Model Polling : Comment les Répondants Synthétiques Remplacent les Focus Groups
Dernière mise à jour : 2 November 2025
Et si vous pouviez organiser un focus group avec 10 000 participants — chacun représentant un profil démographique distinct — et obtenir les résultats en heures au lieu de mois ? Et si ces participants n'éprouvaient jamais de fatigue, n'essayaient jamais de plaire au modérateur, et répondaient toujours honnêtement sur les sujets sensibles ?
Ce n'est pas une expérience de pensée. Cela se passe actuellement dans les départements de recherche des entreprises du monde entier, et ça s'appelle le Model Polling.
Table des Matières
- Le Concept de Répondants Synthétiques
- Comment les LLMs Deviennent des Participants de Focus Group
- L'Avantage Multi-Modèles
- Intégration de Données en Temps Réel : L'Architecture RAG
- Exactitude et Validation
- Architecture Technique pour l'Entreprise
- FAQ
Le Concept de Répondants Synthétiques
L'étude de marché traditionnelle repose sur une hypothèse fondamentale : pour comprendre les consommateurs, il faut interroger des consommateurs. Cette hypothèse a alimenté une industrie de plusieurs milliards de dollars de panels, sondages et focus groups.
Le Model Polling remet en question ce paradigme avec une prémisse révolutionnaire : les grands modèles de langage entraînés sur l'intégralité de l'internet public contiennent un modèle compressé de la société humaine elle-même.
Quand un LLM comme GPT-4 ou Claude génère du texte, il puise dans des patterns appris à partir de milliards de documents écrits par des humains — discussions de forums, avis produits, publications sur les réseaux sociaux, articles académiques. Dans un sens significatif, ces modèles ont « lu » plus d'opinions de consommateurs que n'importe quel chercheur humain ne pourrait en absorber en mille vies.
Les Personas Synthétiques en Pratique
Au lieu de recruter 500 personnes et de les payer pour remplir des sondages, les entreprises créent maintenant des personas synthétiques. En utilisant des prompts système spécialisés, un seul modèle peut simuler des profils démographiques et psychographiques diversifiés :
Exemple de prompt :
« Vous êtes un père de famille de 42 ans vivant en banlieue, trois enfants, revenu du foyer de 120 000 €, préoccupé par la sécurité du véhicule et l'efficacité énergétique. Vous conduisez un Honda Pilot 2019 et envisagez votre prochain achat. Répondez comme cette personne le ferait à la question suivante... »
Le même modèle peut immédiatement devenir :
« Vous êtes un jeune professionnel urbain de 23 ans, soucieux de l'environnement, sans voiture par choix mais envisageant l'achat d'un premier véhicule pour les escapades du week-end... »
En quelques minutes, les chercheurs peuvent simuler des milliers de ces personas, chacune répondant aux mêmes questions depuis sa perspective unique.
Comment les LLMs Deviennent des Participants de Focus Group
L'approche des répondants synthétiques offre des avantages fondamentaux par rapport aux méthodes traditionnelles :
| Dimension | Focus Group Traditionnel | Répondants Synthétiques |
|---|---|---|
| Délai pour les insights | 6-10 semaines | Heures |
| Coût par répondant | 50-200 € | <0,10 € |
| Limites de taille d'échantillon | Contraint par la logistique | Illimité |
| Effet d'observation | Présent | Absent |
| Biais de désirabilité sociale | Significatif | Éliminé |
| Honnêteté sur les sujets sensibles | Variable | Constante |
| Scalabilité | Coût linéaire | Coût marginal quasi nul |
Le Facteur d'Élimination des Biais
Les répondants humains apportent des biais inévitables aux situations de recherche. Ils essaient de paraître cohérents. Ils veulent plaire aux intervieweurs. Ils sont influencés par ce que les autres disent dans la pièce. Ils modifient leurs réponses sur les sujets sensibles comme les finances, la santé ou les préférences controversées.
Les répondants synthétiques n'ont aucune de ces contraintes. Un modèle simulant un électeur conservateur et un électeur progressiste donnera des réponses véritablement différentes — pas des réponses performatives conçues pour signaler l'appartenance à un groupe.
Taux de Satisfaction
Les recherches des adopteurs en entreprise montrent des taux de satisfaction de 87 % parmi les équipes utilisant les données synthétiques, avec beaucoup rapportant une forte corrélation entre les prédictions synthétiques et le comportement réel du marché.
