede neural com 175 bilhões de parâmetros não vem exatamente com manual de instruções.
Mas eis a questão: busca também era uma "caixa preta." Ninguém fora do Google conhecia o algoritmo exato. Isso não impediu uma indústria inteira de fazer engenharia reversa e construir um mercado de SEO de US$ 68 bilhões. O princípio não mudou — apenas a caixa mudou.
IA não é aleatória. Ela é probabilística. E sistemas probabilísticos, por definição, podem ser influenciados. Se você entende as variáveis que moldam a distribuição de probabilidade, pode alterar as chances a seu favor.
Este artigo desmonta o mito da caixa preta peça por peça — com citações de pesquisa, não achismo — e dá a você o framework para pensar claramente sobre otimização para IA.
Índice
- A Origem do Mito
- Probabilístico ≠ Aleatório: A Distinção Crítica
- As Três Camadas Que Você Pode Influenciar
- Camada 1: Dados de Treinamento — A Memória de Longo Prazo
- Camada 2: Contexto RAG — A Memória de Curto Prazo
- Camada 3: Arquitetura do Sistema — A Personalidade
- A Evidência: Otimização Funciona
- O Que Otimização NÃO Significa
- Da Teoria à Prática: A Metodologia AICarma
- FAQ
A Origem do Mito
O mito da "impossibilidade de otimização" vem de um mal-entendido fundamental sobre o que estamos otimizando.
Críticos observam corretamente que você não pode prever os tokens exatos que um LLM vai gerar. Isso é verdade. LLMs usam amostragem por núcleo (Holtzman et al., "The Curious Case of Neural Text Degeneration," ICLR 2020), que introduz aleatoriedade controlada na geração de texto. O mesmo prompt pode produzir saídas diferentes em execuções consecutivas.
Mas essa crítica confunde previsão no nível de token com influência no nível de distribuição. Você não precisa prever a frase exata que um LLM vai escrever. Você precisa aumentar a probabilidade de que sua marca apareça na distribuição de saídas prováveis para um dado prompt.
Considere a analogia com o clima. Você não pode prever a temperatura exata às 15:47 na terça-feira que vem. Mas pode dizer com alta confiança que julho será mais quente que janeiro. O sistema tem variância, mas tem estrutura — e essa estrutura pode ser analisada e aproveitada.
Probabilístico ≠ Aleatório: A Distinção Crítica
Esta distinção é tão importante que merece sua própria seção.
Aleatório significa que todo resultado é igualmente provável. Lance um dado justo: cada face tem 1/6 de chance. Nenhuma estratégia pode mudar isso.
Probabilístico significa que resultados têm diferentes probabilidades baseadas em condições. Poker é probabilístico. As cartas são distribuídas aleatoriamente, mas os melhores jogadores vencem consistentemente porque entendem probabilidade e gerenciam fluxo de informação.
LLMs são probabilísticos de forma muito estruturada. Ao gerar texto, o modelo calcula probabilidade para cada possível próximo token (fragmento de palavra). O token "Salesforce" pode ter 23% de probabilidade após o prompt "o melhor CRM é..." enquanto "Monday" tem 4%.
Essas probabilidades não são aleatórias. Elas são moldadas por:
- O que o modelo aprendeu durante o treinamento (dados de treinamento)
- Que informação foi recuperada em tempo real (contexto RAG)
- Que instruções governam o sistema (system prompts e filtros de segurança)
Cada uma dessas camadas pode ser influenciada. Vamos examinar como.
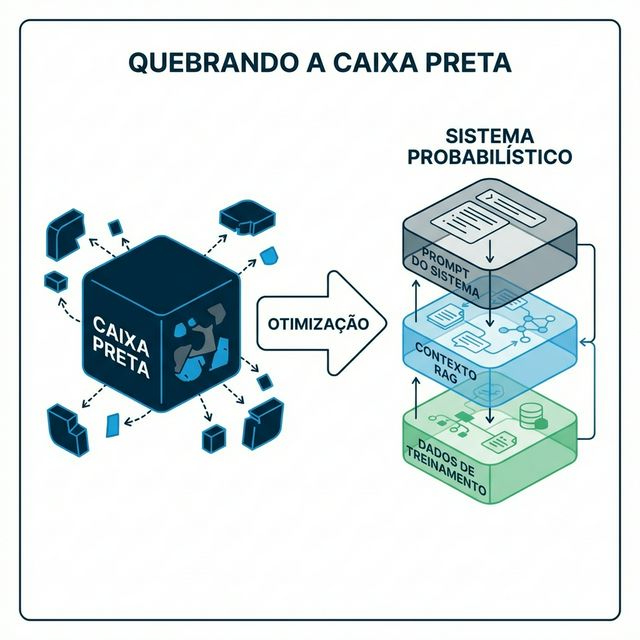
As Três Camadas Que Você Pode Influenciar
Pense na busca moderna por IA como uma pilha de três camadas. Cada camada opera independentemente, mas se combinam para produzir o resultado final. Otimização significa trabalhar todas as três camadas simultaneamente.
