O Framework T.R.U.S.T.: Uma Auditoria de 5 Pilares para Dominância em Busca por IA
Última atualização: 25 August 2025
Quando a visibilidade em IA cai, o primeiro instinto é pânico. O segundo é adivinhar.
"Talvez precisemos de mais conteúdo." "Talvez seja uma atualização do modelo." "Talvez devêssemos tentar injeção de prompt." (Por favor, não.)
Adivinhar é o que acontece quando você não tem um framework de diagnóstico. E em um campo tão complexo quanto Generative Engine Optimization, onde dezenas de variáveis interagem em múltiplos modelos de IA simultaneamente, adivinhar é caro.
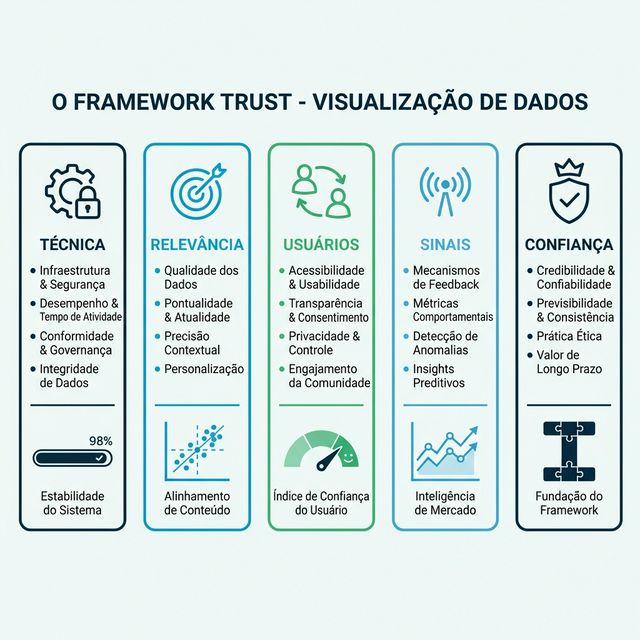
É por isso que desenvolvemos o Framework T.R.U.S.T. — um sistema estruturado de auditoria de cinco pilares para diagnosticar e melhorar a visibilidade da sua marca em busca por IA.
Assim como o framework E-E-A-T do Google (Experiência, Especialização, Autoridade, Confiabilidade) deu aos profissionais de SEO um modelo mental para avaliação de qualidade, o T.R.U.S.T. dá aos profissionais de GEO um modelo de diagnóstico para visibilidade em IA:
- T — Technical (Técnico)
- R — Relevance (Relevância)
- U — Users (Usuários)
- S — Signals (Sinais)
- T — Trust (Confiança)
Cada pilar aborda um modo de falha distinto. Quando sua visibilidade cai, você audita contra o T.R.U.S.T. para identificar qual pilar está rachando — e então conserta sistematicamente em vez de jogar espaguete na parede.
Índice
- Por Que Frameworks Importam em GEO
- T — Technical: A IA Consegue Acessar Seus Dados?
- R — Relevance: Seu Conteúdo Corresponde à Intenção?
- U — Users: Você Está Resolvendo Tarefas, Não Apenas Atraindo Cliques?
- S — Signals: Quem Mais Diz Que Você É Bom?
- T — Trust: Por Que a IA Deveria Acreditar em Você?
- Diagnosticando Quedas: A Árvore de Decisão
- Pontuando Sua Marca Contra o T.R.U.S.T.
- Estudo de Caso: Aplicando o Framework
- FAQ
Por Que Frameworks Importam em GEO
O cenário de busca por IA é genuinamente complexo. Sua visibilidade é influenciada pela composição dos dados de treinamento, qualidade de recuperação em tempo real, reconhecimento de entidade, restrições de system prompt, temperatura do modelo, contexto de conversa e mais.
Sem um framework, você está otimizando variáveis individuais isoladamente — como ajustar o baixo de um estéreo sem entender a música. Com um framework, você vê o mix completo e pode fazer ajustes informados.
Pesquisa do CSAIL do MIT mostrou que abordagens diagnósticas sistemáticas superam resolução de problemas ad-hoc em sistemas adaptativos complexos por fator de 3-5x (Sontag & Shah, "Causal Identification in Complex Systems," 2023). T.R.U.S.T. aplica esse princípio ao GEO.
T — Technical: A IA Consegue Acessar Seus Dados?
O primeiro pilar é o mais fundamental e o mais comumente negligenciado. Se crawlers de IA não conseguem fisicamente acessar seu conteúdo, nada mais importa.
