RAG SEO: The Complete Guide to Writing Content for Retrieval-Augmented Generation
Last Updated: October 18, 2025
Here's a scenario that's playing out thousands of times per day: A potential customer asks Perplexity, "What's the best project management tool for remote teams?" The AI searches the web, retrieves snippets from hundreds of pages, and synthesizes an answer.
Your page ranked #3 on Google for that exact query. But the AI didn't cite you. It cited a competitor whose page was optimized for retrieval, not just ranking.
Welcome to the world of RAG SEO—a discipline that's rapidly becoming as important as traditional SEO, yet remains almost completely unknown to most marketing teams.
RAG (Retrieval-Augmented Generation) is the technology that connects frozen AI models to live data. It's how ChatGPT can answer questions about events from yesterday. It's how Perplexity provides real-time search results. And it's increasingly how Google's AI Overviews work.
If you want AI to cite your content, you need to understand how RAG systems think—and restructure your content accordingly. Enterprise organizations are increasingly using RAG architectures not just for content retrieval, but for synthetic market research through multi-model polling.
Table of Contents
- What is RAG and Why Does It Matter?
- The RAG Pipeline: How AI "Reads" Your Content
- The "Lost in the Middle" Phenomenon
- The Retrievability Factor: Your New Ranking Metric
- Content Chunking: Writing for AI Consumption
- Semantic Density: The Quality Metric AI Measures
- Tables, Lists, and Structured Formats
- Practical RAG Optimization Checklist
- Measuring RAG Performance
- FAQ
What is RAG and Why Does It Matter?
Most people misunderstand how LLMs work. They imagine a vast database of facts that the AI searches through. But that's not accurate.
LLMs are fundamentally generative systems. They complete text based on patterns learned during training. They don't "retrieve" facts—they hallucinate text that seems plausible based on training data.
This creates problems:
- Outdated information: Training data has a cutoff date
- Hallucination risk: The model might generate confident-sounding nonsense
- Static knowledge: Can't answer questions about recent events
RAG solves these problems by adding a retrieval step before generation:
How RAG Works

Where RAG is Used
| System | RAG Implementation |
|---|---|
| Perplexity | Heavy RAG—searches web for every query |
| ChatGPT (Browse with Bing) | Optional RAG—user can enable web search |
| Google AI Overviews | Integrated RAG from Google search index |
| Claude + Artifacts | RAG for uploaded documents |
| Enterprise AI | Custom RAG on company knowledge bases |
The key insight: If you're not optimized for RAG, you're increasingly invisible to AI-assisted search.
The RAG Pipeline: How AI "Reads" Your Content
Understanding the technical pipeline helps you optimize for it. Here's how a RAG system processes your content:
Step 1: Crawling & Indexing
The AI system (or its search component) crawls web pages and breaks them into "chunks"—typically 200-500 tokens each. These chunks are converted into vector embeddings (mathematical representations of meaning).
Your opportunity: Ensure your content is crawlable (robots.txt optimization) and structured in ways that create coherent chunks.
Step 2: Query Processing
When a user asks a question, that question is also converted to a vector embedding.
Your opportunity: Write content that semantically matches how users phrase questions.
Step 3: Retrieval
The system finds chunks whose embeddings are mathematically similar to the question embedding. Usually the top 5-20 most relevant chunks are retrieved.
Your opportunity: Create chunks that directly answer common questions in your space.
Step 4: Context Assembly
Retrieved chunks are assembled into a "context window" that the LLM will use to generate its answer.
Your opportunity: Write self-contained paragraphs that provide value even when taken out of context.
Step 5: Generation
The LLM generates an answer based on the provided context plus its training knowledge.
Your opportunity: Include quotable, authoritative statements that the LLM will want to cite.