Camada 1: Dados de Treinamento — A Memória de Longo Prazo
O que é: O vasto corpus de texto que o modelo ingeriu durante pré-treinamento. Para o GPT-4, isso inclui livros, sites, código, artigos acadêmicos, Wikipedia, Reddit e mais — centenas de bilhões de tokens.
Por que importa: Dados de treinamento criam as "crenças padrão" do modelo. Se sua marca aparece frequentemente e positivamente em fontes de treinamento de alta qualidade, o modelo desenvolve forte associação prévia entre sua marca e sua categoria.
A ciência: Carlini et al. demonstraram em "Quantifying Memorization Across Neural Language Models" (2022) que LLMs memorizam e reproduzem dados de treinamento em taxas proporcionais à frequência e distinção dos dados. Marcas que aparecem mais frequentemente nos corpora de treinamento têm maior probabilidade de serem geradas durante inferência.
Sua estratégia de influência: SEO de Dados de Treinamento. Você não pode alterar os dados de treinamento do GPT-4 retroativamente — estão congelados. Mas pode influenciar o que entra no GPT-5 garantindo presença da sua marca em fontes de alto peso hoje:
- Wikipedia: A fonte de maior peso na maioria dos corpora de treinamento
- Common Crawl: A espinha dorsal dos dados de treinamento web
- Reddit: Massivamente super-representado em conjuntos recentes de treinamento. Nossa Estratégia Reddit para GEO cobre isso em detalhe
- Publicações acadêmicas: Conteúdo citado é reforçado através de pipelines de indexação acadêmica
Este é o jogo de longo prazo. Mudanças nos dados de treinamento levam meses para se manifestar. Mas o impacto é fundamental e persistente.
Camada 2: Contexto RAG — A Memória de Curto Prazo
O que é: Geração Aumentada por Recuperação. Quando você pergunta algo ao Perplexity, ele busca na web em tempo real, recupera passagens relevantes e as usa como contexto para gerar a resposta. AI Overviews do Google, Bing Chat e até o modo de navegação do ChatGPT funcionam de forma similar.
Por que importa: RAG é como a IA se conecta a informação atual. Seus rankings de SEO, estrutura de conteúdo e acessibilidade técnica afetam diretamente se o sistema de recuperação puxa seu conteúdo para a janela de contexto do modelo.
A ciência: O paper seminal de RAG por Lewis et al. ("Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS 2020) mostrou que modelos augmentados por recuperação favorecem fortemente documentos que pontuam bem tanto em relevância quanto em recuperabilidade. Criticamente, Liu et al. demonstraram posteriormente em "Lost in the Middle" (2023) que posição dentro do contexto recuperado importa — modelos prestam mais atenção à informação no início e fim do conjunto recuperado.
Sua estratégia de influência: Otimização RAG-SEO e Otimização de Janela de Contexto. Táticas-chave:
- Densidade semântica: Escreva conteúdo que empacota máximo significado em mínimos tokens
- Carregue propostas de valor no início: Coloque suas claims mais importantes nas primeiras 100 palavras de cada seção
- Estruture para chunking: Use cabeçalhos H2/H3 claros para que sistemas de recuperação possam extrair passagens focadas
- Implemente Schema Markup: Dê à IA fatos determinísticos, reduzindo a necessidade do modelo inferir ou alucinar
Diferente de dados de treinamento, otimização RAG produz resultados rápidos. Mude seu conteúdo hoje, e o Perplexity pode citá-lo diferente amanhã.
Camada 3: Arquitetura do Sistema — A Personalidade
O que é: As instruções ocultas e guardrails que moldam como produtos de IA se comportam. System prompts dizem ao ChatGPT para "ser útil," para "priorizar fontes autoritativas," para "evitar aconselhamento médico sem disclaimers." Filtros de segurança suprimem certas saídas. Decisões de produto afetam o que o modelo "vê."
Por que importa: Mesmo se você está nos dados de treinamento e perfeitamente otimizado para recuperação, a arquitetura do sistema pode suprimir ou amplificar sua presença. Se o system prompt do ChatGPT diz "priorize instituições médicas estabelecidas para consultas de saúde," e você é um blog de saúde startup — seu conteúdo é despriorizadoindependente da qualidade.
A ciência: A própria pesquisa da OpenAI sobre "Behavior of Large Language Models as System Prompt Consumers" (2023) demonstra que system prompts afetam significativamente distribuições de saída, incluindo preferências de fonte e ponderação de autoridade.
