Otimização de Janela de Contexto: Escrevendo para a 'Curva de Atenção em U'
Última atualização: 5 December 2025
Eis uma frase que vai fazer você repensar como estrutura conteúdo: Large Language Models são ruins em prestar atenção ao meio de documentos longos.
Isso não é um detalhe menor — é uma característica fundamental de como a IA baseada em transformers funciona. Pesquisas têm mostrado consistentemente que LLMs exibem o que é chamado de "curva de atenção em U" — eles prestam mais atenção à informação no início e no fim da janela de contexto, enquanto informação no meio é parcialmente ignorada.
Para criadores de conteúdo, profissionais de marketing e qualquer pessoa tentando ter seu conteúdo citado por IA, isso tem implicações profundas. Se seus fatos-chave estão enterrados no parágrafo 7 de um artigo de 15 parágrafos, a IA pode literalmente não "ver" eles, mesmo que o crawler tenha recuperado sua página.
Entender e otimizar para atenção da janela de contexto é um dos aspectos mais negligenciados da Otimização para Motores Generativos. Vamos corrigir isso.
Índice
- O Fenômeno "Perdido no Meio"
- Como a Atenção da IA Realmente Funciona
- A Curva de Atenção em U
- Implicações para Estrutura de Conteúdo
- A Pirâmide Invertida: Sua Nova Melhor Amiga
- Técnicas Práticas de Reestruturação
- Testando Seu Conteúdo para Risco de Perda no Meio
- Considerações sobre Tamanho da Janela de Contexto
- FAQ
O Fenômeno "Perdido no Meio"
A Pesquisa
Um paper marcante de 2023 de pesquisadores de Stanford, Berkeley e Samaya AI intitulado "Lost in the Middle" demonstrou uma limitação crítica dos LLMs: quando recebem janelas de contexto longas, modelos têm dificuldade em usar informação do meio desse contexto.
Achados Principais:
- Performance cai significativamente quando informação relevante está no meio
- Mesmo modelos com janelas de 4K, 16K ou 32K tokens exibem esse comportamento
- O efeito é pronunciado mesmo em modelos comerciais bem treinados
- Janelas de contexto maiores não resolvem o problema
O Que Isso Significa para Conteúdo
Quando sua página é recuperada por RAG (Geração Aumentada por Recuperação), ela se torna parte da janela de contexto da IA. Se seu ponto de venda principal está no meio da sua página, ele pode ser "perdido" pela atenção do modelo.
| Posição no Documento | Atenção da IA | Probabilidade de Citação |
|---|---|---|
| Primeiros 10% | Alta | Alta |
| Meio 80% | Mais baixa | Reduzida |
| Últimos 10% | Alta | Alta |
Por Que Isso Acontece
Não é um bug — é como mecanismos de atenção de transformers funcionam. O treinamento incentiva modelos a se apoiar em extremos posicionais. Informação no início estabelece contexto; informação no final fornece conclusões. Conteúdo do meio é frequentemente considerado "material de apoio."
Como a Atenção da IA Realmente Funciona
O Mecanismo de Atenção
LLMs usam "atenção" para decidir em quais tokens (palavras/fragmentos) do input focar ao gerar output. Para cada token de saída, o modelo calcula scores de atenção em todos os tokens de entrada.
Em teoria, atenção permite focar em qualquer parte do input. Na prática, padrões de atenção mostram fortes vieses em direção a:
- Recência (tokens próximos)
- Posição (tokens iniciais e finais)
- Relevância semântica (tokens correspondentes)
Embeddings Posicionais
LLMs codificam informação posicional junto com conteúdo. Eles "sabem" que token #1 veio antes do token #1000. Mas vieses dos dados de treinamento significam:
- Tokens iniciais frequentemente recebem mais peso (estabelecem contexto)
- Tokens finais frequentemente recebem mais peso (fornecem conclusões)
- Tokens do meio devem ser excepcionalmente relevantes para superar desvantagem posicional
O Efeito Prático
Imagine que você está escrevendo sobre um produto de software. Sua página tem:
- Parágrafo 1: Introdução da empresa
- Parágrafos 3-7: Descrições de funcionalidades
- Parágrafo 8: Preços
- Parágrafo 10: Conclusão
Se a IA está respondendo "Quanto custa o [Produto]?", a informação de preço no parágrafo 8 (meio) pode receber menos atenção que a intro ou conclusão, mesmo sendo a resposta para a pergunta.
