Model Polling: Cómo los Respondientes Sintéticos Están Reemplazando a los Focus Groups
Última actualización: 2 November 2025
¿Qué pasaría si pudieras hacer un focus group con 10,000 participantes — cada uno representando un perfil demográfico distinto — y tener resultados en horas en lugar de meses? ¿Qué pasaría si esos participantes nunca experimentaran fatiga, nunca intentaran complacer al moderador, y siempre respondieran honestamente sobre temas sensibles?
Esto no es un experimento mental. Está sucediendo ahora en departamentos de investigación enterprise en todo el mundo, y se llama Model Polling.
Tabla de Contenidos
- El Concepto de Respondientes Sintéticos
- Cómo los LLMs Se Convierten en Participantes de Focus Group
- La Ventaja Multi-Modelo
- Integración de Datos en Tiempo Real: La Arquitectura RAG
- Precisión y Validación
- Arquitectura Técnica para Enterprise
- FAQ
El Concepto de Respondientes Sintéticos
La investigación de mercado tradicional opera bajo un supuesto fundamental: para entender a los consumidores, debes preguntar a los consumidores. Este supuesto impulsó una industria multibillonaria de paneles, encuestas y focus groups.
El Model Polling desafía este paradigma con una premisa revolucionaria: Los Modelos de Lenguaje entrenados en todo el internet público contienen un modelo comprimido de la sociedad humana misma.
Cuando un LLM como GPT-4 o Claude genera texto, recurre a patrones aprendidos de miles de millones de documentos escritos por humanos — discusiones en foros, reseñas de productos, publicaciones en redes sociales, papers académicos. En un sentido significativo, estos modelos han "leído" más opiniones de consumidores de lo que cualquier investigador humano podría absorber en mil vidas.
Personas Sintéticas en la Práctica
En lugar de reclutar 500 personas y pagarles para completar encuestas, las empresas enterprise ahora crean personas sintéticas. Usando prompts de sistema especializados, un solo modelo puede simular perfiles demográficos y psicográficos diversos:
Ejemplo de prompt:
"Eres un padre suburbano de 42 años con tres hijos, ingreso familiar de $120,000, preocupado por la seguridad vehicular y la eficiencia de combustible. Conduces un Honda Pilot 2019 y estás considerando tu próxima compra. Responde como esta persona lo haría a la siguiente pregunta..."
El mismo modelo puede convertirse inmediatamente en:
"Eres un profesional urbano de 23 años, ambientalmente consciente, sin auto por elección pero considerando la compra de su primer vehículo para viajes de fin de semana..."
En minutos, los investigadores pueden simular miles de estas personas, cada una respondiendo las mismas preguntas desde su perspectiva única.
Cómo los LLMs Se Convierten en Participantes
El enfoque de respondientes sintéticos ofrece ventajas fundamentales sobre los métodos tradicionales:
| Dimensión | Focus Group Tradicional | Respondientes Sintéticos |
|---|---|---|
| Tiempo a insights | 6-10 semanas | Horas |
| Costo por respondiente | $50-200 | <$0.10 |
| Límites de muestra | Restringido por logística | Ilimitado |
| Efecto observador | Presente | Ausente |
| Sesgo de deseabilidad social | Significativo | Eliminado |
| Honestidad en temas sensibles | Variable | Consistente |
| Escalabilidad | Costo lineal | Costo marginal cercano a cero |
El Factor de Eliminación de Sesgo
Los respondientes humanos traen sesgos inevitables a los entornos de investigación. Intentan parecer consistentes. Quieren complacer a los entrevistadores. Son influenciados por lo que otros en la sala dicen. Modifican respuestas sobre temas sensibles como finanzas, salud o preferencias controversiales.
Los respondientes sintéticos no tienen estas restricciones. Un modelo simulando un votante conservador y un votante progresista dará respuestas genuinamente diferentes — no performativas diseñadas para señalar pertenencia grupal.
Tasas de Satisfacción
La investigación de adoptadores enterprise muestra tasas de satisfacción del 87% entre equipos usando datos sintéticos, con muchos reportando alta correlación entre predicciones sintéticas y comportamiento real del mercado.
La Ventaja Multi-Modelo
Los primeros adoptadores descubrieron rápidamente que depender de un solo LLM creaba puntos ciegos. Cada modelo tiene diferentes datos de entrenamiento, diferentes sesgos y diferentes patrones de respuesta. La solución: polling multi-modelo.
