RAG SEO : Le Guide Complet pour Rédiger du Contenu Optimisé pour la Génération Augmentée par Récupération
Dernière mise à jour : 18 October 2025
Voici un scénario qui se joue des milliers de fois par jour : un client potentiel demande à Perplexity « Quel est le meilleur outil de gestion de projet pour les équipes distantes ? ». L'IA cherche sur le web, récupère des extraits de centaines de pages et synthétise une réponse.
Votre page était classée #3 sur Google pour cette exacte requête. Mais l'IA ne vous a pas cité. Elle a cité un concurrent dont la page était optimisée pour la récupération, pas seulement pour le classement.
Bienvenue dans le monde du RAG SEO — une discipline qui devient rapidement aussi importante que le SEO traditionnel, mais qui reste presque totalement inconnue de la plupart des équipes marketing.
Le RAG (Retrieval-Augmented Generation, ou Génération Augmentée par Récupération) est la technologie qui connecte les modèles d'IA figés aux données en temps réel. C'est ainsi que ChatGPT peut répondre à des questions sur les événements d'hier. C'est ainsi que Perplexity fournit des résultats de recherche en temps réel. Et c'est de plus en plus ainsi que les AI Overviews de Google fonctionnent.
Si vous voulez que l'IA cite votre contenu, vous devez comprendre comment les systèmes RAG pensent — et restructurer votre contenu en conséquence. Les organisations d'entreprise utilisent de plus en plus les architectures RAG non seulement pour la récupération de contenu, mais pour la recherche de marché synthétique via le polling multi-modèles.
Table des Matières
- Qu'est-ce que le RAG et Pourquoi Est-ce Important ?
- Le Pipeline RAG : Comment l'IA « Lit » Votre Contenu
- Le Phénomène « Perdu au Milieu »
- Le Facteur de Récupérabilité : Votre Nouvelle Métrique de Classement
- Le Découpage de Contenu : Écrire pour la Consommation IA
- La Densité Sémantique : La Métrique de Qualité que l'IA Mesure
- Tableaux, Listes et Formats Structurés
- Checklist Pratique d'Optimisation RAG
- Mesurer la Performance RAG
- FAQ
Qu'est-ce que le RAG et Pourquoi Est-ce Important ?
La plupart des gens ne comprennent pas comment les LLMs fonctionnent. Ils imaginent une vaste base de données de faits dans laquelle l'IA recherche. Mais ce n'est pas exact.
Les LLMs sont fondamentalement des systèmes génératifs. Ils complètent du texte en se basant sur des patterns appris pendant l'entraînement. Ils ne « récupèrent » pas des faits — ils hallucinent du texte qui semble plausible en fonction des données d'entraînement.
Cela crée des problèmes :
- Informations obsolètes : les données d'entraînement ont une date de coupure
- Risque d'hallucination : le modèle peut générer des absurdités qui sonnent convaincantes
- Connaissances statiques : impossible de répondre aux questions sur les événements récents
Le RAG résout ces problèmes en ajoutant une étape de récupération avant la génération :
Comment le RAG Fonctionne
Où le RAG est Utilisé
| Système | Implémentation RAG |
|---|---|
| Perplexity | RAG intensif — cherche sur le web pour chaque requête |
| ChatGPT (Navigation avec Bing) | RAG optionnel — l'utilisateur peut activer la recherche web |
| Google AI Overviews | RAG intégré depuis l'index de recherche Google |
| Claude + Artifacts | RAG pour les documents uploadés |
| IA d'Entreprise | RAG personnalisé sur les bases de connaissances d'entreprise |
L'insight clé : Si vous n'êtes pas optimisé pour le RAG, vous êtes de plus en plus invisible pour la recherche assistée par l'IA.
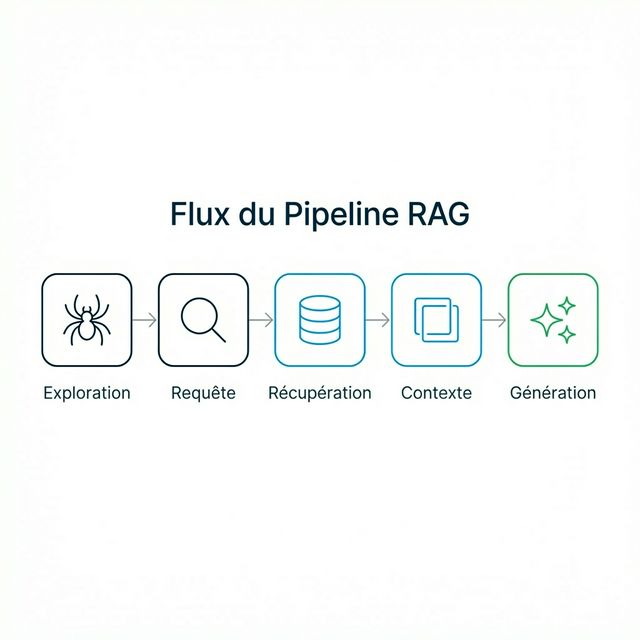
Le Pipeline RAG : Comment l'IA « Lit » Votre Contenu
Comprendre le pipeline technique vous aide à l'optimiser. Voici comment un système RAG traite votre contenu :
Étape 1 : Crawl et Indexation
Le système IA (ou son composant de recherche) crawle les pages web et les découpe en « chunks » — typiquement de 200 à 500 tokens chacun. Ces chunks sont convertis en embeddings vectoriels (représentations mathématiques du sens).