A Curva de Atenção em U
Visualizando o Padrão
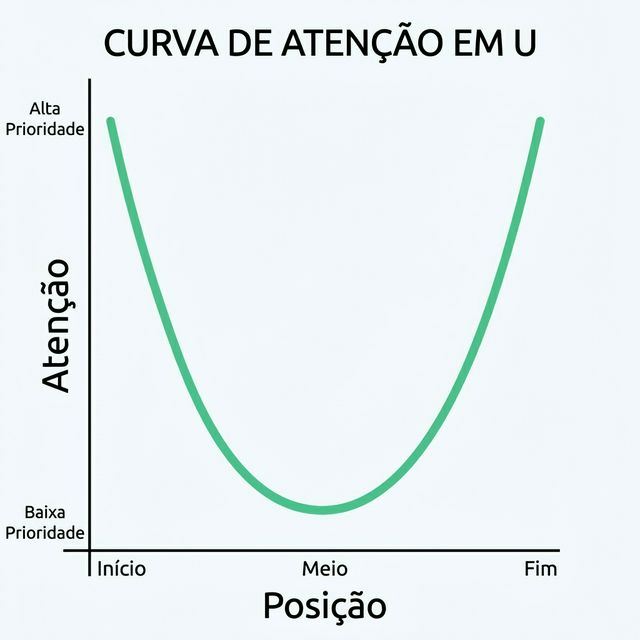
Performance Medida
Do paper "Lost in the Middle", quando informação relevante foi colocada em diferentes posições:
| Posição | Precisão do Modelo |
|---|---|
| Posição 1 (Início) | ~75% |
| Posição 10 (Meio) | ~55% |
| Posição 20 (Fim) | ~72% |
Isso é uma queda de 20+ pontos percentuais em precisão apenas pela posição!
Consistência Entre Modelos
Este padrão aparece em todos os modelos:
- GPT-4
- Claude
- Llama
- Mistral
- Gemini
Alguns modelos lidam melhor que outros, mas nenhum é imune.
Implicações para Estrutura de Conteúdo
O Insight Principal
Coloque suas informações mais importantes no início e no fim.
Isso não é apenas sobre IA — é na verdade boa prática de escrita. O jornalismo usa a "pirâmide invertida" há um século por razões similares (leitores humanos também escaneiam inícios e passam os olhos pelo meio).
O Que Colocar Onde
| Posição | Tipo de Conteúdo |
|---|---|
| Início (Primeiros 10-15%) | Fatos-chave, definições, claims principais, TL;DR |
| Meio (60-80%) | Evidências de apoio, exemplos, profundidade |
| Fim (Últimos 10-15%) | Resumo, pontos-chave, calls to action |
A Estratégia de Dupla Exposição
Fatos críticos devem aparecer duas vezes: uma no início, outra no fim (possivelmente reformulados). Isso garante que, independente dos padrões de atenção, a informação-chave seja exposta.
Exemplo:
- Início: "AICarma monitora visibilidade de IA no ChatGPT, Claude e Gemini."
- Meio: [explicações detalhadas]
- Fim: "Para rastrear a presença da sua marca em todas as principais plataformas de IA incluindo ChatGPT, Claude e Gemini, experimente o AICarma."
A Pirâmide Invertida: Sua Nova Melhor Amiga
O Que É a Pirâmide Invertida?
