RAG SEO: Der vollständige Leitfaden zur Content-Erstellung für Retrieval-Augmented Generation
Letzte Aktualisierung: 18. October 2025
Hier ist ein Szenario, das sich tausendfach am Tag abspielt: Ein potenzieller Kunde fragt Perplexity: „Was ist das beste Projektmanagement-Tool für Remote-Teams?" Die KI durchsucht das Web, ruft Schnipsel von Hunderten von Seiten ab und synthetisiert eine Antwort.
Ihre Seite rangierte auf Platz 3 bei Google für genau diese Anfrage. Aber die KI hat Sie nicht zitiert. Sie zitierte einen Wettbewerber, dessen Seite für Retrieval optimiert war, nicht nur für Ranking.
Willkommen in der Welt des RAG SEO — einer Disziplin, die schnell so wichtig wird wie traditionelles SEO, aber bei den meisten Marketing-Teams noch fast völlig unbekannt ist.
RAG (Retrieval-Augmented Generation) ist die Technologie, die eingefrorene KI-Modelle mit Live-Daten verbindet. So kann ChatGPT Fragen zu Ereignissen von gestern beantworten. So liefert Perplexity Echtzeit-Suchergebnisse. Und so funktionieren zunehmend auch Googles KI-Übersichten.
Wenn Sie möchten, dass KI Ihre Inhalte zitiert, müssen Sie verstehen, wie RAG-Systeme denken — und Ihre Inhalte entsprechend umstrukturieren. Unternehmen nutzen RAG-Architekturen zunehmend nicht nur für Content-Retrieval, sondern auch für synthetische Marktforschung durch Multi-Modell-Polling.
Inhaltsverzeichnis
- Was ist RAG und warum ist es wichtig?
- Die RAG-Pipeline: Wie KI Ihre Inhalte „liest"
- Das „Lost in the Middle"-Phänomen
- Der Retrievability-Faktor: Ihre neue Ranking-Metrik
- Content-Chunking: Schreiben für KI-Konsum
- Semantische Dichte: Die Qualitätsmetrik, die KI misst
- Tabellen, Listen und strukturierte Formate
- Praktische RAG-Optimierungs-Checkliste
- RAG-Performance messen
- FAQ
Was ist RAG und warum ist es wichtig?
Die meisten Menschen verstehen falsch, wie LLMs funktionieren. Sie stellen sich eine riesige Datenbank voller Fakten vor, die die KI durchsucht. Aber das stimmt nicht.
LLMs sind fundamental generative Systeme. Sie vervollständigen Text basierend auf Mustern, die während des Trainings gelernt wurden. Sie „rufen" keine Fakten ab — sie halluzinieren Text, der auf Basis der Trainingsdaten plausibel erscheint.
Das schafft Probleme:
- Veraltete Informationen: Trainingsdaten haben ein Stichtag
- Halluzinationsrisiko: Das Modell generiert möglicherweise Unsinn, der überzeugend klingt
- Statisches Wissen: Kann Fragen zu aktuellen Ereignissen nicht beantworten
RAG löst diese Probleme, indem es vor der Generierung einen Retrieval-Schritt hinzufügt:
Wie RAG funktioniert

Wo RAG eingesetzt wird
| System | RAG-Implementierung |
|---|---|
| Perplexity | Intensives RAG — durchsucht Web für jede Anfrage |
| ChatGPT (Browse with Bing) | Optionales RAG — Nutzer kann Websuche aktivieren |
| Google KI-Übersichten | Integriertes RAG aus dem Google-Suchindex |
| Claude + Artifacts | RAG für hochgeladene Dokumente |
| Enterprise-KI | Benutzerdefiniertes RAG auf Unternehmens-Wissensdatenbanken |
Die Kernaussage: Wenn Sie nicht für RAG optimiert sind, werden Sie für KI-gestützte Suche zunehmend unsichtbar.
Die RAG-Pipeline: Wie KI Ihre Inhalte „liest"
Das Verständnis der technischen Pipeline hilft Ihnen bei der Optimierung. So verarbeitet ein RAG-System Ihre Inhalte:
Schritt 1: Crawling & Indexierung
Das KI-System (oder seine Suchkomponente) crawlt Webseiten und zerlegt sie in „Chunks" — typischerweise 200-500 Token. Diese Chunks werden in Vektor-Embeddings umgewandelt (mathematische Repräsentationen der Bedeutung).
