Den Wandel überleben: Ein strategisches Playbook für den Umgang mit KI-Such-Volatilität
Letzte Aktualisierung: 30. August 2025
Wir haben es alle erlebt: Montag ist Ihre Marke die Top-Empfehlung in ChatGPT für Ihre Kategorie. Dienstag rollt ein Modellupdate aus, die Temperatur verschiebt sich, und Sie verschwinden. Mittwoch sind Sie zurück — aber auf Position drei. Freitag sind Sie wieder weg.
Wie wir in unserem umfassenden Leitfaden zur KI-Such-Volatilität dokumentiert haben, ist diese Instabilität kein Fehler. Sie ist die fundamentale Natur probabilistischer Systeme. KI-Empfehlungen werden durch Sampling aus Wahrscheinlichkeitsverteilungen generiert — nicht aus einem festen Index abgerufen.
Zu verstehen, warum es passiert, war Schritt eins. Dieser Artikel ist Schritt zwei: ein strategisches Playbook zum Überleben, Ausnutzen und letztendlich Gedeihen in einer volatilen KI-Suchlandschaft.
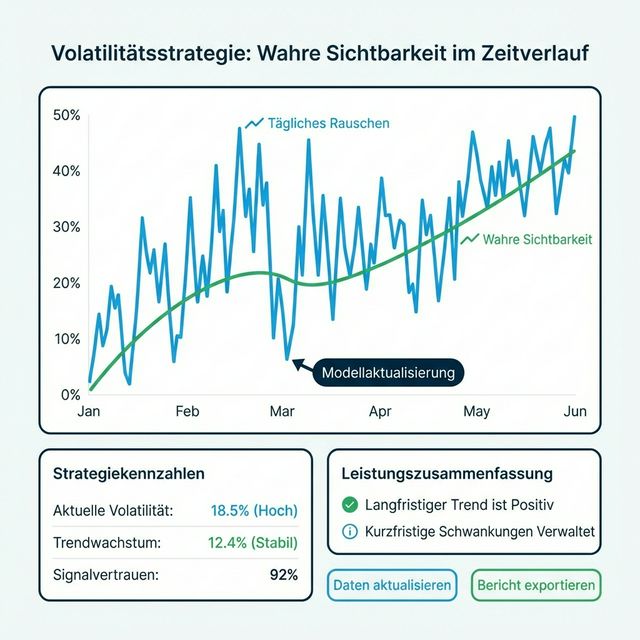
Inhaltsverzeichnis
- Die Kosten der Volatilitätspanik
- Strategie 1: Der Portfolio-Ansatz
- Strategie 2: Der eigene Datengraben
- Strategie 3: Der Korroborations-Schild
- Strategie 4: Das trendbasierte Reporting-Framework
- Strategie 5: Volatilitätsfenster ausnutzen
- Die Wissenschaft der KI-Instabilität
- Eine antifragile Marke aufbauen
- Branchenspezifische Volatilitäts-Playbooks
- FAQ
Die Kosten der Volatilitätspanik
Bevor wir Lösungen besprechen, quantifizieren wir das Problem. Volatilität selbst zerstört keine Marken. Panikgetriebene Reaktionen auf Volatilität zerstören sie.
Wir haben beobachtet, wie Teams diese kostspieligen Fehler machen:
| Panikreaktion | Tatsächliche Kosten | Bessere Reaktion |
|---|---|---|
| „Wir sind in ChatGPT gefallen! Alles umschreiben!" | 15-30.000$ Content-Produktion verschwendet für Rauschen | 7 Tage warten. Prüfen, ob es ein Trend oder ein Ausreißer ist. |
| „KI-Monitoring abschalten — die Zahlen sind zu beängstigend." | Verlorene Frühwarnung bei echten Einbrüchen | Von täglichen Snapshots zu wöchentlichen gleitenden Durchschnitten wechseln |
| „Unser Wettbewerber hat uns überholt — seine Strategie kopieren!" | Taktiken ohne Kontextverständnis kopiert | Wettbewerbsanalyse, um zu verstehen warum sie gewonnen haben |
| „KI ist zu unvorhersagbar. Konzentrieren wir uns nur auf Google." | Aufgabe eines Kanals mit 300% jährlichem Wachstum | Volatilität als Preis des Early-Mover-Vorteils akzeptieren |
Forschung aus Kahnemans Verhaltensökonomie (Nobelpreis 2002) zeigt, dass Menschen verlustaveris sind: Verluste fühlen sich etwa doppelt so schmerzhaft an wie gleichwertige Gewinne sich gut anfühlen. Das bedeutet, ein 10-Punkte-Sichtbarkeitseinbruch fühlt sich katastrophal an, auch wenn letzte Woche ein 10-Punkte-Gewinn kam. Das Gegenmittel ist systematische, datengetriebene Strategie — keine emotionale Reaktion.