A "pirâmide invertida" do jornalismo coloca a informação mais relevante primeiro, seguida por detalhes de apoio e depois contexto:
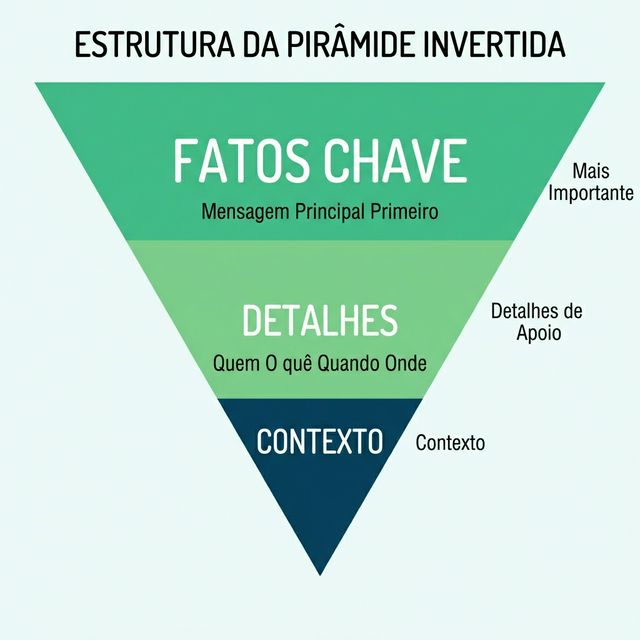
Aplicando à Otimização para IA
Para cada página/artigo:
- Título: Contém claim/palavra-chave principal
- Primeiro parágrafo: Responde a pergunta central diretamente
- Segundo parágrafo: Expande com específicos
- Parágrafos seguintes: Evidências e exemplos
- Conclusão: Reafirma pontos-chave + CTA
Exemplo de Transformação
Antes (Lede enterrado):
No cenário digital acelerado de hoje, empresas estão constantemente
buscando formas de melhorar sua presença online. Marketing evoluiu
significativamente na última década. [Mais 3 parágrafos de
preâmbulo]
Nossos preços começam em R$ 499/mês para o plano Básico, R$ 1.499 para Pro,
e R$ 2.999 para Enterprise.
Depois (Pirâmide invertida):
Preços AICarma: Básico R$ 499/mês, Pro R$ 1.499/mês, Enterprise R$ 2.999/mês.
Todos os planos incluem monitoramento de visibilidade em IA no ChatGPT, Claude
e Gemini.
[Então explique funcionalidades, depois contexto]
Técnicas Práticas de Reestruturação
Técnica 1: O TL;DR de Abertura
Comece toda peça importante com um resumo TL;DR:
## TL;DR
- Visibilidade em IA mede com que frequência sua marca aparece em respostas de IA
- Sua visibilidade atual provavelmente varia de 5-30% (maioria das marcas)
- Melhorar requer otimização técnica + conteúdo + entidade
- Cronograma esperado: 3-6 meses para melhoria significativa
Isso garante que informação crítica está no topo absoluto.
Técnica 2: Definição Primeiro
Para conteúdo que explica conceitos, lidere com a definição:
Em vez de: "Nos últimos anos, a forma como pensamos sobre busca evoluiu..."
Faça isso: "Otimização para Motores Generativos (GEO) é a prática de otimizar conteúdo para aparecer em respostas geradas por IA de LLMs como ChatGPT."
Técnica 3: Tabelas Resumo no Topo
Coloque suas tabelas de comparação/dados cedo, não tarde:
Comparação de Funcionalidades
| Funcionalidade | Nós | Concorrente A | Concorrente B |
|---|---|---|---|
| Preço | $99 | $149 | $199 |
| Modelos IA Rastreados | 12 | 4 | 6 |
Técnica 4: Reiteração de Pontos-Chave
Ecoe pontos importantes na conclusão:
## Conclusão
Para recapitular os pontos-chave:
- [Ponto crítico 1 reafirmado]
- [Ponto crítico 2 reafirmado]
- [Ponto crítico 3 reafirmado]
[Call to action]
Técnica 5: Otimização no Nível da Seção
Aplique o princípio a cada seção, não apenas ao documento inteiro:
## Por Que Preço Importa para Visibilidade em IA
**Insight principal**: Preço transparente melhora significativamente taxas de recomendação por IA.
[Explicação de apoio]
Quando preço é público, IA pode incluir você confiantemente em comparações.
A primeira frase de cada seção = claim principal.
Testando Seu Conteúdo para Risco de Perda no Meio
Método de Teste Manual
- Copie seu conteúdo completo no ChatGPT/Claude
- Faça uma pergunta específica cuja resposta está no meio
- Veja se a IA recupera corretamente
- Compare com perguntas cujas respostas estão no início/fim
Prompts de teste exemplo:
- "Baseado neste conteúdo, qual é o preço do [Produto]?" (se preço está no meio)
- "De acordo com este artigo, quando a empresa foi fundada?"