Ihre Chance: Stellen Sie sicher, dass Ihre Inhalte crawlbar (robots.txt-Optimierung) und so strukturiert sind, dass kohärente Chunks entstehen.
Schritt 2: Anfrage-Verarbeitung
Wenn ein Nutzer eine Frage stellt, wird diese Frage ebenfalls in ein Vektor-Embedding umgewandelt.
Ihre Chance: Schreiben Sie Inhalte, die semantisch mit der Art übereinstimmen, wie Nutzer Fragen formulieren.
Schritt 3: Retrieval
Das System findet Chunks, deren Embeddings mathematisch ähnlich zum Frage-Embedding sind. Normalerweise werden die 5-20 relevantesten Chunks abgerufen.
Ihre Chance: Erstellen Sie Chunks, die häufig gestellte Fragen in Ihrem Bereich direkt beantworten.
Schritt 4: Kontext-Assemblierung
Abgerufene Chunks werden in ein „Kontextfenster" zusammengesetzt, das das LLM für die Antwortgenerierung verwendet.
Ihre Chance: Schreiben Sie eigenständige Absätze, die auch aus dem Kontext herausgenommen Mehrwert bieten.
Schritt 5: Generierung
Das LLM generiert eine Antwort basierend auf dem bereitgestellten Kontext plus seinem Trainingswissen.
Ihre Chance: Integrieren Sie zitierbare, autoritative Aussagen, die das LLM zitieren möchte.
Das „Lost in the Middle"-Phänomen
Eine der wichtigsten Erkenntnisse der RAG-Forschung ist der „Lost in the Middle"-Effekt. Wenn LLMs lange Kontextfenster erhalten, schenken sie die meiste Aufmerksamkeit:
- Dem Anfang des Kontexts
- Dem Ende des Kontexts
- Deutlich weniger der Mitte
Das hat tiefgreifende Auswirkungen auf die Content-Strategie:
Die Aufmerksamkeitskurve
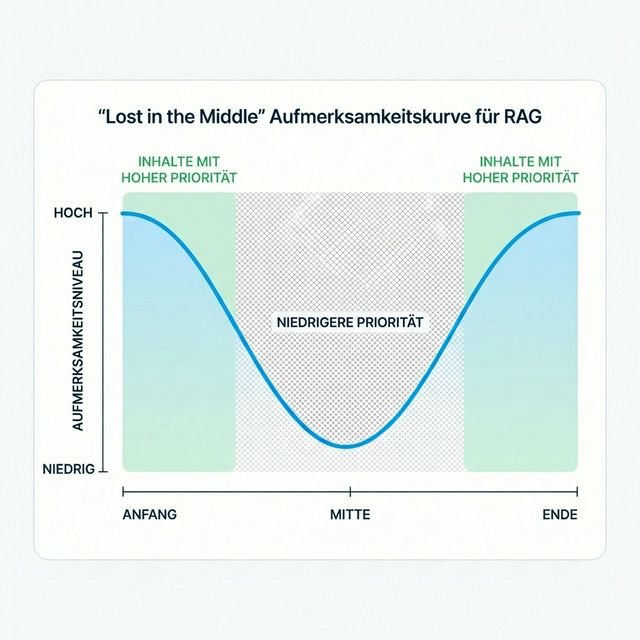
Strategische Implikationen
| Content-Position | KI-Aufmerksamkeitslevel | Was hierher gehört |
|---|---|---|
| Erste 10% des Artikels | HOCH | Schlüsseldefinitionen, Hauptaussagen, TL;DR |
| Mittlere 80% des Artikels | NIEDRIGER | Unterstützende Belege, Beispiele, Tiefe |
| Letzte 10% des Artikels | HOCH | Zusammenfassung, Kernerkenntnisse, Handlungsaufforderungen |
Deshalb erlebt der klassische Journalismus-Stil der „umgekehrten Pyramide" (wichtigste Info zuerst) ein Comeback bei der KI-Optimierung.
Der Retrievability-Faktor: Ihre neue Ranking-Metrik
Bei der Generativen Engine-Optimierung optimieren wir nicht nur für „Lesbarkeit" — wir optimieren für Retrievability (Abrufbarkeit).
Traditionelles SEO fragt: „Wird diese Seite für das Keyword ranken?" RAG SEO fragt: „Werden Chunks dieser Seite für relevante Fragen abgerufen?"