Strategie 1: Der Portfolio-Ansatz
In der Finanzwelt setzt man nicht alles auf eine Aktie. In GEO ist alles auf ein Modell zu setzen ebenso gefährlich.
Modell-Diversifizierung
Verschiedene KI-Modelle haben fundamental unterschiedliche Architekturen, Trainingsdaten und Retrieval-Mechanismen:
| Modell | Architektur | Volatilitätsprofil | Optimierungsfokus |
|---|---|---|---|
| ChatGPT | Training-lastig, intermittierendes Web-Browsing | Moderat (verschiebt sich bei Modellupdates) | Trainingsdatenpräsenz, Entity-Stärke |
| Perplexity | RAG-lastig, Echtzeit-Websuche | Hoch (ändert sich mit jedem Crawl-Zyklus) | RAG-Optimierung, Content-Frische |
| Claude | Training-lastig, zitierkonservativ | Niedrig-Moderat (stabil, aber schwer zu beeinflussen) | Autoritätssignale, akademische Korroboration |
| Gemini | Hybrid Training + Google-Suche-Integration | Moderat | Traditionelles SEO + Entity-Optimierung |
| Copilot | Bing-Integration + GPT-Backbone | Moderat-Hoch | Bing SEO, strukturierte Content-Formate |
Das Portfolio-Prinzip: Wenn Ihre Sichtbarkeit in ChatGPT durch ein Modellupdate sinkt, hedgt Ihre starke Perplexity-Präsenz den Einfluss. Sie behalten Kategoriesichtbarkeit, selbst wenn ein Kanal schwankt.
Forschung von Zhao et al. („Survey of Large Language Models," 2023) bestätigt, dass Modellarchitekturen messbar unterschiedliche Output-Verteilungen für identische Eingaben erzeugen — was die Diversifizierungsthese wissenschaftlich validiert.
Quellen-Diversifizierung
Über die Modellvielfalt hinaus diversifizieren Sie die Quellen, aus denen KI schöpft:
- Wenn KI primär G2-Bewertungen für Ihre Kategorie zitiert, verlassen Sie sich nicht allein auf Ihren Blog
- Bauen Sie „Satelliten-Autorität" über Reddit, Bewertungsplattformen, Fachpresse und Community-Foren auf
- Wenn eine Quelle KI-Gewicht verliert (häufig bei Modellupdates), halten andere Ihren Sichtbarkeits-Floor
Unser Reddit-GEO-Strategieleitfaden behandelt einen der wirkungsvollsten Diversifizierungskanäle im Detail.
Strategie 2: Der eigene Datengraben
Der mächtigste Schutz gegen Volatilität sind proprietäre Daten — Informationen, die nirgendwo sonst existieren und Ihnen zugeschrieben werden müssen.
Warum generischer Content Verwundbarkeit schafft
Wenn Sie generischen „Wie wähle ich ein CRM"-Content veröffentlichen, kann eine KI gleichwertige Informationen aus 100 anderen Quellen synthetisieren. Sie sind commoditisiert. Die KI braucht nicht speziell Sie — sie braucht die Information, und es gibt viele alternative Anbieter.
Wenn ein Modellupdate Quellengewichte verschiebt, sind commoditisierte Content-Anbieter die ersten Opfer.
Einen Datengraben aufbauen
| Eigener Datentyp | Warum verteidigbar | Beispiel |
|---|---|---|
| Originalforschung | Nur Sie haben diese Zahlen | „Wir befragten 500 Marketingleiter und fanden..." |
| Proprietäre Benchmarks | Ohne Ihre Daten nicht replizierbar | „Unsere Analyse von 1.000+ Markenmonitors zeigt..." |
| Einzigartige Methoden | Ihr Framework, Ihr geistiges Eigentum | Das T.R.U.S.T. Framework selbst |
| Ersthand-Fallstudien | Ihre Kunden, Ihre Ergebnisse | Anonymisierte Erfolgsgeschichten mit echten Metriken |
| Branchenspezifische Datensätze | Nischenwissen, das allgemeiner KI fehlt | Vertikalspezifische Trenddaten und Erkenntnisse |
Wenn eine KI spezifische Daten zitieren muss, muss sie die Quelle zuschreiben. Proprietäre Daten erzeugen Zitierungsgravitation — einen Sog zu Ihrem Content, der über Modellupdates hinweg bestehen bleibt.
