Model Polling: Wie synthetische Befragte Fokusgruppen ersetzen
Letzte Aktualisierung: 2. November 2025
Was wäre, wenn Sie eine Fokusgruppe mit 10.000 Teilnehmern durchführen könnten — jeder repräsentiert ein distinktives demografisches Profil — und Ergebnisse in Stunden statt Monaten hätten? Was wäre, wenn diese Teilnehmer nie Ermüdung erleben, nie versuchen, dem Moderator zu gefallen, und immer ehrlich über sensible Themen antworten würden?
Das ist kein Gedankenexperiment. Es passiert jetzt in Enterprise-Forschungsabteilungen weltweit, und es heißt Model Polling.
Inhaltsverzeichnis
- Das Konzept synthetischer Befragter
- Wie LLMs zu Fokusgruppen-Teilnehmern werden
- Der Multi-Modell-Vorteil
- Echtzeit-Datenintegration: Die RAG-Architektur
- Genauigkeit und Validierung
- Technische Architektur für Enterprises
- FAQ
Das Konzept synthetischer Befragter
Traditionelle Marktforschung basiert auf einer fundamentalen Annahme: Um Verbraucher zu verstehen, muss man Verbraucher fragen. Diese Annahme trieb eine Multi-Milliarden-Dollar-Industrie von Panels, Umfragen und Fokusgruppen an.
Model Polling stellt dieses Paradigma mit einer revolutionären Prämisse heraus: Large Language Models, die auf dem gesamten öffentlichen Internet trainiert wurden, enthalten ein komprimiertes Modell der menschlichen Gesellschaft selbst.
Wenn ein LLM wie GPT-4 oder Claude Text generiert, schöpft es aus Mustern, die aus Milliarden menschlich geschriebener Dokumente gelernt wurden — Forumsdiskussionen, Produktbewertungen, Social-Media-Posts, akademische Arbeiten. In einem bedeutsamen Sinne haben diese Modelle mehr Verbrauchermeinungen „gelesen" als jeder menschliche Forscher in tausend Lebenszeiten aufnehmen könnte.
Synthetische Personas in der Praxis
Statt 500 Personen zu rekrutieren und sie für die Umfrageteilnahme zu bezahlen, erstellen Enterprise-Unternehmen jetzt synthetische Personas. Mit spezialisierten System-Prompts kann ein einzelnes Modell diverse demografische und psychografische Profile simulieren:
Prompt-Beispiel:
„Sie sind ein 42-jähriger Vorstadtvater mit drei Kindern, Haushaltseinkommen 120.000€, besorgt über Fahrzeugsicherheit und Kraftstoffeffizienz. Sie fahren einen VW Tiguan Baujahr 2019 und erwägen Ihren nächsten Kauf. Antworten Sie als diese Person auf die folgende Frage..."
Dasselbe Modell kann sofort werden:
„Sie sind ein 23-jähriger urbaner Berufstätiger, umweltbewusst, absichtlich autolos lebend, erwägen aber den Kauf eines ersten Fahrzeugs für Wochenendausflüge..."
Innerhalb von Minuten können Forscher tausende dieser Personas simulieren, wobei jede dieselben Fragen aus ihrer einzigartigen Perspektive beantwortet.
Wie LLMs zu Fokusgruppen-Teilnehmern werden
Der Ansatz synthetischer Befragter bietet fundamentale Vorteile gegenüber traditionellen Methoden:
| Dimension | Traditionelle Fokusgruppe | Synthetische Befragte |
|---|---|---|
| Zeit bis zu Erkenntnissen | 6-10 Wochen | Stunden |
| Kosten pro Befragtem | 50-200€ | <0,10€ |
| Stichprobengrößen-Limits | Logistisch begrenzt | Unbegrenzt |
| Beobachtereffekt | Vorhanden | Absent |
| Soziale Erwünschtheits-Bias | Signifikant | Eliminiert |
| Ehrlichkeit bei sensiblen Themen | Variabel | Konsistent |
| Skalierbarkeit | Lineare Kosten | Nahezu null Grenzkosten |
Der Bias-Eliminierungsfaktor
Menschliche Befragte bringen unvermeidbare Verzerrungen in Forschungssettings ein. Sie versuchen, konsistent zu erscheinen. Sie wollen Interviewern gefallen. Sie werden von dem beeinflusst, was andere im Raum sagen. Sie modifizieren Antworten bei sensiblen Themen wie Finanzen, Gesundheit oder kontroversen Präferenzen.
Synthetische Befragte haben keine dieser Beschränkungen. Ein Modell, das einen konservativen Wähler und einen progressiven Wähler simuliert, gibt genuinely unterschiedliche Antworten — keine performativen, die darauf abzielen, Gruppenzugehörigkeit zu signalisieren.
Zufriedenheitsraten
Forschung von Enterprise-Early-Adopters zeigt 87% Zufriedenheitsraten unter Teams, die synthetische Daten nutzen, wobei viele eine hohe Korrelation zwischen synthetischen Vorhersagen und tatsächlichem Marktverhalten berichten.