Was macht Content abrufbar?
| Faktor | Beschreibung | Wie optimieren |
|---|---|---|
| Semantische Relevanz | Embedding-Ähnlichkeit zur Anfrage | Fragefokussierte Überschriften verwenden, Nutzersprache spiegeln |
| Informationsdichte | Fakten-zu-Wort-Verhältnis | Fülltext streichen, Fakten in jeden Absatz packen |
| Spezifität | Konkret vs. generisch | Spezifische Zahlen, Namen, Beispiele einbauen |
| Aktualitätssignale | Frischeindikatoren | Content datieren, aktuelles Jahr referenzieren |
| Autoritätsmarker | Glaubwürdigkeitsindikatoren | Quellen zitieren, Expertise zeigen |
Die Retrieval-Lücke
Hier ist die frustrierende Wahrheit: Sie können auf Platz 1 bei Google rangieren und trotzdem niedrige Retrievability haben. Warum?
- Ihre Inhalte könnten für Keyword-Matching optimiert sein, nicht für semantische Bedeutung
- Ihre Schlüsselfakten könnten in aufgeblähten Absätzen vergraben sein
- Ihre Seite beantwortet möglicherweise nicht direkt die Frage, die Nutzer stellen
Beispiel:
- Nutzer fragt: „Was ist das beste CRM für kleine Unternehmen unter 50 €/Monat?"
- Ihre Seite rangiert auf Platz 1 für „bestes CRM kleine Unternehmen"
- Aber Ihre Seite sagt „Vertrieb kontaktieren für Preise"
- KI ruft Wettbewerber ab, dessen Seite sagt „HubSpot Starter: 45 €/Monat"
- Wettbewerber wird zitiert, Sie nicht.
Content-Chunking: Schreiben für KI-Konsum
Die radikalste Veränderung bei der RAG-Optimierung ist, über Ihre Inhalte als Chunks nachzudenken, nicht als Seiten.
Die Regel der eigenständigen Absätze
Jeder Absatz (oder kleine Gruppe von Absätzen) sollte für sich allein verständlich sein. Vermeiden Sie:
| ❌ Vermeiden | ✅ Bevorzugen |
|---|---|
| „Wie im vorherigen Abschnitt erwähnt..." | Kernaussage neu formulieren |
| „Dieses Tool hat mehrere Vorteile..." (vage) | „[Tool-Name] bietet drei Kernvorteile: [auflisten]" |
| „Die Lösung für dieses Problem ist..." | „Die Lösung für das [spezifische Problem] ist [spezifische Lösung]" |
| Verweise auf „oben" oder „unten" | Explizite Links oder vollständiger Kontext |
Warum: Wenn Ihr Absatz als Chunk extrahiert wird, hat die KI möglicherweise keinen Zugang zum vorherigen Absatz. Wenn Ihr Chunk allein keinen Sinn ergibt, wird er nicht nützlich sein — und nicht zitiert.
Das Überschrift-Antwort-Muster
Für jede H2- oder H3-Überschrift sollte der unmittelbar folgende Absatz die vom Header implizierte Frage direkt beantworten.
## Was ist Generative Engine Optimization?
Generative Engine Optimization (GEO) ist die Praxis der Optimierung
von Inhalten und digitaler Präsenz, um in KI-generierten Antworten
von Large Language Models wie ChatGPT, Claude und Gemini zu erscheinen.
Anders als traditionelles SEO, das sich auf Suchmaschinenrankings
konzentriert, fokussiert sich GEO auf Zitierungshäufigkeit und
Empfehlungsinklusion in KI-synthetisierten Antworten.
Dieses Muster ist ideal für RAG, weil:
- Die Überschrift semantischen Kontext liefert
- Der erste Absatz direkt antwortet
- Der Chunk eigenständig und zitierbar ist
Richtlinien für Chunk-Länge
Die meisten RAG-Systeme verwenden Chunks von 200-500 Token (~150-400 Wörtern). Schreiben Sie mit diesem Wissen im Hinterkopf:
- Jeder Hauptabschnitt (H2) sollte ~300-500 Wörter umfassen
- Unterabschnitte (H3) sollten ~150-250 Wörter sein
- Halten Sie Absätze bei 3-5 Sätzen
Länger bedeutet bei RAG nicht besser. Ein 5.000-Wort-Mega-Guide könnte tatsächlich schlechter abschneiden als fünf fokussierte 1.000-Wort-Artikel, weil:
- Semantische Klarheit in fokussierten Artikeln höher ist
- Jeder Artikel sauberere Chunks erzeugt
- Interne Verlinkung zwischen den Artikeln die Beziehung dennoch bewahrt
Semantische Dichte: Die Qualitätsmetrik, die KI misst
Semantische Dichte bezieht sich auf die Menge an bedeutungsvoller, spezifischer Information pro Texteinheit. Es ist vielleicht der wichtigste Faktor bei der RAG-Optimierung.