The "Lost in the Middle" Phenomenon
One of the most important findings in RAG research is the "lost in the middle" effect. When LLMs are given long context windows, they pay the most attention to:
- The beginning of the context
- The end of the context
- Much less attention to the middle
This has profound implications for content strategy:
The Attention Curve
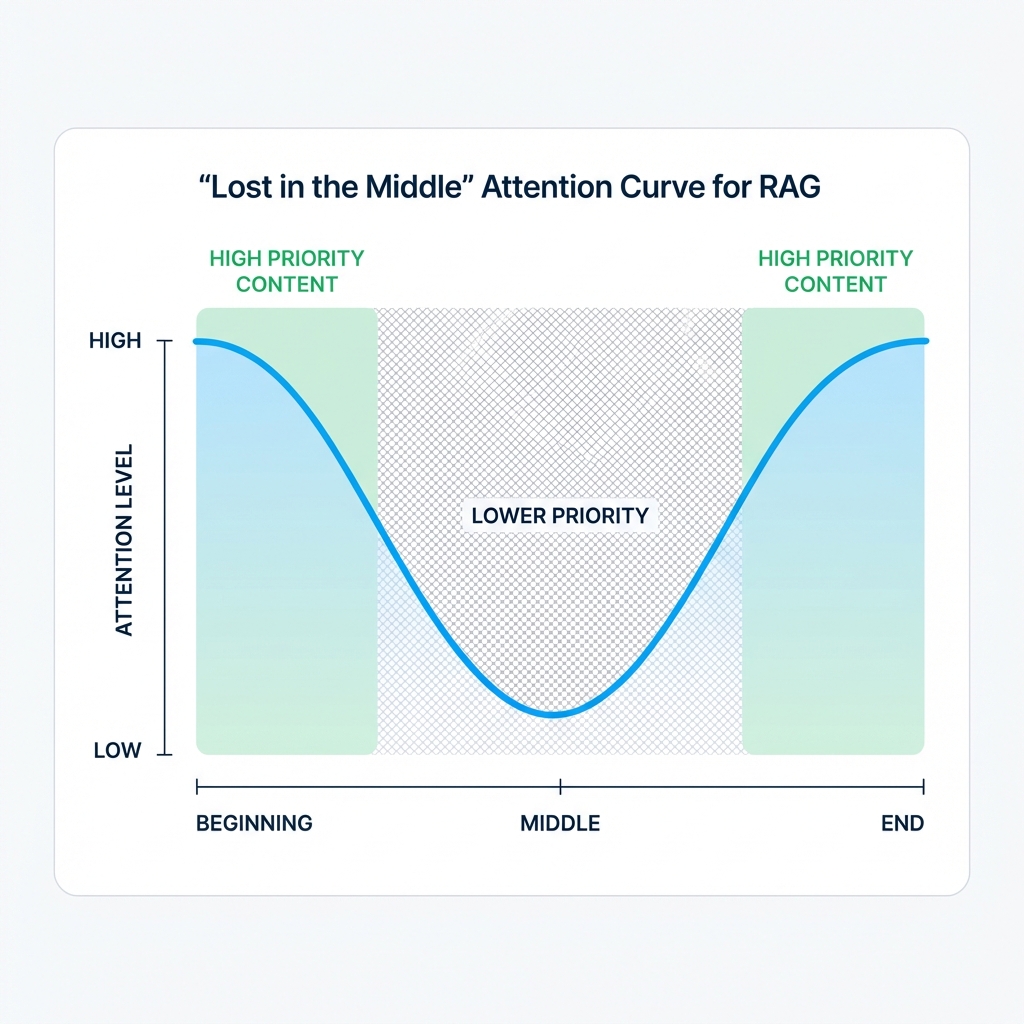
Strategic Implications
| Content Position | AI Attention Level | What to Put Here |
|---|---|---|
| First 10% of article | HIGH | Key definitions, main claims, TL;DR |
| Middle 80% of article | LOWER | Supporting evidence, examples, depth |
| Last 10% of article | HIGH | Summary, key takeaways, calls to action |
This is why the classic journalism "inverted pyramid" style (most important info first) is making a comeback for AI optimization.
The Retrievability Factor: Your New Ranking Metric
In Generative Engine Optimization, we don't just optimize for "readability"—we optimize for retrievability.
Traditional SEO asks: "Will this page rank for the keyword?" RAG SEO asks: "Will chunks of this page be retrieved for relevant questions?"
