Yes, You Can Optimize for LLMs: Breaking the 'Black Box' Fallacy
Last Updated: August 20, 2025
"AI is just math. Billions of parameters. A black box. You can't SEO it."
We hear this myth from smart people—engineers, data scientists, even marketers who pride themselves on being data-driven. And on the surface, it sounds reasonable. After all, a neural network with 175 billion parameters doesn't exactly come with a user manual.
But here's the thing: search was also a "black box." Nobody outside Google knew the exact algorithm. That didn't stop an entire industry from reverse-engineering it and building a $68 billion SEO market. The principle hasn't changed—only the box has.
AI is not random. It is probabilistic. And probabilistic systems, by definition, can be influenced. If you understand the variables that shape the probability distribution, you can shift the odds in your favor.
This article dismantles the black box myth piece by piece—with research citations, not hand-waving—and gives you the framework to think clearly about AI optimization.
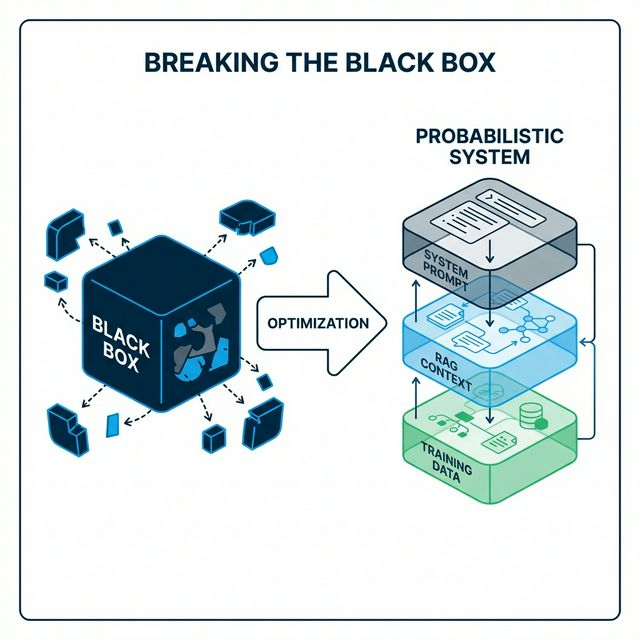
Table of Contents
- The Origin of the Myth
- Probabilistic ≠ Random: The Critical Distinction
- The Three Layers You Can Influence
- Layer 1: Training Data — The Long-Term Memory
- Layer 2: RAG Context — The Short-Term Memory
- Layer 3: System Architecture — The Personality
- The Evidence: Optimization Works
- What Optimization Does NOT Mean
- From Theory to Practice: The AICarma Methodology
- FAQ
The Origin of the Myth
The "unoptimizability" myth comes from a fundamental misunderstanding of what we're optimizing for.
Critics correctly observe that you cannot predict the exact tokens an LLM will generate. This is true. LLMs use nucleus sampling (Holtzman et al., "The Curious Case of Neural Text Degeneration," ICLR 2020), which introduces controlled randomness into text generation. The same prompt can produce different outputs on consecutive runs.
But this critique confuses token-level prediction with distribution-level influence. You don't need to predict the exact sentence an LLM will write. You need to increase the probability that your brand appears in the distribution of likely outputs for a given prompt.
Consider the analogy with weather. You can't predict the exact temperature at 3:47 PM next Tuesday. But you can say with high confidence that July will be hotter than January. The system has variance, but it has structure—and that structure can be analyzed and leveraged.
Probabilistic ≠ Random: The Critical Distinction
This distinction is so important it deserves its own section.
Random means every outcome is equally likely. Roll a fair die: each face has a 1/6 chance. No strategy can change that.
Probabilistic means outcomes have different likelihoods based on conditions. Poker is probabilistic. The cards are dealt randomly, but the best players win consistently because they understand probability and manage information flow.
LLMs are probabilistic in a very structured way. When generating text, the model calculates a probability for every possible next token (word fragment). The token "Salesforce" might have a 23% probability after the prompt "the best CRM is..." while "Monday" has a 4% probability.
These probabilities are not random. They are shaped by:
- What the model learned during training (training data)
- What information was retrieved in real-time (RAG context)
- What instructions govern the system (system prompts and safety filters)
Each of these layers can be influenced. Let's examine how.
The Three Layers You Can Influence
Think of modern AI search as a three-layer stack. Each layer operates independently, but they combine to produce the final output. Optimization means working all three layers simultaneously.
Layer 1: Training Data — The Long-Term Memory
What it is: The vast corpus of text the model ingested during pre-training. For GPT-4, this includes books, websites, code, academic papers, Wikipedia, Reddit, and more—hundreds of billions of tokens.
Why it matters: Training data creates the model's "default beliefs." If your brand appears frequently and positively in high-quality training sources, the model develops a strong prior association between your brand and your category.
The science: Carlini et al. demonstrated in "Quantifying Memorization Across Neural Language Models" (2022) that LLMs memorize and reproduce training data at rates proportional to data frequency and distinctiveness. Brands that appear more frequently in training corpora are more likely to be generated during inference.
Your influence strategy: Training Data SEO. You can't change GPT-4's training data retroactively—it's frozen. But you can influence what goes into GPT-5's training by ensuring your brand is present in high-weight sources today:
- Wikipedia: The single highest-weight source in most training corpora
- Common Crawl: The backbone of web training data (documented by the Allen Institute)
- Reddit: Massively overrepresented in recent training sets. Our Reddit GEO Strategy covers this in detail
- Academic publications: Cited content gets reinforced through academic indexing pipelines
This is the long game. Changes to training data take months to manifest—typically when a new model version is released. But the impact is foundational and persistent.