Niedrige vs. hohe semantische Dichte
| Niedrige Dichte (Schlecht für RAG) | Hohe Dichte (Gut für RAG) |
|---|---|
| „Unsere branchenführende Lösung liefert erstklassige Ergebnisse" | „AICarma überwacht 12 KI-Plattformen einschließlich ChatGPT, Claude und Gemini" |
| „Wir haben vielen Unternehmen zum Erfolg verholfen" | „Wir haben die KI-Sichtbarkeit um 340% für 127 B2B-SaaS-Unternehmen gesteigert" |
| „Wettbewerbsfähige Preise verfügbar" | „Pläne starten bei 299 €/Monat für bis zu 50 verfolgte Anfragen" |
| „Features umfassen erweiterte Funktionen" | „Features: Echtzeit-Monitoring, Stimmungsanalyse, Wettbewerber-Tracking, API-Zugang" |
Das Fülltext-Audit
Gehen Sie Ihre Inhalte durch und identifizieren Sie:
- Füllphrasen: „In der heutigen schnelllebigen Welt", „Es versteht sich von selbst"
- Vage Behauptungen: „Von führenden Unternehmen vertraut", „erstklassig"
- Redundanz: Dasselbe auf mehrere Arten sagen
- Vorrede: Einleitungen, die die eigentliche Information verzögern
Jede davon verwässert Ihre semantische Dichte. In einer Welt, in der KI 300-Wort-Chunks greift, zählt jedes Wort.
Tabellen, Listen und strukturierte Formate
RAG-Systeme können strukturierte Informationen leichter extrahieren und verwenden. Tabellen und Listen sind Gold wert.
Warum Tabellen funktionieren
Tabellen komprimieren Informationen auf eine Weise, die programmatisch leicht zu parsen ist:
| Produkt | Preis | Features | Am besten für |
|---|---|---|---|
| HubSpot | 45 €/Mon. | CRM, E-Mail | Kleine Teams |
| Salesforce | 75 €/Mon. | Komplettpaket | Unternehmen |
| Pipedrive | 29 €/Mon. | Vertriebsfokus | Startups |
Wenn ein Nutzer fragt „Welches CRM kostet weniger als 50 €?", kann ein RAG-System diese Tabellendaten leichter extrahieren und präsentieren als dieselbe Information aus Fließtext zu parsen.
Arten strukturierter Inhalte zum Hinzufügen
- Vergleichstabellen (Feature vs. Feature, Produkt vs. Produkt)
- Preistabellen mit klaren Zahlen
- Datenblätter mit technischen Details
- Zeitplantabellen (wann, was, wer)
- Checklisten-Formate für Prozesse
- Definitionslisten für Fachbegriffe
Listen-Optimierung
Aufzählungs- und nummerierte Listen lassen sich leichter in Chunks aufteilen als Fließtext:
Schlüsselmerkmale GEO-optimierten Contents:
- Eigenständige Absätze, die als Standalone-Chunks funktionieren
- Spezifische, zitierbare Aussagen mit Zahlen und Namen
- Klare Überschrift-Antwort-Muster durchgehend
- Tabellen für vergleichende Daten
- FAQ-Bereiche mit strukturiertem Markup
Praktische RAG-Optimierungs-Checkliste
Verwenden Sie diese Checkliste bei der Erstellung oder Aktualisierung von Inhalten:
Content-Struktur
- [ ] Schlüsseldefinition/Hauptaussage im ersten Absatz
- [ ] Eigenständige Absätze (kein „wie oben erwähnt")
- [ ] Überschrift-Antwort-Muster für alle H2/H3-Abschnitte
- [ ] Zusammenfassung/Kernerkenntnisse am Ende
- [ ] Klare Abschnittsumbrüche alle 300-500 Wörter
Semantische Dichte
- [ ] Alle Füllphrasen und Vorreden entfernt
- [ ] Jeder Absatz enthält mindestens einen spezifischen Fakt
- [ ] Alle Behauptungen sind wo möglich quantifiziert
- [ ] Produkt-/Dienstleistungsnamen sind explizit (nicht „unsere Lösung")
- [ ] Preise sind sichtbar und spezifisch
Strukturierte Daten
- [ ] Mindestens eine Vergleichs-/Datentabelle pro Artikel
- [ ] Aufzählungslisten für Mehrpunkt-Aussagen
- [ ] Schema-Markup auf der Seite
- [ ] FAQ-Bereich mit FAQ-Schema
Benutzerfreundlichkeit
- [ ] Seite lädt in unter 2 Sekunden
- [ ] Inhalte ohne JavaScript verfügbar
- [ ] Mobilfreundliche Darstellung
- [ ] Keine Inhalte hinter Login-Sperren
RAG-Performance messen
Wie wissen Sie, ob Ihre RAG-Optimierung funktioniert?