O Checklist Técnico
| Verificação | Pergunta | Recurso |
|---|---|---|
| robots.txt | GPTBot, ClaudeBot e PerplexityBot estão permitidos? | Guia de Robots.txt para IA |
| llms.txt | Você tem um mapa de conteúdo legível por máquina? | O Que É llms.txt? |
| Velocidade da Página | Seu conteúdo pode ser buscado dentro dos limites de timeout do RAG (~2-5 segundos)? | Google PageSpeed Insights |
| Renderização | Seu conteúdo está no código HTML, ou escondido atrás de JavaScript/SPA? | Teste de Visualizar Código Fonte |
| Tags Canonical | Crawlers de IA estão seguindo as URLs canônicas corretas? | Ferramentas de auditoria de site |
Por Que Isso Importa Mais Agora
Mecanismos de busca tradicionais como o Google investiram décadas em pipelines de renderização sofisticados que podem executar JavaScript, seguir redirecionamentos e extrair conteúdo de SPAs complexas. Crawlers de IA são comparativamente primitivos. Muitos operam como o Googlebot do início dos anos 2000: leem HTML bruto, seguem links básicos e seguem em frente.
Se seu conteúdo é renderizado client-side com React mas não tem server-side rendering ou geração estática, crawlers de IA podem ver uma página em branco. Pesquisa do Estudo de Crawling de IA 2024 da Ahrefs descobriu que 23% dos sites enterprise inadvertidamente bloqueiam pelo menos um bot de IA importante através de robots.txt mal configurado ou barreiras técnicas.
Diagnosticando uma Falha Técnica
Sintoma: Queda súbita e drástica de visibilidade em todos os modelos de IA simultaneamente.
Causa Raiz: Geralmente um deploy que mudou o robots.txt, uma configuração incorreta de CDN, ou uma migração que quebrou o server-side rendering.
Correção: Auditoria emergencial de todos os pontos de acesso. Verificar robots.txt, testar com curl para ver o que bots de IA veem, verificar se llms.txt está acessível.
R — Relevance: Seu Conteúdo Corresponde à Intenção?
Acesso técnico é necessário mas insuficiente. Uma vez que a IA pode ler seu conteúdo, a pergunta se torna: ela encontra o que está procurando?
Relevância Semântica vs. Correspondência de Palavras-Chave
SEO tradicional nos treinou em otimização de palavras-chave. GEO requer relevância semântica — seu conteúdo deve corresponder ao significado da consulta, não apenas às palavras.
LLMs processam texto através de vetores de embedding — representações matemáticas de significado em espaço de alta dimensionalidade. A "distância" do seu conteúdo da consulta nesse espaço vetorial determina a relevância de recuperação. Como demonstrado por Reimers & Gurevych ("Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks," EMNLP 2019), conteúdo semanticamente similar se agrupa independente da escolha exata de palavras.
Implicação: Escrever para IA significa cobrir o território semântico de um tópico, não apenas polvilhar palavras-chave alvo. Se alguém pergunta "Como melhorar a presença da minha marca no ChatGPT?", seu conteúdo precisa cobrir conceitos como visibilidade em IA, model polling, probabilidade de citação e reconhecimento de entidade — mesmo que essas frases exatas não apareçam na consulta.
Posicionamento na Janela de Contexto
Nosso guia de Otimização de Janela de Contexto cobre isso em profundidade, mas as principais descobertas da pesquisa "Lost in the Middle" de Liu et al. merecem ser repetidas:
- Modelos prestam mais atenção a informações no início e fim da janela de contexto
- Informações no meio se "perdem" — literalmente recebendo pesos de atenção menores
- Front-loading suas reivindicações chave aumenta sua probabilidade de serem citadas
Frescor e Recência
Para sistemas baseados em RAG como Perplexity, frescor do conteúdo importa. Pesquisa da Microsoft (Kasai et al., "RealTime QA," 2022) mostra que sistemas de recuperação preferem fortemente conteúdo recentemente atualizado ao responder consultas de atualidades.
Ação: Atualize suas páginas-chave regularmente. Mesmo atualizações menores (estatísticas atualizadas, referências ao ano atual) sinalizam recência para sistemas de recuperação.
U — Users: Você Está Resolvendo Tarefas, Não Apenas Atraindo Cliques?
O "U" pode ser o pilar mais voltado para o futuro. À medida que a IA evolui de responder perguntas para completar tarefas — através de agentes de IA autônomos — seu conteúdo precisa servir ações, não apenas informação.
A Mudança de Informação para Conclusão de Tarefas
Quando um usuário pede ao ChatGPT "Reservar um restaurante em São Paulo para sexta à noite", a IA não quer mostrar uma lista de 10 restaurantes. Quer completar a tarefa:
- Encontrar disponibilidade
- Combinar preferências
- Fazer a reserva
- Confirmar os detalhes
Se seu restaurante tem um sistema de reservas acessível por API, dados de disponibilidade estruturados e preços claros — está otimizado para conclusão de tarefas. Se tem um cardápio em PDF bonito e um número de telefone "ligue para nós" — está invisível para o agente.