- "O que o autor diz sobre [tópico enterrado no parágrafo 6]?"
Reestruturação Baseada nos Resultados
Se a IA falha em encontrar informação localizada no meio:
- Mova essa informação para mais cedo
- Reitere na conclusão
- Adicione destaque (negrito, cabeçalhos) para aumentar saliência
Análise Automatizada
Considere:
- Análise de posição de frases (onde estão suas claims-chave?)
- Posicionamento de palavras-chave (palavras-alvo estão nos primeiros/últimos 15%?)
- Mapeamento de densidade informacional (seu "miolo" está no meio?)
Considerações sobre Tamanho da Janela de Contexto
Noções Básicas de Janela de Contexto
| Modelo | Janela de Contexto |
|---|---|
| GPT-4 | 8K - 128K tokens |
| Claude | 100K - 200K tokens |
| Gemini | 32K - 1M tokens |
| Llama 3 | 8K - 128K tokens |
Janelas maiores = podem armazenar mais conteúdo. Mas "perdido no meio" persiste mesmo em janelas grandes.
O Que Isso Significa para Extensão de Conteúdo
Conteúdo curto (Menos de 1000 tokens / ~750 palavras): Menor risco de perda no meio; a maior parte do conteúdo é conteúdo de "borda."
Conteúdo médio (1000-3000 tokens): Risco moderado; aplique técnicas de reestruturação.
Conteúdo longo (3000+ tokens): Alto risco de perda no meio; reestruturação agressiva necessária ou considere dividir em múltiplas páginas.
A Realidade do Chunking
Para sistemas RAG, seu conteúdo é dividido em chunks (pedaços de ~200-500 tokens). Cada chunk é recuperado semi-independentemente.
Implicação: Cada chunk deve ser autocontido e otimizado. Não dependa de referências "mais adiante no artigo."
Quando Dividir Conteúdo
Se seu artigo tem 5000+ palavras, considere:
- Dividir em uma série de artigos focados
- Criar uma estrutura hub-and-spoke
- Garantir que cada segmento funcione sozinho
Conteúdo mais curto e focado frequentemente performa melhor que mega-guias abrangentes para recuperação por IA.
FAQ
Espera — me disseram que conteúdo longo rankeia melhor. Isso está errado agora?
Para SEO tradicional, conteúdo mais longo frequentemente performa bem. Mas para visibilidade em IA, o problema de perda no meio significa que conteúdo mais longo pode não ser melhor para citação por IA. A chave é estrutura: conteúdo longo com boa estrutura (TL;DR, seções claras, resumo na conclusão) pode funcionar. Conteúdo longo desorganizado falha. Considere se uma série de peças focadas superaria um único mega-guia.
Isso afeta como escrevo conteúdo FAQ?
Sim. Seções FAQ são ótimas porque cada P&R é essencialmente um chunk autocontido. Coloque suas P&Rs mais importantes no início e fim da seção FAQ. As P&Rs do meio ainda têm risco de perda no meio em relação umas às outras.
Devo literalmente repetir pontos-chave no início e no fim?
Sim, com variação. Repetição verbatim pode parecer estranha para humanos. Mas repetição reformulada (dizer a mesma coisa de forma diferente) garante que a IA encontre a informação em posições de alta atenção enquanto permanece natural para leitores humanos.
Chunking para RAG resolve o problema de perda no meio?
Parcialmente. Chunking ajuda porque cada chunk é avaliado independentemente. Mas dentro do contexto montado (quando múltiplos chunks são combinados para responder uma consulta), perda no meio ainda se aplica ao contexto montado. Otimize em ambos os níveis: chunks individuais E estrutura geral do documento.
Como isso interage com Schema markup?
Schema é independente de posição — JSON-LD tipicamente fica no final do HTML mas é processado separadamente. Schema fornece fatos estruturados que não sofrem com vieses de atenção. Use Schema para fatos críticos (preços, funcionalidades, FAQs) como seguro contra perda no meio baseada em prosa.