Direktes Testing
- Fragen Sie Perplexity Ihre Zielfragen
- Notieren Sie, ob Ihre Inhalte zitiert werden
- Verfolgen Sie die Zitierungshäufigkeit über die Zeit
Indirekte Indikatoren
| Metrik | Wo finden | Wonach suchen |
|---|---|---|
| KI-Sichtbarkeits-Score | AICarma | Steigende Zitierungsrate |
| Quellennutzung | AICarmas Quellenattributions-Modul | Welche Domains (Reddit, Wikipedia, News) KI-Empfehlungen beeinflussen |
| Featured Snippets | Google Search Console | P0-Erscheinungen (oft RAG-bezogen) |
| Verweise von KI-Domains | Analytics | perplexity.ai, chat.openai.com Referrer |
| Verweildauer | Analytics | Höher für gut strukturierten Content |
| Absprungrate | Analytics | Niedriger für semantisch klaren Content |
A/B-Testing für RAG
Versuchen Sie dieses Experiment:
- Nehmen Sie eine wichtige Seite
- Erstellen Sie zwei Versionen: Original vs. RAG-optimiert
- Stellen Sie Perplexity dieselbe Frage mit jeder indexierten Version
- Verfolgen Sie, welche öfter zitiert wird
FAQ
Ist RAG SEO dasselbe wie traditionelles SEO?
Nein. Traditionelles SEO hilft Ihnen, von Suchmaschinen-Crawlern gefunden zu werden und für Keywords zu ranken. RAG SEO hilft, dass Ihre Inhalte vom LLM ausgewählt werden, nachdem sie abgerufen wurden. Sie brauchen beides: SEO, um gecrawlt und indexiert zu werden, RAG-Optimierung, um nach dem Retrieval zitiert zu werden.
Spielt die Content-Länge bei RAG eine Rolle?
Kontraintuitiv schlägt kürzer oft länger bei RAG. „Fülltext" schadet der RAG-Performance, weil er das semantische Signal Ihrer Chunks verwässert. Ein prägnanter 800-Wort-Guide kann einen ausschweifenden 3.000-Wort-Beitrag übertreffen. Qualität und Dichte zählen mehr als Länge.
Wie teste ich, ob mein Content RAG-freundlich ist?
Fügen Sie Ihre Inhalte in ChatGPTs Kontextfenster ein und stellen Sie spezifische Fragen basierend auf Ihrem Text. Fragen wie: „Laut diesem Content, was kostet [Produkt]?" oder „Was sind die drei genannten Hauptfeatures?" Wenn die KI Schwierigkeiten hat zu antworten, muss möglicherweise Ihre Content-Struktur überarbeitet werden.
Sollte ich lange Artikel in mehrere kürzere aufteilen?
Oft ja. Eine Serie von 5 verlinkten 1.000-Wort-Artikeln schneidet beim RAG-Retrieval typischerweise besser ab als ein 5.000-Wort-Mega-Guide. Jedes kürzere Stück erzeugt sauberere Chunks mit klarerem semantischen Fokus. Nutzen Sie interne Verlinkung, um die Beziehung zwischen den Teilen zu bewahren.
Wie interagiert RAG mit Schema Markup?
Schema Markup und RAG-Optimierung sind komplementär. Schema hilft dem Crawler zu verstehen, was Ihr Content repräsentiert. RAG-Optimierung stellt sicher, dass Ihre Inhalte für relevante Anfragen ausgewählt werden. Nutzen Sie beides: Schema auf jeder Seite plus RAG-optimierte Content-Struktur durchgehend.