L'Avantage Multi-Modèles
Les premiers adopteurs ont rapidement découvert que s'appuyer sur un seul LLM créait des angles morts. Chaque modèle a des données d'entraînement différentes, des biais différents et des patterns de réponse différents. La solution : le polling multi-modèles.
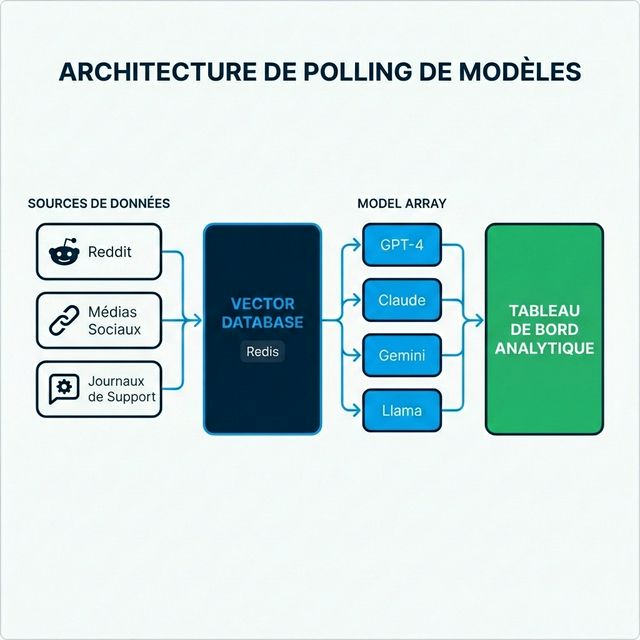
Au lieu d'interroger un seul modèle, les systèmes sophistiqués d'entreprise interrogent des batteries de modèles simultanément :
- GPT-4 et GPT-4o d'OpenAI
- Claude 3.5 d'Anthropic
- Gemini de Google
- Llama 3 et autres modèles open-source
Les patterns de réponse sont ensuite analysés pour :
- Consensus : Quand les modèles s'accordent, la confiance augmente
- Divergence : Les désaccords signalent des zones nécessitant une investigation humaine
- Biais spécifiques aux modèles : Les tendances connues sont factorisées
Cette approche multi-modèles reflète la façon dont les entreprises surveillent la visibilité de marque à travers les plateformes IA — reconnaissant que différents modèles peuvent avoir des « perspectives » radicalement différentes sur le même sujet.
Intégration de Données en Temps Réel : L'Architecture RAG
Les systèmes de recherche synthétique les plus puissants ne s'appuient pas uniquement sur les données d'entraînement des modèles. Ils intègrent des informations en temps réel via la Génération Augmentée par Récupération (RAG).
Comment le RAG Transforme le Model Polling
Les LLMs traditionnels ont une date de coupure des connaissances — ils ne peuvent connaître que ce qui existait dans leurs données d'entraînement. Le RAG surmonte cette limitation :
- Ingestion de données en direct : Les systèmes collectent en continu des données de Reddit, Twitter/X, sites d'avis, logs de support et sources d'actualités
- Vectorisation : Ces données sont converties en embeddings mathématiques et stockées dans des bases de données vectorielles (souvent Redis pour la rapidité)
- Récupération contextuelle : Quand une persona synthétique est interrogée, les données récentes pertinentes sont récupérées et injectées dans le prompt
- Génération fondée : Le modèle génère des réponses informées par les publications de forums d'hier, pas les données d'entraînement vieilles de deux ans
Exemple : Quand on demande « Que pensent les consommateurs des nouveaux tarifs de [Marque X] ? » — le modèle n'hallucine pas à partir des données d'entraînement. Il synthétise les discussions réelles des réseaux sociaux des dernières 24 heures.
Cette architecture est étroitement liée à la façon dont le RAG optimise le contenu pour la découverte IA, mais appliquée en sens inverse : au lieu de rendre le contenu trouvable par l'IA, les entreprises rendent les découvertes IA actionnables pour les humains.
Exactitude et Validation
La question naturelle : quelle est la précision des répondants synthétiques comparés aux vrais humains ?
Études de Validation
Les équipes d'entreprise utilisant la recherche synthétique rapportent de fortes performances sur plusieurs dimensions :
| Métrique | Performance Typique |
|---|---|
| Exactitude directionnelle | 80-90 % d'alignement avec les résultats de sondages réels |
| Exactitude de classement | Les répondants synthétiques classent les préférences de manière similaire aux humains |
| Détection de tendances | Identification plus précoce des changements de sentiment émergents |
| Détection d'anomalies | Meilleure identification des cas limites et segments de niche |
Où les Humains Gagnent Encore
Les répondants synthétiques excellent à agréger des patterns connus mais peuvent avoir des difficultés avec :
- Les catégories de produits véritablement nouvelles sans discussion historique
- Les dynamiques émotionnelles profondes nécessitant de l'empathie
- Les nuances culturelles spécifiques à des communautés très restreintes
La meilleure pratique émergente est la validation hybride : utilisez les répondants synthétiques pour la rapidité et l'échelle, validez les décisions critiques avec une recherche humaine ciblée.