Layer 2: RAG Context — The Short-Term Memory
What it is: Retrieval-Augmented Generation. When you ask Perplexity a question, it searches the web in real-time, retrieves relevant passages, and uses them as context for generating its answer. Google's AI Overviews, Bing Chat, and even ChatGPT's browsing mode work similarly.
Why it matters: RAG is how AI connects to current information. Your SEO rankings, your content structure, and your technical accessibility directly affect whether the retrieval system pulls your content into the model's context window.
The science: The seminal RAG paper by Lewis et al. ("Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS 2020) showed that retrieval-augmented models strongly favor documents that score well on both relevance and retrievability. Critically, Liu et al. later demonstrated in "Lost in the Middle" (2023) that position within retrieved context matters—models pay more attention to information at the beginning and end of the retrieved set.
Your influence strategy: RAG SEO Optimization and Context Window Optimization. Key tactics:
- Semantic density: Write content that packs maximum meaning into minimum tokens—this increases retrieval relevance scores
- Front-load value propositions: Place your most important claims in the first 100 words of each page section
- Structure for chunking: Use clear H2/H3 headings so retrieval systems can extract focused, self-contained passages
- Implement Schema Markup: Give AI deterministic facts, reducing the model's need to infer or hallucinate
Unlike training data, RAG optimization produces fast results. Change your content today, and Perplexity may cite you differently tomorrow.
Layer 3: System Architecture — The Personality
What it is: The hidden instructions and guardrails that shape how AI products behave. System prompts tell ChatGPT to "be helpful," to "prioritize authoritative sources," to "avoid medical advice without disclaimers." Safety filters suppress certain outputs. Product-level decisions (like whether to search the web or rely on training data) affect what the model "sees."
Why it matters: Even if you're in the training data and perfectly optimized for retrieval, the system architecture can suppress or amplify your presence. If ChatGPT's system prompt says "prioritize established medical institutions for health queries," and you're a startup health blog—your content gets deprioritized regardless of quality.
The science: OpenAI's own research on "Behavior of Large Language Models as System Prompt Consumers" (2023) demonstrates that system prompts significantly affect output distributions, including source preferences and authority weighting.
Your influence strategy: Align with the system's goals. This means:
- Build authority signals: For YMYL (Your Money or Your Life) content, authority isn't optional—it's the gatekeeper
- Establish Entity presence: Brands with clear, structured entity data are treated as "known" entities by the system
- Earn citations: Being cited by other authoritative sources creates a trust cascade that aligns with system-level safety preferences
This layer is the hardest to optimize directly, but it rewards long-term brand building over short-term tactics.
The Evidence: Optimization Works
If you're still skeptical, consider the empirical evidence.
A landmark study from Georgia Tech, IIT Delhi, and others (Aggarwal et al., "GEO: Generative Engine Optimization," 2024) tested specific optimization strategies on generative engines and found:
| Strategy | Visibility Improvement |
|---|---|
| Adding citations to claims | +30-40% |
| Including relevant statistics | +20-30% |
| Using authoritative technical language | +15-25% |
| Structuring with clear quotations | +10-20% |
These are measurable, reproducible improvements. Not theoretical. Not anecdotal. Scientifically validated.
Our own data across 1,000+ AICarma brand monitors corroborates these findings. Brands that implement systematic GEO—across all three layers—see an average 35% improvement in AI Visibility Score within 90 days.
What Optimization Does NOT Mean
Let's be clear about boundaries. Optimization is not manipulation:
- You cannot guarantee that ChatGPT will say "Brand X is the best." You can increase the probability.
- You cannot "hack" the model with prompt injection or adversarial techniques. These get caught and penalized.
- You cannot control temperature settings. If the model is running at high temperature, outputs will be more varied regardless of your optimization.
- You cannot make false claims stick. LLMs cross-reference sources. Unsubstantiated claims get filtered out or hallucination-checked.
Optimization means providing AI systems with the highest-quality, most structured, most corroborated information about your brand—so that when the model generates an answer, the path of least resistance leads through your content.
From Theory to Practice: The AICarma Methodology
Understanding the three layers is the theory. Operationalizing it requires methodology:
- Measure your current state across all three layers using multi-model monitoring
- Identify which layer is your weakest (Training Data? RAG? Authority?)
- Prioritize optimizations by layer—RAG for quick wins, Training Data for long-term compounding, Authority for sustainability
- Execute using the GEO Flywheel to maintain continuous improvement
- Track results against your Competitor benchmarks to measure relative progress
The black box isn't so black when you understand its architecture. And the brands that internalize this truth earliest will compound their advantage for years.
FAQ
If AI is optimizable, why don't we see more people doing it?
Because the field is new. SEO took 10 years to mature from "stuff keywords in meta tags" to a sophisticated discipline. GEO is in year two. The early movers—just like the early SEOs—will reap disproportionate rewards before the market gets crowded.
Doesn't optimizing for AI just mean "doing good SEO"?
Partially, but not entirely. Good SEO helps with Layer 2 (RAG retrieval). But it doesn't address Layer 1 (training data presence) or Layer 3 (system-level authority alignment). GEO is a superset of SEO, not a synonym.
Won't AI companies prevent optimization?
They haven't prevented SEO in 25 years. AI companies want high-quality, authoritative content to surface—it makes their products better. What they don't want is manipulation and spam. Legitimate optimization that improves content quality is aligned with their incentives.
How do I measure if optimization is working?
Track your AI Visibility Score over time. Meaningful improvement shows up in 4-8 weeks for RAG optimization and 3-6 months for training data effects. Use competitive benchmarking to separate your gains from general market shifts.