Oui, Vous Pouvez Optimiser pour les LLMs : Déconstruire le Mythe de la 'Boîte Noire'
Dernière mise à jour : 20 August 2025
« L'IA, c'est juste des maths. Des milliards de paramètres. Une boîte noire. On ne peut pas faire de SEO dessus. »
Nous entendons ce mythe de la part de personnes intelligentes — ingénieurs, data scientists, même des marketeurs qui se targuent d'être data-driven. Et en surface, cela semble raisonnable. Après tout, un réseau de neurones avec 175 milliards de paramètres ne vient pas exactement avec un mode d'emploi.
Mais voilà : la recherche aussi était une « boîte noire ». Personne en dehors de Google ne connaissait l'algorithme exact. Cela n'a pas empêché toute une industrie de le reverse-engineer et de construire un marché SEO de 68 milliards de dollars. Le principe n'a pas changé — seule la boîte a changé.
L'IA n'est pas aléatoire. Elle est probabiliste. Et les systèmes probabilistes, par définition, peuvent être influencés. Si vous comprenez les variables qui façonnent la distribution de probabilité, vous pouvez faire pencher les chances en votre faveur.
Cet article démonte le mythe de la boîte noire pièce par pièce — avec des citations de recherche, pas du blabla — et vous donne le cadre pour réfléchir clairement à l'optimisation IA.
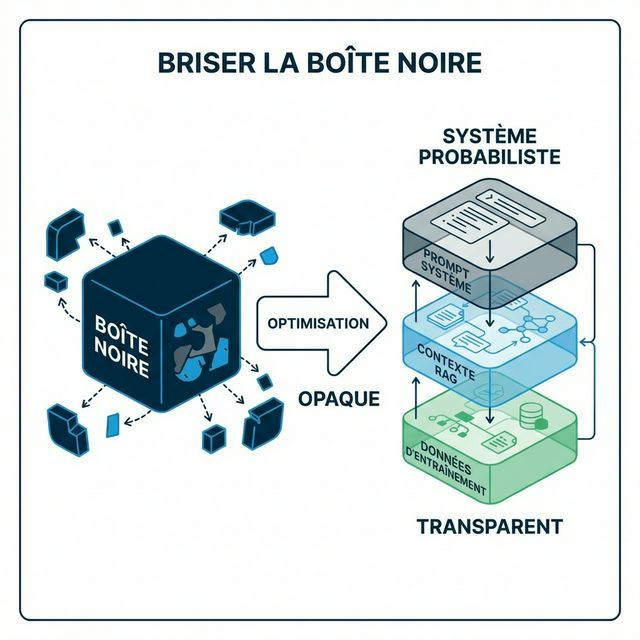
Table des Matières
- L'Origine du Mythe
- Probabiliste ≠ Aléatoire : La Distinction Cruciale
- Les Trois Couches que Vous Pouvez Influencer
- Couche 1 : Données d'Entraînement — La Mémoire à Long Terme
- Couche 2 : Contexte RAG — La Mémoire à Court Terme
- Couche 3 : Architecture Système — La Personnalité
- Les Preuves : L'Optimisation Fonctionne
- Ce que l'Optimisation ne Signifie PAS
- De la Théorie à la Pratique : La Méthodologie AICarma
- FAQ
L'Origine du Mythe
Le mythe de l'« impossibilité d'optimiser » vient d'une incompréhension fondamentale de ce pour quoi nous optimisons.
Les critiques observent correctement qu'on ne peut pas prédire les tokens exacts qu'un LLM va générer. C'est vrai. Les LLMs utilisent le nucleus sampling (Holtzman et al., « The Curious Case of Neural Text Degeneration », ICLR 2020), qui introduit un aléa contrôlé dans la génération de texte. Le même prompt peut produire des sorties différentes à chaque exécution.
Mais cette critique confond la prédiction au niveau des tokens avec l'influence au niveau de la distribution. Vous n'avez pas besoin de prédire la phrase exacte qu'un LLM va écrire. Vous devez augmenter la probabilité que votre marque apparaisse dans la distribution des sorties probables pour un prompt donné.