Sinais de Experiência do Usuário
Mesmo para consultas de informação, sinais de engajamento do usuário importam. Se usuários consistentemente clicam no seu site a partir de citações de IA e passam tempo lendo, esse loop de feedback positivo reforça sua visibilidade.
| Sinal | Impacto | Otimização |
|---|---|---|
| Clique da citação | Alto | Escreva meta descriptions e títulos de página compelling |
| Tempo na página | Médio | Crie conteúdo genuinamente valioso e aprofundado |
| Taxa de rejeição | Médio | Garanta que o conteúdo entrega o que a IA prometeu |
| Conclusão de tarefa | Muito Alto | Habilite ações (reserva, compra, download) |
Pesquisa sobre comportamento zero-click (SparkToro, "Zero-Click Search Study," 2024) revela que, embora taxas gerais de clique estejam diminuindo, a qualidade dos cliques restantes está aumentando. Usuários que clicam a partir de recomendações de IA são de alta intenção — e as plataformas notam isso.
S — Signals: Quem Mais Diz Que Você É Bom?
O quarto pilar aborda corroboração externa — o equivalente de IA dos backlinks, mas mais amplo e matizado.
Por Que Sinais Superam Auto-Promoção
Um LLM avaliando sua marca não lê apenas seu site. Lê o que todos dizem sobre você. Se seu site afirma "Somos o melhor CRM para startups" mas avaliações do G2 dizem "Suporte ao cliente terrível" e threads do Reddit dizem "Evite esse produto" — a IA refletirá o consenso, não seu texto de marketing.
Este é o princípio da triangulação multi-fonte, documentado extensivamente na literatura de Knowledge Graph (Dong et al., "Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion," KDD 2014). IA atribui maior confiança a fatos corroborados em múltiplas fontes independentes.
Fontes de Sinais Ranqueadas por Peso na IA
| Tipo de Fonte | Peso na IA | Sua Estratégia |
|---|---|---|
| Wikipedia | ★★★★★ | Mantenha presença precisa na Wikipedia |
| Citações acadêmicas | ★★★★★ | Publique pesquisa, seja citado por papers |
| Plataformas de avaliação (G2, Capterra) | ★★★★ | Gerencie ativamente perfis de avaliação |
| ★★★★ | Construa presença autêntica na comunidade (Estratégia Reddit) | |
| Imprensa do setor | ★★★★ | Conquiste cobertura, não apenas posicionamentos pagos |
| Redes sociais | ★★ | Útil para sinais de recência, menos para autoridade |
| Seu próprio blog | ★★ | Importante mas insuficiente sozinho |
Sentimento como Sinal
Não basta ser mencionado. Você precisa ser mencionado positivamente. Nossa metodologia de AI Visibility Score rastreia não apenas frequência de citação mas sentimento — porque um LLM que "conhece" sua marca mas a associa com experiências negativas vai ativamente recomendar contra você.
Organizações enterprise estão cada vez mais rastreando sentimento de marca em modelos de IA como parte de sua estratégia de gestão de reputação corporativa.
T — Trust: Por Que a IA Deveria Acreditar em Você?
O pilar final é a pedra angular. Confiança é o resultado cumulativo de todos os outros pilares, mas também tem seus próprios impulsionadores independentes.
Autoridade e Autoria
O E-E-A-T do Google enfatiza "Experiência" e "Especialização". Modelos de IA levam isso adiante. Pesquisa do Allen Institute for AI (Wadden et al., "SciFact: Joint Scientific Document Retrieval and Fact-Checking," EMNLP 2020) demonstra que LLMs avaliam credibilidade da fonte ao pesar reivindicações concorrentes.
Implicações práticas:
- Autores nomeados: Conteúdo com autores nomeados e credenciados tem peso maior que blogs corporativos anônimos
- Afiliação institucional: Um estudo publicado por "pesquisadores do MIT" tem mais peso que um de "nossa equipe de dados"
- Redes de citação: Se seu conteúdo cita fontes credíveis, e fontes credíveis citam você, você cria um loop de confiança
YMYL: O Guardião da Confiança
Para conteúdo de saúde, finanças, jurídico e segurança — o que sistemas de IA classificam como YMYL (Your Money or Your Life) — confiança não é apenas um fator de ranking. É um guardião. Modelos irão ativamente suprimir conteúdo não confiável nessas categorias para reduzir risco de danos.
Se você opera em um espaço YMYL, o pilar Trust não é opcional — é existencial.