Der Multi-Modell-Vorteil
Frühe Anwender entdeckten schnell, dass die Abhängigkeit von einem einzelnen LLM blinde Flecken erzeugte. Jedes Modell hat andere Trainingsdaten, andere Biases und andere Antwortmuster. Die Lösung: Multi-Modell-Polling.
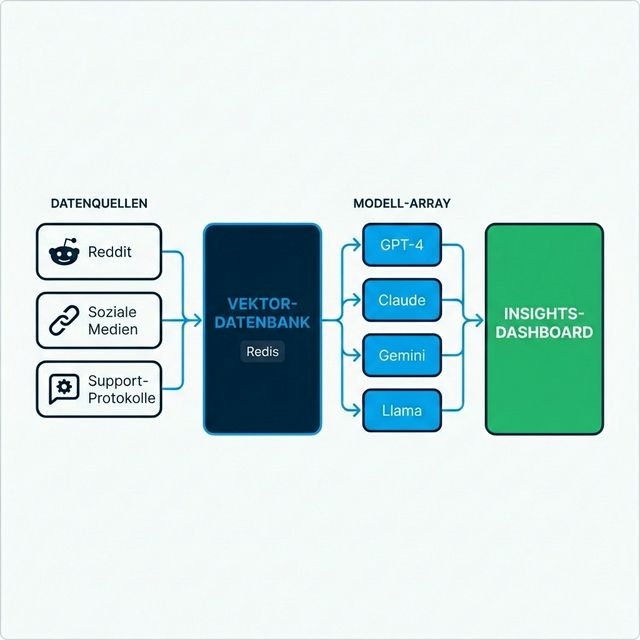
Anstatt ein Modell abzufragen, befragen ausgefeilte Enterprise-Systeme Arrays von Modellen gleichzeitig:
- GPT-4 und GPT-4o von OpenAI
- Claude 3.5 von Anthropic
- Gemini von Google
- Llama 3 und andere Open-Source-Modelle
Antwortmuster werden dann analysiert auf:
- Konsens: Wo Modelle übereinstimmen, steigt die Konfidenz
- Divergenz: Uneinigkeit signalisiert Bereiche, die menschliche Untersuchung erfordern
- Modellspezifische Biases: Bekannte Tendenzen werden herausgerechnet
Dieser Multi-Modell-Ansatz spiegelt wider, wie Enterprises die Markensichtbarkeit über KI-Plattformen monitoren — in der Erkenntnis, dass verschiedene Modelle radikal unterschiedliche „Perspektiven" zum selben Thema haben können.
Echtzeit-Datenintegration: Die RAG-Architektur
Die leistungsstärksten synthetischen Forschungssysteme verlassen sich nicht allein auf Modell-Trainingsdaten. Sie integrieren Echtzeit-Informationen durch Retrieval-Augmented Generation (RAG).
Wie RAG Model Polling transformiert
Traditionelle LLMs haben einen Wissensabschnitt-Datum — sie können nur wissen, was in ihren Trainingsdaten existierte. RAG überwindet diese Limitation:
- Live-Datenerfassung: Systeme sammeln kontinuierlich Daten von Reddit, Twitter/X, Bewertungsseiten, Support-Logs und Nachrichtenquellen
- Vektorisierung: Diese Daten werden in mathematische Embeddings konvertiert und in Vektordatenbanken gespeichert (oft Redis für Geschwindigkeit)
- Kontextuelles Retrieval: Wenn eine synthetische Persona abgefragt wird, werden relevante aktuelle Daten abgerufen und in den Prompt injiziert
- Fundierte Generierung: Das Modell generiert Antworten, informiert durch die Forumsposts von gestern, nicht durch zwei Jahre alte Trainingsdaten
Beispiel: Bei der Frage „Was denken Verbraucher über die neue Preisgestaltung von [Marke X]?" — halluziniert das Modell nicht aus Trainingsdaten. Es synthetisiert tatsächliche Social-Media-Diskussionen der letzten 24 Stunden.
Diese Architektur ist eng verwandt mit der RAG-Optimierung von Content für KI-Auffindbarkeit, aber in umgekehrter Anwendung: Statt Content für KI auffindbar zu machen, machen Enterprises KI-Erkenntnisse für Menschen verwertbar.
Genauigkeit und Validierung
Die natürliche Frage: Wie genau sind synthetische Befragte im Vergleich zu echten Menschen?
Validierungsstudien
Enterprise-Teams, die synthetische Forschung nutzen, berichten starke Performance über mehrere Dimensionen:
| Metrik | Typische Performance |
|---|---|
| Richtungsgenauigkeit | 80-90% Übereinstimmung mit realen Umfrageergebnissen |
| Ranking-Genauigkeit | Synthetische Befragte ordnen Präferenzen ähnlich wie Menschen |
| Trenderkennung | Frühere Identifikation aufkommender Stimmungswechsel |
| Ausreißer-Identifikation | Bessere Identifikation von Randfällen und Nischensegmenten |
Wo Menschen noch gewinnen
Synthetische Befragte excellieren bei der Aggregation bekannter Muster, können aber Schwierigkeiten haben mit:
- Genuinely neuartigen Produktkategorien ohne historische Diskussion
- Tiefen emotionalen Dynamiken, die Empathie erfordern
- Kulturellen Nuancen spezifisch für sehr enge Communities
Die aufkommende Best Practice ist hybride Validierung: Synthetische Befragte für Geschwindigkeit und Skalierung nutzen, kritische Entscheidungen mit gezielter menschlicher Forschung validieren.