What Makes Content Retrievable?
| Factor | Description | How to Optimize |
|---|---|---|
| Semantic Relevance | Embedding similarity to query | Use question-focused headers, mirror user language |
| Information Density | Fact-to-word ratio | Cut fluff, pack facts into every paragraph |
| Specificity | Concrete vs. generic | Include specific numbers, names, examples |
| Recency Signals | Freshness indicators | Date content, reference current year |
| Authority Markers | Credibility indicators | Cite sources, show expertise |
The Retrieval Gap
Here's the frustrating truth: you can rank #1 on Google and still have low retrievability. Why?
- Your content might be optimized for keyword matching, not semantic meaning
- Your key facts might be buried in fluffy paragraphs
- Your page might not directly answer the question users are asking
Example:
- User asks: "What is the best CRM for small businesses under $50/month?"
- Your page ranks #1 for "best CRM small business"
- But your page says "Contact sales for pricing"
- AI retrieves competitor whose page says "HubSpot Starter: $45/month"
- Competitor gets cited, you don't.
Content Chunking: Writing for AI Consumption
The most radical shift in RAG optimization is thinking about your content as chunks, not pages.
The Self-Contained Paragraph Rule
Every paragraph (or small group of paragraphs) should be understandable on its own. Avoid:
| ❌ Avoid | ✅ Prefer |
|---|---|
| "As mentioned in the previous section..." | Restate the key point |
| "This tool has several advantages..." (vague) | "[Tool Name] offers three core advantages: [list them]" |
| "The solution to this problem is..." | "The solution to the [specific problem] is [specific solution]" |
| References to "above" or "below" | Explicit links or full context |
Why: When your paragraph is extracted as a chunk, the AI might not have access to the previous paragraph. If your chunk doesn't make sense alone, it won't be useful—and won't be cited.
The Header-Answer Pattern
For every H2 or H3 header, the immediately following paragraph should directly answer the question implied by the header.
## What is Generative Engine Optimization?
Generative Engine Optimization (GEO) is the practice of optimizing
content and digital presence to appear in AI-generated responses
from Large Language Models like ChatGPT, Claude, and Gemini.
Unlike traditional SEO which focuses on search engine rankings,
GEO focuses on citation frequency and recommendation inclusion
in AI-synthesized answers.
This pattern is ideal for RAG because:
- The header provides semantic context
- The first paragraph directly answers
- The chunk is self-contained and quotable
Chunk Length Guidelines
Most RAG systems use chunks of 200-500 tokens (~150-400 words). Write with this in mind:
- Each major section (H2) should cover ~300-500 words
- Subsections (H3) should be ~150-250 words
- Keep paragraphs to 3-5 sentences
Longer doesn't mean better for RAG. A 5,000-word mega-guide might actually perform worse than five 1,000-word focused articles because:
- Semantic clarity is higher in focused pieces
- Each piece creates cleaner chunks
- Internal linking between pieces still preserves the relationship
Semantic Density: The Quality Metric AI Measures
Semantic density refers to the amount of meaningful, specific information per unit of text. It's perhaps the most important factor in RAG optimization.
Low vs. High Semantic Density
| Low Density (Bad for RAG) | High Density (Good for RAG) |
|---|---|
| "Our industry-leading solution provides best-in-class results" | "AICarma monitors 12 AI platforms including ChatGPT, Claude, and Gemini" |
| "We have helped many companies succeed" | "We've increased AI visibility by 340% for 127 B2B SaaS companies" |
| "Competitive pricing available" | "Plans start at $299/month for up to 50 tracked queries" |
| "Features include advanced capabilities" | "Features: real-time monitoring, sentiment analysis, competitor tracking, API access" |
The Fluff Audit
Go through your content and identify:
- Filler phrases: "In today's fast-paced world," "It goes without saying"
- Vague claims: "trusted by leading companies," "best-in-class"
- Redundancy: Saying the same thing multiple ways
- Throat-clearing: Preambles that delay the actual information
Each of these dilutes your semantic density. In a world where AI is grabbing 300-word chunks, every word matters.
Tables, Lists, and Structured Formats
RAG systems have an easier time extracting and using structured information. Tables and lists are gold.