En lugar de consultar un modelo, los sistemas enterprise sofisticados consultan arrays de modelos simultáneamente:
- GPT-4 y GPT-4o de OpenAI
- Claude 3.5 de Anthropic
- Gemini de Google
- Llama 3 y otros modelos open-source
Los patrones de respuesta se analizan para:
- Consenso: Donde los modelos coinciden, la confianza aumenta
- Divergencia: El desacuerdo señala áreas que requieren investigación humana
- Sesgos específicos del modelo: Las tendencias conocidas se factorizan
Este enfoque multi-modelo refleja cómo las empresas monitorean la visibilidad de marca en plataformas IA — reconociendo que diferentes modelos pueden tener "perspectivas" radicalmente diferentes sobre el mismo tema.
Integración de Datos La Arquitectura RAG
Los sistemas de investigación sintética más poderosos no dependen solo de los datos de entrenamiento del modelo. Integran información en tiempo real a través de Generación Aumentada por Recuperación (RAG).
Cómo RAG Transforma el Model Polling
Los LLMs tradicionales tienen una fecha de corte de conocimiento — solo pueden saber lo que existía en sus datos de entrenamiento. RAG supera esta limitación:
- Ingesta de datos en vivo: Los sistemas recopilan datos continuamente de Reddit, Twitter/X, sitios de reseñas, logs de soporte y fuentes de noticias
- Vectorización: Estos datos se convierten en embeddings matemáticos y se almacenan en bases de datos vectoriales (frecuentemente usando Redis por velocidad)
- Recuperación contextual: Cuando una persona sintética es consultada, se recuperan datos recientes relevantes y se inyectan en el prompt
- Generación fundamentada: El modelo genera respuestas informadas por las publicaciones de foros de ayer, no datos de entrenamiento de hace dos años
Ejemplo: Al preguntar "¿Qué piensan los consumidores sobre los nuevos precios de [Marca X]?" — el modelo no alucina desde datos de entrenamiento. Sintetiza discusiones reales en redes sociales de las últimas 24 horas.
Esta arquitectura está estrechamente relacionada con cómo RAG optimiza contenido para descubrimiento IA, pero aplicada a la inversa: en lugar de hacer que el contenido sea encontrable por IA, las empresas hacen que los hallazgos de IA sean accionables para humanos.
Precisión y Validación
La pregunta natural: ¿Qué tan precisos son los respondientes sintéticos comparados con humanos reales?
Estudios de Validación
Los equipos enterprise usando investigación sintética reportan fuerte rendimiento en múltiples dimensiones:
| Métrica | Rendimiento Típico |
|---|---|
| Precisión direccional | 80-90% de alineación con resultados de encuestas reales |
| Precisión de ranking | Respondientes sintéticos clasifican preferencias de manera similar a humanos |
| Detección de tendencias | Identificación más temprana de cambios emergentes de sentimiento |
| Detección de outliers | Mejor identificación de casos extremos y segmentos nicho |
Donde los Humanos Aún Ganan
Los respondientes sintéticos sobresalen en agregar patrones conocidos pero pueden tener dificultades con:
- Categorías de productos genuinamente nuevas sin discusión histórica
- Dinámicas emocionales profundas que requieren empatía
- Matices culturales específicos de comunidades muy concretas
La mejor práctica emergente es la validación híbrida: usar respondientes sintéticos para velocidad y escala, validar decisiones críticas con investigación humana dirigida.
Esto refleja el enfoque human-in-the-loop recomendado para aplicaciones IA de alto riesgo.
Arquitectura Técnica para Enterprise
Construir infraestructura de model polling de grado enterprise requiere ingeniería sofisticada. La complejidad frecuentemente sorprende a organizaciones que intentan construir internamente.