Considérez l'analogie avec la météo. Vous ne pouvez pas prédire la température exacte à 15h47 mardi prochain. Mais vous pouvez dire avec une grande confiance que juillet sera plus chaud que janvier. Le système a de la variance, mais il a une structure — et cette structure peut être analysée et exploitée.
Probabiliste ≠ Aléatoire : La Distinction Cruciale
Cette distinction est si importante qu'elle mérite sa propre section.
Aléatoire signifie que chaque résultat est également probable. Lancez un dé équilibré : chaque face a 1/6 de chance. Aucune stratégie ne peut changer cela.
Probabiliste signifie que les résultats ont des vraisemblances différentes selon les conditions. Le poker est probabiliste. Les cartes sont distribuées aléatoirement, mais les meilleurs joueurs gagnent régulièrement parce qu'ils comprennent les probabilités et gèrent le flux d'information.
Les LLMs sont probabilistes de manière très structurée. Lors de la génération de texte, le modèle calcule une probabilité pour chaque token possible (fragment de mot). Le token « Salesforce » pourrait avoir une probabilité de 23 % après le prompt « le meilleur CRM est... » tandis que « Monday » a une probabilité de 4 %.
Ces probabilités ne sont pas aléatoires. Elles sont façonnées par :
- Ce que le modèle a appris pendant l'entraînement (données d'entraînement)
- L'information récupérée en temps réel (contexte RAG)
- Les instructions qui gouvernent le système (prompts système et filtres de sécurité)
Chacune de ces couches peut être influencée. Examinons comment.
Les Trois Couches que Vous Pouvez Influencer
Pensez à la recherche IA moderne comme un empilement de trois couches. Chaque couche opère indépendamment, mais elles se combinent pour produire le résultat final. Optimiser signifie travailler les trois couches simultanément.
Couche 1 : Données d'Entraînement — La Mémoire à Long Terme
Ce que c'est : Le vaste corpus de texte que le modèle a ingéré pendant le pré-entraînement. Pour GPT-4, cela inclut des livres, sites web, code, articles académiques, Wikipedia, Reddit et plus — des centaines de milliards de tokens.
Pourquoi c'est important : Les données d'entraînement créent les « croyances par défaut » du modèle. Si votre marque apparaît fréquemment et positivement dans des sources d'entraînement de haute qualité, le modèle développe une forte association préalable entre votre marque et votre catégorie.
La science : Carlini et al. ont démontré dans « Quantifying Memorization Across Neural Language Models » (2022) que les LLMs mémorisent et reproduisent les données d'entraînement à des taux proportionnels à la fréquence et à la distinctivité des données. Les marques qui apparaissent plus fréquemment dans les corpus d'entraînement sont plus susceptibles d'être générées pendant l'inférence.
Votre stratégie d'influence : SEO des Données d'Entraînement. Vous ne pouvez pas modifier rétroactivement les données d'entraînement de GPT-4 — elles sont figées. Mais vous pouvez influencer ce qui entrera dans l'entraînement de GPT-5 en vous assurant que votre marque est présente dans les sources à fort poids aujourd'hui :
- Wikipedia : La source à plus fort poids dans la plupart des corpus d'entraînement
- Common Crawl : L'épine dorsale des données d'entraînement web (documenté par l'Allen Institute)
- Reddit : Massivement surreprésenté dans les jeux d'entraînement récents. Notre Stratégie GEO Reddit couvre cela en détail
- Publications académiques : Le contenu cité est renforcé à travers les pipelines d'indexation académique
C'est le jeu à long terme. Les changements dans les données d'entraînement mettent des mois à se manifester — typiquement lors de la sortie d'une nouvelle version du modèle. Mais l'impact est fondamental et persistant.
Couche 2 : Contexte RAG — La Mémoire à Court Terme
Ce que c'est : La Génération Augmentée par Récupération. Quand vous posez une question à Perplexity, il cherche sur le web en temps réel, récupère des passages pertinents, et les utilise comme contexte pour générer sa réponse. Google AI Overviews, Bing Chat, et même le mode navigation de ChatGPT fonctionnent de manière similaire.