Cela reflète l'approche humain-dans-la-boucle recommandée pour les applications IA à enjeux élevés.
Architecture Technique pour l'Entreprise
Construire une infrastructure de model polling de grade entreprise nécessite une ingénierie sophistiquée. La complexité surprend souvent les organisations qui tentent de construire en interne.
Composants Principaux
1. Couche d'Ingestion de Données
- Connexions API aux plateformes sociales, forums, agrégateurs d'avis
- Décisions de traitement en temps réel vs. par lots
- Nettoyage et déduplication des données
2. Base de Données Vectorielle
- Stockage des embeddings à grande échelle
- Exigences de latence de récupération en millisecondes
- Souvent Redis, Pinecone ou Weaviate
3. Couche d'Orchestration des Modèles
- Abstraction API unifiée entre les fournisseurs
- Gestion et versioning des prompts
- Rate limiting et contrôle des coûts
- Routage de repli quand les fournisseurs échouent
4. Analytics et Monitoring
- Scoring de qualité des réponses
- Détection des hallucinations
- Analyse de cohérence inter-modèles
- Dashboard exécutif et alerting
Défis d'Intégration
Les différents fournisseurs de LLM (OpenAI, Anthropic, Google) ont des APIs incompatibles, des limites de débit différentes et des formats de réponse variés. Sans couche d'abstraction middleware, les codebases deviennent enchevêtrées d'adaptations spécifiques aux fournisseurs.
Des plateformes comme AICarma ont investi des années à construire ces couches d'abstraction — permettant aux entreprises de commencer à interroger 10+ modèles immédiatement plutôt que de passer des mois en ingénierie d'intégration.
FAQ
Les répondants synthétiques peuvent-ils remplacer toute recherche humaine ?
Pas entièrement. Ils excellent en rapidité, échelle et agrégation de patterns. Cependant, les scénarios véritablement nouveaux, l'exploration émotionnelle profonde et les nuances culturellement spécifiques bénéficient encore de l'implication humaine. L'approche optimale est hybride : synthétique pour l'ampleur et la rapidité, humain pour la profondeur et la validation.
Comment prévenir les « hallucinations » de modèle dans les réponses de recherche ?
L'architecture RAG ancre les réponses dans des données réelles. Le polling multi-modèles identifie les valeurs aberrantes. Le scoring de confiance signale les réponses incertaines. Combinées, ces techniques réduisent significativement le risque d'hallucination — bien que le monitoring reste essentiel.
Quelle est la comparaison de coût avec la recherche traditionnelle ?
La recherche synthétique coûte typiquement 10-25 % des méthodes traditionnelles. Une étude qui pourrait nécessiter 200 000 € en frais de panel, incitations et coûts d'agence peut souvent être approximée pour 20 000-50 000 € en coûts API et frais de plateforme — avec des résultats en jours au lieu de mois.
Les données sont-elles aussi défendables pour des objectifs réglementaires ou de conseil d'administration ?
Cela varie selon le contexte. Les données synthétiques sont de plus en plus acceptées pour l'orientation directionnelle et l'itération rapide. Pour les industries réglementées ou les décisions au niveau du CA, les approches hybrides incluant une validation humaine fournissent la défendabilité qu'offraient les méthodes traditionnelles.
Quelle infrastructure est nécessaire pour commencer ?
Les entreprises peuvent construire de zéro ou acheter des plateformes. Construire nécessite des talents en ML engineering, la gestion d'API multi-fournisseurs, l'expertise en bases de données vectorielles et une maintenance continue. Les plateformes offrent un déploiement plus rapide mais moins de personnalisation. La plupart des entreprises du Fortune 500 choisissent les plateformes pour la rapidité de mise en valeur.
Le model polling représente un changement fondamental dans la façon dont les entreprises comprennent les marchés. Les entreprises qui maîtrisent cette capacité aujourd'hui construisent des avantages compétitifs qui se composent dans le temps — voyant les changements de marché plus vite, testant les hypothèses à moindre coût, et prenant des décisions avec une confiance que leurs concurrents plus lents ne peuvent égaler.