Model Polling: Como Respondentes Sintéticos Estão Substituindo Grupos Focais
Última atualização: 2 November 2025
E se você pudesse conduzir um grupo focal com 10.000 participantes — cada um representando perfil demográfico distinto — e ter resultados em horas em vez de meses? E se esses participantes nunca experimentassem fadiga, nunca tentassem agradar o moderador e sempre respondessem honestamente sobre tópicos sensíveis?
Isso não é um experimento mental. Está acontecendo agora em departamentos de pesquisa enterprise no mundo todo, e se chama Model Polling.
Índice
- O Conceito de Respondentes Sintéticos
- Como LLMs Se Tornam Participantes de Grupo Focal
- A Vantagem Multi-Modelo
- Integração de Dados em Tempo Real: A Arquitetura RAG
- Precisão e Validação
- Arquitetura Técnica para Enterprise
- FAQ
O Conceito de Respondentes Sintéticos
Pesquisa de mercado tradicional opera sobre premissa fundamental: para entender consumidores, você deve perguntar a consumidores. Essa premissa impulsionou uma indústria multibilionária de painéis, pesquisas e grupos focais.
Model Polling desafia esse paradigma com premissa revolucionária: Large Language Models treinados em toda a internet pública contêm um modelo comprimido da própria sociedade humana.
Quando um LLM como GPT-4 ou Claude gera texto, ele se baseia em padrões aprendidos de bilhões de documentos escritos por humanos — discussões em fóruns, avaliações de produtos, posts em redes sociais, artigos acadêmicos. Em sentido significativo, esses modelos "leram" mais opiniões de consumidores do que qualquer pesquisador humano poderia absorver em mil vidas.
Personas Sintéticas na Prática
Em vez de recrutar 500 pessoas e pagá-las para completar pesquisas, empresas enterprise agora criam personas sintéticas. Usando system prompts especializados, um único modelo pode simular perfis demográficos e psicográficos diversos:
Exemplo de prompt:
"Você é um pai suburbano de 42 anos com três filhos, renda familiar R$30.000/mês, preocupado com segurança veicular e eficiência de combustível. Dirige um Honda CR-V 2019 e está considerando sua próxima compra. Responda como essa pessoa ao seguinte..."
O mesmo modelo pode imediatamente se tornar:
"Você é um profissional urbano de 23 anos, ambientalmente consciente, sem carro por escolha mas considerando primeiro veículo para viagens de fim de semana..."
Em minutos, pesquisadores podem simular milhares dessas personas, cada uma respondendo as mesmas perguntas de sua perspectiva única.
Como LLMs Se Tornam Participantes de Grupo Focal
A abordagem de respondente sintético oferece vantagens fundamentais:
| Dimensão | Grupo Focal Tradicional | Respondentes Sintéticos |
|---|---|---|
| Tempo até insights | 6-10 semanas | Horas |
| Custo por respondente | R$250-1.000 | <R$0,50 |
| Limites de amostra | Restritos por logística | Ilimitados |
| Efeito observador | Presente | Ausente |
| Viés de desejabilidade social | Significativo | Eliminado |
| Honestidade em tópicos sensíveis | Variável | Consistente |
| Escalabilidade | Custo linear | Custo marginal quase zero |
O Fator de Eliminação de Viés
Respondentes humanos trazem vieses inevitáveis a ambientes de pesquisa. Tentam parecer consistentes. Querem agradar entrevistadores. São influenciados pelo que outros na sala dizem. Modificam respostas sobre tópicos sensíveis como finanças, saúde ou preferências controversas.
Respondentes sintéticos não têm nenhuma dessas restrições. Um modelo simulando eleitor conservador e eleitor progressista dará respostas genuinamente diferentes — não performáticas para sinalizar pertencimento a grupo.
Taxas de Satisfação
Pesquisas de adotantes enterprise mostram 87% de satisfação entre equipes usando dados sintéticos, com muitas reportando alta correlação entre previsões sintéticas e comportamento real de mercado.
A Vantagem Multi-Modelo
Adotantes iniciais rapidamente descobriram que depender de um único LLM criava pontos cegos. Cada modelo tem dados de treinamento diferentes, vieses diferentes e padrões de resposta diferentes. A solução: polling multi-modelo.