Pourquoi c'est important : Le RAG est la façon dont l'IA se connecte à l'information actuelle. Vos classements SEO, la structure de votre contenu et votre accessibilité technique affectent directement le fait que le système de récupération intègre ou non votre contenu dans la fenêtre de contexte du modèle.
La science : L'article fondateur sur le RAG de Lewis et al. (« Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks », NeurIPS 2020) a montré que les modèles augmentés par récupération favorisent fortement les documents qui obtiennent de bons scores tant en pertinence qu'en récupérabilité. De façon critique, Liu et al. ont ensuite démontré dans « Lost in the Middle » (2023) que la position dans le contexte récupéré compte — les modèles prêtent plus d'attention à l'information au début et à la fin de l'ensemble récupéré.
Votre stratégie d'influence : Optimisation SEO RAG et Optimisation de la Fenêtre de Contexte. Tactiques clés :
- Densité sémantique : Écrivez du contenu qui concentre un maximum de sens en un minimum de tokens — cela augmente les scores de pertinence lors de la récupération
- Mettez en avant les propositions de valeur : Placez vos affirmations les plus importantes dans les 100 premiers mots de chaque section
- Structurez pour le découpage : Utilisez des titres H2/H3 clairs pour que les systèmes de récupération puissent extraire des passages focalisés et autonomes
- Implémentez le Balisage Schema : Donnez à l'IA des faits déterministes, réduisant le besoin du modèle d'inférer ou d'halluciner
Contrairement aux données d'entraînement, l'optimisation RAG produit des résultats rapides. Changez votre contenu aujourd'hui, et Perplexity pourra vous citer différemment dès demain.
Couche 3 : Architecture Système — La Personnalité
Ce que c'est : Les instructions cachées et les garde-fous qui façonnent le comportement des produits IA. Les prompts système disent à ChatGPT d'« être utile », de « prioriser les sources faisant autorité », d'« éviter les conseils médicaux sans avertissements ». Les filtres de sécurité suppriment certaines sorties. Les décisions au niveau produit (comme chercher sur le web ou s'appuyer sur les données d'entraînement) affectent ce que le modèle « voit ».
Pourquoi c'est important : Même si vous êtes dans les données d'entraînement et parfaitement optimisé pour la récupération, l'architecture système peut supprimer ou amplifier votre présence. Si le prompt système de ChatGPT dit « priorisez les institutions médicales établies pour les requêtes santé », et que vous êtes un blog santé startup — votre contenu est dépriorisé indépendamment de sa qualité.
La science : La propre recherche d'OpenAI sur le « Behavior of Large Language Models as System Prompt Consumers » (2023) démontre que les prompts système affectent significativement les distributions de sortie, incluant les préférences de sources et la pondération de l'autorité.
Votre stratégie d'influence : Alignez-vous avec les objectifs du système. Cela signifie :
- Construisez des signaux d'autorité : Pour le contenu YMYL (Your Money or Your Life), l'autorité n'est pas optionnelle — c'est le gardien
- Établissez une présence d'Entité : Les marques avec des données d'entité claires et structurées sont traitées comme des entités « connues » par le système
- Gagnez des citations : Être cité par d'autres sources faisant autorité crée une cascade de confiance alignée avec les préférences de sécurité au niveau système
Cette couche est la plus difficile à optimiser directement, mais elle récompense la construction de marque à long terme plutôt que les tactiques à court terme.
Les Preuves : L'Optimisation Fonctionne
Si vous êtes encore sceptique, considérez les preuves empiriques.
Une étude marquante de Georgia Tech, IIT Delhi et d'autres (Aggarwal et al., « GEO: Generative Engine Optimization », 2024) a testé des stratégies d'optimisation spécifiques sur les moteurs génératifs et a trouvé :
| Stratégie | Amélioration de la Visibilité |
|---|---|
| Ajout de citations aux affirmations | +30-40 % |
| Inclusion de statistiques pertinentes | +20-30 % |
| Utilisation d'un langage technique faisant autorité | +15-25 % |
| Structuration avec des citations claires | +10-20 % |
Ce sont des améliorations mesurables et reproductibles. Pas théoriques. Pas anecdotiques. Validées scientifiquement.