Sua estratégia de influência: Alinhe-se com os objetivos do sistema:
- Construa sinais de autoridade: Para conteúdo YMYL (Seu Dinheiro, Sua Vida), autoridade não é opcional — é o porteiro
- Estabeleça presença de Entidade: Marcas com dados de entidade claros e estruturados são tratadas como entidades "conhecidas" pelo sistema
- Conquiste citações: Ser citado por outras fontes autoritativas cria uma cascata de confiança que se alinha com preferências de segurança do sistema
Esta camada é a mais difícil de otimizar diretamente, mas recompensa construção de marca de longo prazo sobre táticas de curto prazo.
A Evidência: Otimização Funciona
Se você ainda é cético, considere a evidência empírica.
Um estudo marcante da Georgia Tech, IIT Delhi e outros (Aggarwal et al., "GEO: Generative Engine Optimization," 2024) testou estratégias específicas de otimização em motores generativos e encontrou:
| Estratégia | Melhoria na Visibilidade |
|---|---|
| Adicionar citações às claims | +30-40% |
| Incluir estatísticas relevantes | +20-30% |
| Usar linguagem técnica autoritativa | +15-25% |
| Estruturar com citações claras | +10-20% |
Essas são melhorias mensuráveis e reproduzíveis. Não teóricas. Não anedóticas. Cientificamente validadas.
Nossos próprios dados em 1.000+ monitores de marca do AICarma corroboram esses resultados. Marcas que implementam GEO sistemático — através de todas as três camadas — veem melhoria média de 35% no Score de Visibilidade IA em 90 dias.
O Que Otimização NÃO Significa
Vamos ser claros sobre limites. Otimização não é manipulação:
- Você não pode garantir que ChatGPT diga "Marca X é a melhor." Você pode aumentar a probabilidade.
- Você não pode "hackear" o modelo com injeção de prompt ou técnicas adversariais. Essas são detectadas e penalizadas.
- Você não pode controlar configurações de temperature. Se o modelo está rodando com alta temperature, saídas serão mais variadas independente da otimização.
- Você não pode fazer claims falsas colarem. LLMs cruzam referências de fontes. Claims sem fundamento são filtradas ou verificadas contra alucinação.
Otimização significa fornecer aos sistemas de IA a informação de mais alta qualidade, mais estruturada e mais corroborada sobre sua marca — para que quando o modelo gerar uma resposta, o caminho de menor resistência passe pelo seu conteúdo.
Da Teoria à Prática: A Metodologia AICarma
Entender as três camadas é a teoria. Operacionalizar requer metodologia:
- Meça seu estado atual em todas as três camadas usando monitoramento multi-modelo
- Identifique qual camada é seu ponto fraco (Dados de Treinamento? RAG? Autoridade?)
- Priorize otimizações por camada — RAG para vitórias rápidas, Dados de Treinamento para composição de longo prazo, Autoridade para sustentabilidade
- Execute usando o GEO Flywheel para manter melhoria contínua
- Rastreie resultados contra seus benchmarks competitivos para medir progresso relativo
A caixa preta não é tão preta quando você entende sua arquitetura. E as marcas que internalizarem essa verdade mais cedo vão acumular vantagem por anos.
FAQ
Se IA é otimizável, por que não vemos mais pessoas fazendo isso?
Porque o campo é novo. SEO levou 10 anos para amadurecer de "enfiar palavras-chave em meta tags" para disciplina sofisticada. GEO está no ano dois. Os early movers — assim como os primeiros SEOs — vão colher recompensas desproporcionais antes do mercado ficar congestionado.
Otimizar para IA não é apenas "fazer bom SEO"?
Parcialmente, mas não inteiramente. Bom SEO ajuda com a Camada 2 (recuperação RAG). Mas não endereça a Camada 1 (presença nos dados de treinamento) ou a Camada 3 (alinhamento de autoridade no nível do sistema). GEO é um superconjunto do SEO, não sinônimo.
Empresas de IA não vão impedir a otimização?
Elas não impediram o SEO em 25 anos. Empresas de IA querem que conteúdo de alta qualidade e autoritativo apareça — isso torna seus produtos melhores. O que elas não querem é manipulação e spam. Otimização legítima que melhora a qualidade do conteúdo está alinhada com seus incentivos.
Como medir se a otimização está funcionando?
Rastreie seu Score de Visibilidade IA ao longo do tempo. Melhoria significativa aparece em 4-8 semanas para otimização RAG e 3-6 meses para efeitos de dados de treinamento. Use benchmarking competitivo para separar seus ganhos de mudanças gerais do mercado.