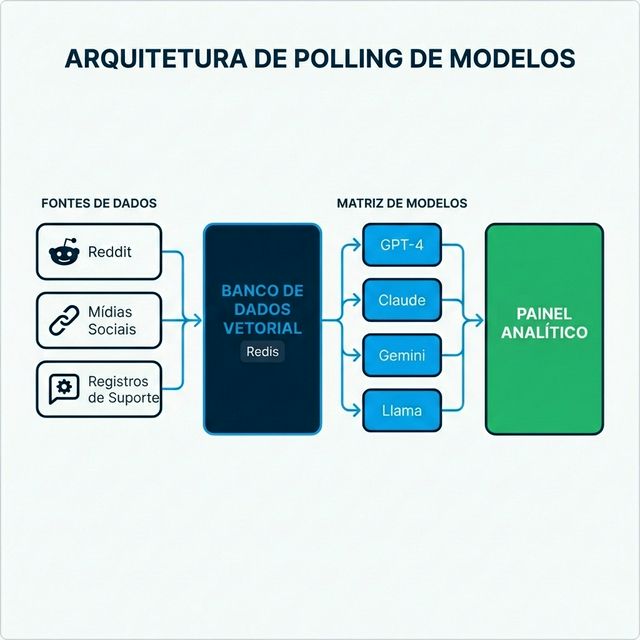
Em vez de consultar um modelo, sistemas enterprise sofisticados consultam arrays de modelos simultaneamente:
- GPT-4 e GPT-4o da OpenAI
- Claude 3.5 da Anthropic
- Gemini do Google
- Llama 3 e outros modelos open-source
Padrões de resposta são analisados para:
- Consenso: Onde modelos concordam, confiança aumenta
- Divergência: Desacordo sinaliza áreas que requerem investigação humana
- Vieses específicos de modelo: Tendências conhecidas são fatoradas
Essa abordagem multi-modelo espelha como enterprises monitoram visibilidade de marca em plataformas de IA — reconhecendo que modelos diferentes podem ter "perspectivas" radicalmente diferentes sobre o mesmo tópico.
Integração de Dados em Tempo Real: A Arquitetura RAG
Os sistemas de pesquisa sintética mais poderosos não dependem apenas de dados de treinamento. Integram informações em tempo real através de Retrieval-Augmented Generation (RAG).
Como RAG Transforma Model Polling
LLMs tradicionais têm data de corte de conhecimento — só podem saber o que existia em seus dados de treinamento. RAG supera essa limitação:
- Ingestão de dados ao vivo: Sistemas coletam continuamente dados do Reddit, Twitter/X, sites de avaliação, logs de suporte e fontes de notícias
- Vetorização: Dados são convertidos em embeddings matemáticos e armazenados em bancos de dados vetoriais (frequentemente Redis pela velocidade)
- Recuperação contextual: Quando persona sintética é consultada, dados recentes relevantes são recuperados e injetados no prompt
- Geração fundamentada: Modelo gera respostas informadas por posts de fórum de ontem, não dados de treinamento de dois anos atrás
Exemplo: Ao perguntar "O que consumidores acham do novo preço da [Marca X]?" — o modelo não alucina de dados de treinamento. Sintetiza discussões reais em redes sociais das últimas 24 horas.
Essa arquitetura é intimamente relacionada a como RAG otimiza conteúdo para descoberta por IA, mas aplicada ao inverso: em vez de tornar conteúdo encontrável por IA, enterprises tornam descobertas de IA acionáveis para humanos.
Precisão e Validação
A pergunta natural: Quão precisos são respondentes sintéticos comparados a humanos reais?
Estudos de Validação
Equipes enterprise usando pesquisa sintética reportam desempenho forte em múltiplas dimensões:
| Métrica | Desempenho Típico |
|---|---|
| Precisão direcional | 80-90% alinhamento com resultados de pesquisa real |
| Precisão de ranking | Respondentes sintéticos classificam preferências de forma similar a humanos |
| Detecção de tendências | Identificação mais precoce de mudanças emergentes de sentimento |
| Detecção de outliers | Melhor identificação de casos extremos e segmentos de nicho |
Onde Humanos Ainda Vencem
Respondentes sintéticos se destacam em agregar padrões conhecidos mas podem ter dificuldade com:
- Categorias de produto genuinamente novas sem discussão histórica
- Dinâmicas emocionais profundas que requerem empatia
- Nuances culturais específicas de comunidades muito estreitas
A melhor prática emergente é validação híbrida: use respondentes sintéticos para velocidade e escala, valide decisões críticas com pesquisa humana direcionada.