Consistência Constrói Confiança
Confiança se compõe ao longo do tempo. Uma marca que tem sido consistentemente presente, consistentemente precisa e consistentemente citada em versões de modelo desenvolve uma "aderência de Knowledge Graph" que novos entrantes não podem replicar da noite para o dia.
É por isso que Entity SEO importa tanto. Entidades fortes persistem através de atualizações de modelo. Entidades fracas flutuam e desaparecem.
Diagnosticando Quedas: A Árvore de Decisão
Quando sua visibilidade em IA cai, não entre em pânico. Audite metodicamente:
| Sintoma | Primeira Verificação | Pilar Provável |
|---|---|---|
| Queda súbita, todos os modelos | Acesso técnico (robots.txt, site fora do ar?) | Technical |
| Declínio gradual, consultas de categoria | Frescor do conteúdo, alinhamento semântico | Relevance |
| Visível mas baixo click-through | Experiência do usuário, qualidade do conteúdo | Users |
| Concorrente subindo, você estático | Menções externas, perfis de avaliação | Signals |
| Volátil, dependente do modelo | Marcadores de autoridade, presença de entidade | Trust |
Pontuando Sua Marca Contra o T.R.U.S.T.
Faça esta autoavaliação rápida (pontue cada pilar de 1-5):
| Pilar | Pontuação 1 (Fraco) | Pontuação 5 (Forte) |
|---|---|---|
| Technical | Crawlers de IA parcialmente bloqueados | Acesso completo + llms.txt + Schema |
| Relevance | Conteúdo genérico, lotado de palavras-chave | Cobertura semântica, reivindicações front-loaded, conteúdo fresco |
| Users | Apenas informação, sem ações | Habilitador de tarefas, acessível por API, dados estruturados |
| Signals | Apenas auto-promoção | Wikipedia + Avaliações + Reddit + Imprensa |
| Trust | Blog anônimo, sem citações | Autores nomeados, fontes citadas, autoridade do setor |
Pontuação 20-25: Você está competitivo. Foque em avanço. Pontuação 15-19: Você tem lacunas. Priorize o pilar mais fraco. Pontuação Abaixo de 15: Trabalho fundamental necessário. Comece pelo Technical.
Estudo de Caso: Aplicando o Framework
Uma empresa SaaS B2B rastreada pela AICarma aparecia em 45% das consultas relevantes do ChatGPT mas apenas 12% das consultas do Perplexity. Usando T.R.U.S.T.:
- Technical: Perplexity depende de crawling em tempo real. O site deles tinha
PerplexityBotbloqueado no robots.txt. (Corrigido → pilar T.) - Relevance: Suas landing pages eram pesadas em marketing com profundidade semântica limitada. (Adicionou documentação técnica → pilar R.)
- Signals: Nenhuma presença no Reddit ou Stack Overflow. (Construiu engajamento autêntico na comunidade → pilar S.)
Resultado: Visibilidade no Perplexity melhorou de 12% para 38% em 6 semanas. ChatGPT permaneceu estável. AI Visibility Score geral aumentou 22 pontos.
FAQ
Como o T.R.U.S.T. é diferente do E-E-A-T do Google?
E-E-A-T é um framework de avaliação de qualidade projetado para rankings de busca curados por humanos. T.R.U.S.T. é um framework de diagnóstico e otimização projetado para sistemas de IA probabilísticos. Cobre acessibilidade técnica, conclusão de tarefas e corroboração externa — dimensões que o E-E-A-T não aborda porque não eram relevantes para busca tradicional.
Por qual pilar devo começar?
Sempre comece pelo Technical. Se crawlers de IA não conseguem acessar seu conteúdo, nada mais importa. Depois do Technical, priorize qualquer pilar que pontuou mais baixo na sua autoavaliação.
Com que frequência devo fazer uma auditoria T.R.U.S.T.?
Recomendamos uma auditoria abrangente mensal e monitoramento semanal de indicadores-chave. Como descrito em nosso guia Flywheel de GEO, monitoramento contínuo captura problemas mais rápido que auditorias periódicas.
O T.R.U.S.T. se aplica a todos os setores?
Sim, mas o peso dos pilares varia. Para setores YMYL (saúde, finanças), o pilar Trust tem peso desproporcional. Para empresas SaaS, Signals e Relevance tendem a ser os maiores diferenciadores. Para negócios locais, os pilares Technical e Users são críticos.
Posso usar o T.R.U.S.T. para análise competitiva?
Absolutamente. Pontue seus três principais concorrentes contra o framework. Onde eles são fracos e você é forte — esse é seu fosso competitivo. Onde eles são fortes e você é fraco — essa é sua prioridade. Nosso guia de Inteligência Competitiva complementa o T.R.U.S.T. com metodologias específicas de rastreamento competitivo.