Why Tables Work
Tables compress information in ways that are easy to parse programmatically:
| Product | Price | Features | Best For |
|---|---|---|---|
| HubSpot | $45/mo | CRM, Email | Small teams |
| Salesforce | $75/mo | Full suite | Enterprise |
| Pipedrive | $29/mo | Sales focus | Startups |
When a user asks "What CRM costs less than $50?", a RAG system can more easily extract and present this table data than parsing the same information from flowing prose.
Types of Structured Content to Add
- Comparison tables (feature vs. feature, product vs. product)
- Pricing tables with clear numbers
- Spec sheets with technical details
- Timeline tables (when, what, who)
- Checklist formats for processes
- Definition lists for terminology
List Optimization
Bulleted and numbered lists are easier to chunk than prose:
Key features of GEO-optimized content:
- Self-contained paragraphs that work as standalone chunks
- Specific, quotable claims with numbers and names
- Clear header-answer patterns throughout
- Tables for comparative data
- FAQ sections with structured markup
Practical RAG Optimization Checklist
Use this checklist when creating or updating content:
Content Structure
- [ ] Key definition/claim in first paragraph
- [ ] Self-contained paragraphs (no "as mentioned above")
- [ ] Header-answer pattern for all H2/H3 sections
- [ ] Summary/key takeaways at end
- [ ] Clear section breaks every 300-500 words
Semantic Density
- [ ] Removed all filler phrases and throat-clearing
- [ ] Every paragraph contains at least one specific fact
- [ ] All claims are quantified where possible
- [ ] Product/service names are explicit (not "our solution")
- [ ] Pricing is visible and specific
Structured Data
- [ ] At least one comparison/data table per article
- [ ] Bulleted lists for multi-point claims
- [ ] Schema markup on page
- [ ] FAQ section with FAQ schema
Usability
- [ ] Page loads under 2 seconds
- [ ] Content available without JavaScript
- [ ] Mobile-friendly rendering
- [ ] No content behind login walls
Measuring RAG Performance
How do you know if your RAG optimization is working?
Direct Testing
- Ask Perplexity your target questions
- Note whether your content is cited
- Track citation frequency over time
Indirect Indicators
| Metric | Where to Find | What to Look For |
|---|---|---|
| AI Visibility Score | AICarma | Increasing citation rate |
| Source Usage | AICarma's Source Attribution module | Which domains (Reddit, Wikipedia, news) influence AI recommendations |
| Featured Snippets | Google Search Console | P0 appearances (often RAG-related) |
| Referral from AI domains | Analytics | perplexity.ai, chat.openai.com referrers |
| Time on Page | Analytics | Higher for well-structured content |
| Bounce Rate | Analytics | Lower for semantically clear content |
A/B Testing for RAG
Try this experiment:
- Take an important page
- Create two versions: original vs. RAG-optimized
- Ask Perplexity the same question with each version indexed
- Track which gets cited more often
FAQ
Is RAG SEO the same as traditional SEO?
No. Traditional SEO helps you get found by search engine crawlers and rank for keywords. RAG SEO helps your content get selected by the LLM after it has been retrieved. You need both: SEO to be crawled and indexed, RAG optimization to be cited once retrieved.
Does content length matter for RAG?
Counter-intuitively, shorter often beats longer for RAG. "Fluff" hurts RAG performance because it dilutes the semantic signal of your chunks. A concise 800-word guide might outperform a rambling 3,000-word post. Quality and density matter more than length.
How do I test if my content is RAG-friendly?
Paste your content into ChatGPT's context window and ask it specific questions based on your text. Questions like: "According to this content, what is the price of [product]?" or "What are the three main features mentioned?" If the AI struggles to answer, your content structure may need work.
Should I break long articles into multiple shorter pieces?
Often yes. A series of 5 interlinked 1,000-word articles typically performs better in RAG retrieval than one 5,000-word mega-guide. Each shorter piece creates cleaner chunks with clearer semantic focus. Use internal linking to maintain the relationship between pieces.
How does RAG interact with Schema Markup?
Schema Markup and RAG optimization are complementary. Schema helps the crawler understand what your content represents. RAG optimization ensures your content gets selected for relevant queries. Use both: Schema on every page, plus RAG-optimized content structure throughout.