Forschung von Petroni et al. („Language Models as Knowledge Bases?," EMNLP 2019) zeigt, dass LLMs stärkere Assoziationen mit distinktivem, faktischem Content entwickeln als mit generischen Reformulierungen. Einzigartigkeit erhöht die Memorisierungswahrscheinlichkeit.
Strategie 3: Der Korroborations-Schild
Wie wir in unserem Leitfaden zu Trainingsdaten-SEO erkundet haben, vergeben KI-Modelle Vertrauen basierend auf Korroboration — dem Finden derselben Fakten über mehrere unabhängige Quellen.
Die Korroborations-Vertrauenskurve
| Anzahl unabhängiger Quellen | KI-Vertrauenslevel |
|---|---|
| 1 (nur Ihre Website) | Niedrig — Modell qualifiziert mit „einige Quellen deuten an..." |
| 2-3 (Website + 1-2 externe) | Moderat — Modell zitiert mit angemessenem Vertrauen |
| 5+ (Website + Bewertungen + Presse + Reddit + Wikipedia) | Hoch — Modell formuliert als etablierte Tatsache |
| 10+ (gesättigte Korroboration) | Sehr hoch — selbst Modellupdates dislozieren Sie selten |
Die Vertrauenskurve ist nicht linear — sie folgt einem logarithmischen Muster. Der Sprung von 1 auf 3 Quellen erzeugt mehr Stabilitätsgewinn als der Sprung von 7 auf 10. Konzentrieren Sie Ihre anfängliche Mühe darauf, in 3-5 hochgewichtigen Quellen korroboriert zu werden, bevor Sie sich dünn verteilen.
Praktische Korroborationsaktionen
- Stellen Sie sicher, dass Ihre Kernaussagen erscheinen auf Ihrer Website, Wikipedia (wenn berechtigt), mindestens 2 Bewertungsplattformen und 1+ Branchenpublikation
- Bauen Sie Ihre Entity-Präsenz auf über Wikidata, Crunchbase, LinkedIn-Unternehmensseite und Google Knowledge Panel
- Verdienen Sie authentische Erwähnungen in Reddit-Diskussionen — keine Marketing-Posts, sondern hilfreiche Community-Beiträge
Strategie 4: Das trendbasierte Reporting-Framework
Die wohl unmittelbar umsetzbarste Strategie: Ändern Sie, wie Sie KI-Performance an Stakeholder berichten.
Warum traditionelles Reporting versagt
Wenn Ihr CMO fragt „Was ist unser Ranking in ChatGPT?", ist die ehrliche Antwort komplex. Aber Komplexität fliegt nicht in Vorstandssitzungen.
Traditionelles SEO-Reporting funktioniert, weil das zugrundeliegende System relativ stabil ist:
- „Wir ranken #3 für [Keyword]" — aussagekräftig, verifizierbar, stabil
- „Unser Ranking verbesserte sich von #7 auf #4" — klare Richtung
KI-Reporting erfordert einen Paradigmenwechsel, weil das zugrundeliegende System probabilistisch ist:
- „Unsere Sichtbarkeitsrate diese Woche ist 52%" — Momentaufnahme, unvollständig
- „Unser 4-Wochen-Durchschnitt der Sichtbarkeit ist 50%, gestiegen von 42% letztes Quartal" — Trend, aussagekräftig
Das empfohlene Executive Dashboard
| Metrik | Diese Periode | Vorherige | 4-Wochen-MA | Trend |
|---|---|---|---|---|
| KI-Sichtbarkeitsrate | 52% | 48% | 50% | ↗️ Verbessernd |
| Stimmungs-Score | 8,2/10 | 8,0/10 | 8,1/10 | → Stabil |
| Cross-Modell-Abdeckung | 4/5 Modelle | 3/5 | 3,5/5 | ↗️ Verbessernd |
| Wettbewerber A Sichtbarkeit | 45% | 47% | 46% | ↘️ Rückläufig |
| Volatilitätsband | ±8% | ±12% | ±10% | ↗️ Stabilisierend |
Beachten Sie die Schlüsselinnovation: Das Volatilitätsband (±%) ist selbst eine Metrik. Ein schrumpfendes Volatilitätsband bedeutet, dass sich Ihre Position festigt — ein besseres Ergebnis als eine höhere Sichtbarkeitszahl mit breiteren Schwankungen.