Isso espelha a abordagem human-in-the-loop recomendada para aplicações de IA de alto risco.
Arquitetura Técnica para Enterprise
Construir infraestrutura de model polling enterprise-grade requer engenharia sofisticada. A complexidade frequentemente surpreende organizações tentando construir internamente.
Componentes Core
1. Camada de Ingestão de Dados
- Conexões API com plataformas sociais, fóruns, agregadores de reviews
- Decisões de streaming em tempo real vs. processamento em batch
- Limpeza e deduplicação de dados
2. Banco de Dados Vetorial
- Armazenamento para embeddings em escala
- Requisitos de latência de recuperação em milissegundos
- Frequentemente Redis, Pinecone ou Weaviate
3. Camada de Orquestração de Modelos
- Abstração de API unificada entre provedores
- Gestão e versionamento de prompts
- Rate limiting e controles de custo
- Roteamento de fallback quando provedores falham
4. Analytics e Monitoramento
- Scoring de qualidade de resposta
- Detecção de alucinação
- Análise de consistência cross-modelo
- Dashboard executivo e alerting
Desafios de Integração
Diferentes provedores de LLM (OpenAI, Anthropic, Google) têm APIs incompatíveis, limites de rate diferentes e formatos de resposta variados. Sem camada de abstração middleware, codebases ficam emaranhadas com adaptações específicas de provedor.
Plataformas como AICarma investiram anos construindo essas camadas de abstração — permitindo que enterprises comecem a consultar 10+ modelos imediatamente em vez de gastar meses em engenharia de integração. Os padrões arquiteturais requeridos espelham os necessários para monitoramento de marca multi-modelo, tornando soluções integradas particularmente valiosas.
FAQ
Respondentes sintéticos podem substituir toda pesquisa humana?
Não inteiramente. Se destacam em velocidade, escala e agregação de padrões. No entanto, cenários genuinamente novos, exploração emocional profunda e nuances culturalmente específicas ainda se beneficiam de envolvimento humano. A abordagem ideal é híbrida: sintético para amplitude e velocidade, humano para profundidade e validação.
Como prevenir "alucinações" de modelo em respostas de pesquisa?
Arquitetura RAG fundamenta respostas em dados reais. Polling multi-modelo identifica outliers. Scoring de confiança sinaliza respostas incertas. Combinadas, essas técnicas reduzem risco de alucinação significativamente — embora monitoramento permaneça essencial.
Qual a comparação de custo com pesquisa tradicional?
Pesquisa sintética tipicamente custa 10-25% dos métodos tradicionais. Um estudo que poderia requerer R$1.000.000 em taxas de painel, incentivos e custos de agência pode frequentemente ser aproximado por R$100.000-250.000 em custos de API e plataforma — com resultados em dias em vez de meses.
Os dados são defensáveis para propósitos regulatórios ou de conselho?
Varia por contexto. Dados sintéticos são crescentemente aceitos para orientação direcional e iteração rápida. Para indústrias reguladas ou decisões de nível diretoria, abordagens híbridas que incluem validação humana fornecem a defensibilidade que métodos tradicionais ofereciam.
Que infraestrutura é necessária para começar?
Enterprises podem construir do zero ou comprar plataformas. Construir requer talento de engenharia ML, gestão de API multi-provedor, expertise em banco de dados vetorial e manutenção contínua. Plataformas oferecem deploy mais rápido mas menos customização. A maioria das empresas Fortune 500 está escolhendo plataformas pela velocidade de entrega de valor.
Model polling representa mudança fundamental em como enterprises entendem mercados. As empresas que dominam essa capacidade hoje estão construindo vantagens competitivas que se compõem ao longo do tempo — vendo mudanças de mercado mais rápido, testando hipóteses mais barato e tomando decisões com confiança que seus concorrentes mais lentos não conseguem igualar.