Nos propres données à travers plus de 1 000 moniteurs de marque AICarma corroborent ces résultats. Les marques qui implémentent un GEO systématique — sur les trois couches — voient une amélioration moyenne de 35 % de leur Score de Visibilité IA en 90 jours.
Ce que l'Optimisation ne Signifie PAS
Soyons clairs sur les limites. L'optimisation n'est pas de la manipulation :
- Vous ne pouvez pas garantir que ChatGPT dira « La Marque X est la meilleure ». Vous pouvez augmenter la probabilité.
- Vous ne pouvez pas « hacker » le modèle avec de l'injection de prompt ou des techniques adversariales. Elles sont détectées et pénalisées.
- Vous ne pouvez pas contrôler les paramètres de température. Si le modèle tourne à haute température, les sorties seront plus variées indépendamment de votre optimisation.
- Vous ne pouvez pas faire persister de fausses affirmations. Les LLMs croisent les sources. Les affirmations non étayées sont filtrées ou vérifiées pour les hallucinations.
Optimiser signifie fournir aux systèmes IA l'information de la plus haute qualité, la plus structurée, la plus corroborée sur votre marque — afin que quand le modèle génère une réponse, le chemin de moindre résistance passe par votre contenu.
De la Théorie à la Pratique : La Méthodologie AICarma
Comprendre les trois couches, c'est la théorie. L'opérationnaliser nécessite une méthodologie :
- Mesurez votre état actuel sur les trois couches en utilisant le monitoring multi-modèle
- Identifiez quelle couche est votre maillon faible (Données d'Entraînement ? RAG ? Autorité ?)
- Priorisez les optimisations par couche — RAG pour les gains rapides, Données d'Entraînement pour la capitalisation à long terme, Autorité pour la durabilité
- Exécutez en utilisant le Cycle GEO pour maintenir une amélioration continue
- Suivez les résultats par rapport à vos benchmarks concurrentiels pour mesurer le progrès relatif
La boîte noire n'est plus si noire quand vous comprenez son architecture. Et les marques qui intériorisent cette vérité en premier composeront leur avantage pendant des années.
FAQ
Si l'IA est optimisable, pourquoi ne voit-on pas plus de gens le faire ?
Parce que le domaine est nouveau. Le SEO a mis 10 ans pour mûrir du « bourrage de mots-clés dans les balises meta » à une discipline sophistiquée. Le GEO en est à sa deuxième année. Les premiers entrants — comme les premiers SEOs — récolteront des récompenses disproportionnées avant que le marché ne se sature.
Optimiser pour l'IA, ça revient juste à « faire du bon SEO » ?
En partie, mais pas entièrement. Un bon SEO aide pour la Couche 2 (récupération RAG). Mais il n'aborde pas la Couche 1 (présence dans les données d'entraînement) ni la Couche 3 (alignement d'autorité au niveau système). Le GEO est un surensemble du SEO, pas un synonyme.
Les entreprises IA ne vont-elles pas empêcher l'optimisation ?
Elles n'ont pas empêché le SEO en 25 ans. Les entreprises IA veulent que du contenu de haute qualité et faisant autorité émerge — cela rend leurs produits meilleurs. Ce qu'elles ne veulent pas, c'est la manipulation et le spam. L'optimisation légitime qui améliore la qualité du contenu est alignée avec leurs intérêts.
Comment mesurer si l'optimisation fonctionne ?
Suivez votre Score de Visibilité IA dans le temps. Des améliorations significatives apparaissent en 4-8 semaines pour l'optimisation RAG et 3-6 mois pour les effets des données d'entraînement. Utilisez le benchmarking concurrentiel pour séparer vos gains des mouvements généraux du marché.