Die „Wettervorhersage"-Analogie
„Ihre KI-Sichtbarkeit ist wie eine Wettervorhersage. Wenn wir sagen, es gibt 70% Regenwahrscheinlichkeit, und es regnet nicht, hatten wir dann Unrecht? Nein — wir hatten zu 30% Recht, was immer möglich war. Ähnlich, wenn unsere KI-Sichtbarkeitsrate 50% beträgt, erwarten wir, in etwa der Hälfte der relevanten Anfragen zu erscheinen. Manche Tage werden es 40% sein, manche 60%. Der 4-Wochen-Durchschnitt verrät uns das wahre Klima."
Strategie 5: Volatilitätsfenster ausnutzen
Hier die kontraintuitive Erkenntnis: Volatilität ist nicht nur eine Bedrohung. Sie ist eine Chance.
Die „Offenes Fenster"-Theorie
Wenn KI-Empfehlungen perfekt stabil wären — wie die alte Google-Seite-Eins — wären Top-Incumbents permanent festgeschrieben. Neueinsteiger hätten keinen Weg zur Sichtbarkeit.
Aber Volatilität schafft Gelegenheitsfenster:
| Volatilitätsereignis | Was es bedeutet | Ihr Zug |
|---|---|---|
| Modellupdate mischt Rankings | Top-Positionen sind temporär „entsperrt" | Ihren stärksten Content sofort deployen |
| Sichtbarkeit des Wettbewerbers sinkt | KI „vergisst" ihn vorübergehend | Ihr Signal auf seinen geschwächten Anfragen erhöhen |
| Neue Anfragekategorie entsteht | Kein Incumbent hat Autorität etabliert | Autoritativen Content schnell für First-Mover-Vorteil erstellen |
| RAG-Quellenrotation | Die KI betrachtet andere Quellen | Sicherstellen, dass Sie über mehr Quellen präsent sind |
Timing Ihrer Aktionen
Größere Modellupdates werden oft angekündigt (oder von der Community innerhalb von Stunden erkannt). Wenn ein Update kommt:
- Sofort überwachen — AICarma-Nutzer erhalten automatisierte Alerts bei signifikanten Metrikverschiebungen
- Innerhalb von 48 Stunden bewerten — Ist der Shift vorteilhaft (Chance) oder nachteilig (Bedrohung)?
- Innerhalb einer Woche handeln — Neuen Content deployen, bestehende Seiten aktualisieren, schwächere Pfeiler stärken
- Innerhalb von 2 Wochen messen — Hat die Reaktion Ihre Position stabilisiert?
Die Wissenschaft der KI-Instabilität
Für technisch Interessierte: Warum KI-Ergebnisse fundamental volatil sind.
Temperatur und Nucleus Sampling
LLMs generieren Text, indem sie das nächste wahrscheinlichste Token vorhersagen. Der Temperatur-Parameter kontrolliert, wie „kreativ" diese Vorhersage ist:
- Temperatur 0,0: Wählt immer das wahrscheinlichste Token (deterministisch, minimale Variation)
- Temperatur 0,7: Sampled aus einem breiteren Bereich wahrscheinlicher Tokens (ausgewogen)
- Temperatur 1,0+: Sampled breit, einschließlich niedrigwahrscheinlicher Tokens (kreativ, hohe Varianz)
Wie von Holtzman et al. dokumentiert („The Curious Case of Neural Text Degeneration," ICLR 2020), erzeugen selbst moderate Temperatureinstellungen bedeutsame Output-Variation bei wiederholten Durchläufen mit identischen Eingaben.
Sie können die Temperatur nicht kontrollieren — nur der KI-Anbieter kann das. Aber Sie können so eine starke Wahrscheinlichkeitsmasse um Ihre Marke aufbauen, dass selbst hochtemperiertes Sampling Sie häufig auswählt.
Modellupdate-Frequenz
Chen et al. („How is ChatGPT's Behavior Changing Over Time?," 2023) verfolgten GPT-3.5- und GPT-4-Verhalten über Monate und fanden signifikanten Verhaltens-Drift — selbst zwischen nominell identischen Modellversionen. Dieser „stille Drift" bedeutet, dass sich Ihre Sichtbarkeit ohne angekündigtes Update verschieben kann.