Dies spiegelt den Human-in-the-Loop-Ansatz wider, der für Hochrisiko-KI-Anwendungen empfohlen wird.
Technische Architektur für Enterprises
Der Aufbau von Enterprise-grade Model-Polling-Infrastruktur erfordert ausgefeiltes Engineering. Die Komplexität überrascht Organisationen, die versuchen, in-house aufzubauen, häufig.
Kernkomponenten
1. Daten-Ingestionsschicht
- API-Verbindungen zu Social-Plattformen, Foren, Bewertungsaggregatoren
- Echtzeit-Streaming vs. Batch-Verarbeitungsentscheidungen
- Datenbereinigung und Deduplizierung
2. Vektordatenbank
- Speicherung für Embeddings im großen Maßstab
- Millisekunden-Retrieval-Latenzanforderungen
- Oft Redis, Pinecone oder Weaviate
3. Modell-Orchestrierungsschicht
- Einheitliche API-Abstraktion über Anbieter hinweg
- Prompt-Management und Versionierung
- Rate-Limiting und Kostenkontrolle
- Fallback-Routing bei Anbieterausfällen
4. Analytics und Monitoring
- Antwortqualitäts-Scoring
- Halluzinationserkennung
- Cross-Modell-Konsistenzanalyse
- Executive-Dashboard und Alerting
Integrations-Herausforderungen
Verschiedene LLM-Anbieter (OpenAI, Anthropic, Google) haben inkompatible APIs, unterschiedliche Rate-Limits und variierende Antwortformate. Ohne eine Middleware-Abstraktionsschicht werden Codebasen mit anbieterspezifischen Anpassungen verwickelt.
Plattformen wie AICarma haben Jahre in den Aufbau dieser Abstraktionsschichten investiert — wodurch Enterprises sofort 10+ Modelle befragen können, statt Monate mit Integrations-Engineering zu verbringen. Die erforderlichen Architekturmuster spiegeln die für Multi-Modell-Marken-Monitoring benötigten wider, was integrierte Lösungen besonders wertvoll macht.
FAQ
Können synthetische Befragte alle menschliche Forschung ersetzen?
Nicht vollständig. Sie excellieren bei Geschwindigkeit, Skalierung und Musteraggregation. Jedoch profitieren genuinely neuartige Szenarien, tiefe emotionale Exploration und kulturspezifische Nuancen weiterhin von menschlicher Beteiligung. Der optimale Ansatz ist hybrid: Synthetisch für Breite und Geschwindigkeit, menschlich für Tiefe und Validierung.
Wie verhindert man Modell-„Halluzinationen" in Forschungsantworten?
RAG-Architektur verankert Antworten in realen Daten. Multi-Modell-Polling identifiziert Ausreißer. Konfidenz-Scoring markiert unsichere Antworten. Kombiniert reduzieren diese Techniken das Halluzinationsrisiko signifikant — obwohl Monitoring essenziell bleibt.
Wie ist der Kostenvergleich mit traditioneller Forschung?
Synthetische Forschung kostet typischerweise 10-25% der traditionellen Methoden. Eine Studie, die möglicherweise 200.000€ an Panel-Gebühren, Anreizen und Agenturkosten erfordert, kann oft für 20.000-50.000€ an API-Kosten und Plattformgebühren approximiert werden — mit Ergebnissen in Tagen statt Monaten.
Sind die Daten für regulatorische oder Vorstands-Zwecke verteidigbar?
Das variiert je nach Kontext. Synthetische Daten werden zunehmend für Richtungsweisungen und schnelle Iteration akzeptiert. Für regulierte Branchen oder Vorstandsentscheidungen bieten hybride Ansätze, die menschliche Validierung einschließen, die Verteidigbarkeit traditioneller Methoden.
Welche Infrastruktur ist zum Start erforderlich?
Enterprises können von Grund auf bauen oder Plattformen kaufen. Eigenentwicklung erfordert ML-Engineering-Talent, Multi-Anbieter-API-Management, Vektordatenbank-Expertise und laufende Wartung. Plattformen bieten schnelleres Deployment, aber weniger Anpassung. Die meisten Fortune-500-Unternehmen wählen Plattformen wegen des schnelleren Time-to-Value.
Model Polling repräsentiert einen fundamentalen Wandel darin, wie Enterprises Märkte verstehen. Die Unternehmen, die diese Fähigkeit heute meistern, bauen Wettbewerbsvorteile auf, die sich über die Zeit potenzieren — Marktverschiebungen schneller sehen, Hypothesen günstiger testen und Entscheidungen mit einem Vertrauen treffen, das ihre langsameren Wettbewerber nicht aufbringen können.