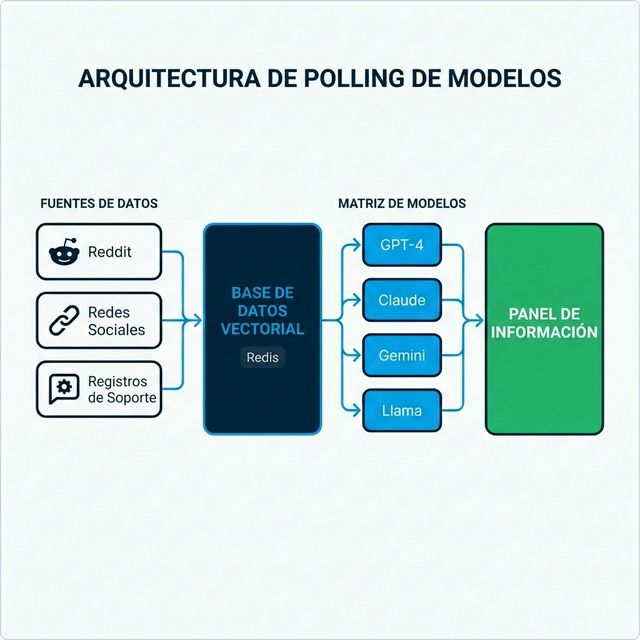
Componentes Core
1. Capa de Ingesta de Datos
- Conexiones API a plataformas sociales, foros, agregadores de reseñas
- Decisiones de streaming en tiempo real vs. procesamiento por lotes
- Limpieza y deduplicación de datos
2. Base de Datos Vectorial
- Almacenamiento de embeddings a escala
- Requisitos de latencia de recuperación en milisegundos
- Frecuentemente Redis, Pinecone o Weaviate
3. Capa de Orquestación de Modelos
- Abstracción API unificada entre proveedores
- Gestión y versionado de prompts
- Rate limiting y controles de costos
- Enrutamiento de fallback cuando los proveedores fallan
4. Analytics y Monitoreo
- Scoring de calidad de respuesta
- Detección de alucinaciones
- Análisis de consistencia entre modelos
- Dashboard ejecutivo y alertas
Desafíos de Integración
Diferentes proveedores de LLM (OpenAI, Anthropic, Google) tienen APIs incompatibles, diferentes rate limits y formatos de respuesta variados. Sin una capa de abstracción middleware, los codebases se enmarañan con adaptaciones específicas del proveedor.
Plataformas como AICarma han invertido años construyendo estas capas de abstracción — permitiendo a las empresas comenzar a hacer polling de 10+ modelos inmediatamente en lugar de pasar meses en ingeniería de integración. Los patrones arquitectónicos requeridos reflejan los necesarios para monitoreo de marca multi-modelo, haciendo que las soluciones integradas sean particularmente valiosas.
FAQ
¿Los respondientes sintéticos pueden reemplazar toda la investigación humana?
No completamente. Sobresalen en velocidad, escala y agregación de patrones. Sin embargo, escenarios genuinamente nuevos, exploración emocional profunda y matices culturalmente específicos aún se benefician de la participación humana. El enfoque óptimo es híbrido: sintético para amplitud y velocidad, humano para profundidad y validación.
¿Cómo se previenen las "alucinaciones" del modelo en respuestas de investigación?
La arquitectura RAG fundamenta las respuestas en datos reales. El polling multi-modelo identifica outliers. El scoring de confianza señala respuestas inciertas. Combinadas, estas técnicas reducen significativamente el riesgo de alucinación — aunque el monitoreo sigue siendo esencial.
¿Cuál es la comparación de costos con investigación tradicional?
La investigación sintética típicamente cuesta 10-25% de los métodos tradicionales. Un estudio que podría requerir $200,000 en tarifas de panel, incentivos y costos de agencia puede frecuentemente aproximarse por $20,000-50,000 en costos de API y tarifas de plataforma — con resultados en días en lugar de meses.
¿Los datos son defendibles para propósitos regulatorios o de junta directiva?
Esto varía por contexto. Los datos sintéticos se aceptan cada vez más para guía direccional e iteración rápida. Para industrias reguladas o decisiones a nivel de junta, los enfoques híbridos que incluyen validación humana proporcionan la defendibilidad que los métodos tradicionales ofrecían.
¿Qué infraestructura se requiere para comenzar?
Las empresas pueden construir desde cero o comprar plataformas. Construir requiere talento en ingeniería ML, gestión de API multi-proveedor, experiencia en bases de datos vectoriales y mantenimiento continuo. Las plataformas ofrecen despliegue más rápido pero menos personalización. La mayoría de empresas Fortune 500 están eligiendo plataformas por velocidad de valor.
El model polling representa un cambio fundamental en cómo las empresas entienden los mercados. Las compañías que dominan esta capacidad hoy están construyendo ventajas competitivas que se componen con el tiempo — viendo cambios de mercado más rápido, probando hipótesis más barato y tomando decisiones con una confianza que sus competidores más lentos no pueden igualar.