Die Implikation: Kontinuierliches Monitoring ist nicht optional. Es ist die einzige Möglichkeit, stille Veränderungen zu erkennen, bevor sie sich aufschaukeln.
Eine antifragile Marke aufbauen
Das ultimative Ziel ist nicht nur das Überleben der Volatilität — es ist antifragil zu werden (Taleb, Antifragile, Random House, 2012): eine Marke, die tatsächlich von Instabilität profitiert.
Antifragile Marken teilen diese Merkmale:
- Tiefe Entity-Präsenz: Ihr Knowledge-Graph-Profil ist so stark, dass selbst größere Modellupdates ihre Assoziationen bewahren
- Multi-Quellen-Korroboration: Sie werden auf 10+ unabhängigen Quellen zitiert, was Einzelquellen-Disruption irrelevant macht
- Proprietäre Daten: Sie besitzen einzigartige Informationen, die KI ihnen zuschreiben muss
- Diversifizierte Modellabdeckung: Sie erscheinen über alle großen Modelle, nicht nur eins
- Schnelle Reaktionsfähigkeit: Sie erkennen Veränderungen in 48 Stunden und deployen Reaktionen innerhalb einer Woche (GEO-Kreislauf)
Branchenspezifische Volatilitäts-Playbooks
Verschiedene Branchen sehen sich unterschiedlichen Volatilitätsprofilen gegenüber. Passen Sie Ihre Strategie entsprechend an:
Niedrige Volatilität: Gesundheit & Finanzen
Warum: KI wendet strenge YMYL-Sicherheitsfilter an. Empfehlungen sind konservativ und ändern sich langsam. Strategie: Stark in den Vertrauenspfeiler investieren. Einmal etabliert, sind Positionen dauerhaft. Aber der Einstieg ist absichtlich schwer.
Mittlere Volatilität: SaaS & B2B
Warum: Mehrere vergleichbare Optionen mit qualitativ hochwertiger Dokumentation und Bewertungen. Strategie: Über proprietäre Benchmarks differenzieren. SaaS-GEO-Leitfaden behandelt dies ausführlich.
Hohe Volatilität: E-Commerce & Lokal
Warum: Preise, Verfügbarkeit und Bewertungen ändern sich ständig. Strategie: Geschwindigkeit und Frische zählen mehr. Aktuelle Bewertungen und strukturierte Echtzeitdaten pflegen.
FAQ
Sollte ich meine KI-Sichtbarkeit täglich prüfen?
Nein. Tägliche Prüfungen erzeugen Angst ohne Information. Tägliche Schwankungen sind meist Rauschen — ein Effekt von Temperature-Sampling und Retrieval-Varianz. Prüfen Sie wöchentliche gleitende Durchschnitte. Ausnahme: Wenn Ihr Alerting-System einen Einbruch über 30% meldet, sofort untersuchen.
Die Sichtbarkeit meines Wettbewerbers ist nach einem Modellupdate gestiegen. Sollte ich in Panik verfallen?
Nicht sofort. Modellupdates erzeugen oft temporäre Umschichtungen. Geben Sie 2 Wochen, bevor Sie die Veränderung als dauerhaft einschätzen. Analysieren Sie in der Zwischenzeit, warum sie gewonnen haben — haben sie neuen Content veröffentlicht? Eine neue autoritative Zitation verdient? Dann strategisch reagieren, nicht reaktiv.
Wie viel Volatilität ist „normal"?
Für Kategorieanfragen in kompetitiven Märkten erwarten Sie ±15-20% Woche-zu-Woche-Variation als Baseline. Liegt Ihre Volatilität konstant unter ±10%, ist Ihre Position stark. Über ±25% ist Ihre Position fragil und braucht Korroborationsarbeit.
Kann ich Volatilitätsdaten nutzen, um Modellupdates vorherzusagen?
Manchmal. Wenn Volatilität gleichzeitig über mehrere Marken der gleichen Kategorie spiken — aber es keine offensichtliche Content-Änderung einer von ihnen gibt — deutet das oft auf ein Modellupdate oder eine Retrieval-System-Änderung hin.
Was ist das Wichtigste für Volatilitätsresilienz?
Entity-Stärke. Eine starke, gut korroborierte Marken-Entität überlebt Modellupdates besser als alles andere. Entitäten sind die persistenteste Wissenseinheit in LLMs — sie sind in die Gewichte eingebettet, quellenübergreifend korroboriert und resistent gegen Retrieval-Rauschen.