Votre opportunité : Assurez-vous que votre contenu est crawlable (optimisation du robots.txt) et structuré de manière à créer des chunks cohérents.
Étape 2 : Traitement de la Requête
Quand un utilisateur pose une question, cette question est aussi convertie en embedding vectoriel.
Votre opportunité : Rédigez du contenu qui correspond sémantiquement à la façon dont les utilisateurs formulent leurs questions.
Étape 3 : Récupération
Le système trouve les chunks dont les embeddings sont mathématiquement similaires à l'embedding de la question. Généralement, les 5 à 20 chunks les plus pertinents sont récupérés.
Votre opportunité : Créez des chunks qui répondent directement aux questions courantes de votre domaine.
Étape 4 : Assemblage du Contexte
Les chunks récupérés sont assemblés dans une « fenêtre de contexte » que le LLM utilisera pour générer sa réponse.
Votre opportunité : Écrivez des paragraphes autonomes qui apportent de la valeur même extraits de leur contexte.
Étape 5 : Génération
Le LLM génère une réponse basée sur le contexte fourni plus ses connaissances d'entraînement.
Votre opportunité : Incluez des affirmations citables et faisant autorité que le LLM voudra citer.
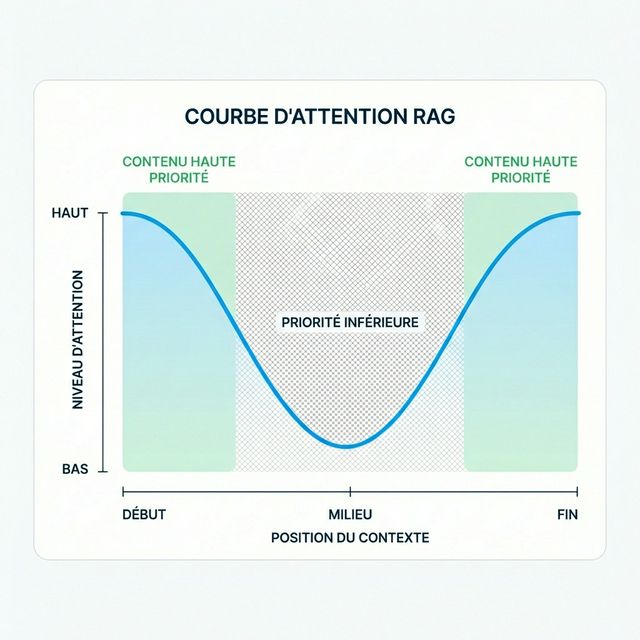
Le Phénomène « Perdu au Milieu »
L'une des découvertes les plus importantes de la recherche sur le RAG est l'effet « perdu au milieu ». Quand les LLMs reçoivent de longues fenêtres de contexte, ils prêtent le plus attention à :
- Le début du contexte
- La fin du contexte
- Beaucoup moins d'attention au milieu
Cela a des implications profondes pour la stratégie de contenu :
La Courbe d'Attention
Implications Stratégiques
| Position du Contenu | Niveau d'Attention IA | Quoi Mettre Ici |
|---|---|---|
| Premiers 10 % de l'article | ÉLEVÉ | Définitions clés, affirmations principales, TL;DR |
| 80 % du milieu de l'article | PLUS FAIBLE | Preuves à l'appui, exemples, approfondissements |
| Derniers 10 % de l'article | ÉLEVÉ | Résumé, points clés à retenir, appels à l'action |
C'est pourquoi le style classique de la « pyramide inversée » du journalisme (informations les plus importantes en premier) fait son retour pour l'optimisation IA.
Le Facteur de Récupérabilité : Votre Nouvelle Métrique de Classement
En Optimisation pour les Moteurs Génératifs, on n'optimise pas seulement pour la « lisibilité » — on optimise pour la récupérabilité.
Le SEO traditionnel demande : « Cette page se classera-t-elle pour le mot-clé ? » Le RAG SEO demande : « Des chunks de cette page seront-ils récupérés pour les questions pertinentes ? »
Qu'est-ce qui Rend un Contenu Récupérable ?
| Facteur | Description | Comment Optimiser |
|---|---|---|
| Pertinence Sémantique | Similarité d'embedding avec la requête | Utilisez des titres orientés questions, imitez le langage des utilisateurs |
| Densité d'Information | Ratio faits/mots | Éliminez le superflu, condensez les faits dans chaque paragraphe |
| Spécificité | Concret vs générique | Incluez des chiffres, noms et exemples spécifiques |
| Signaux de Fraîcheur | Indicateurs d'actualité | Datez votre contenu, référencez l'année en cours |
| Marqueurs d'Autorité | Indicateurs de crédibilité | Citez vos sources, montrez votre expertise |
L'Écart de Récupérabilité
Voici la vérité frustrante : vous pouvez être classé #1 sur Google tout en ayant une faible récupérabilité. Pourquoi ?
- Votre contenu est peut-être optimisé pour le matching de mots-clés, pas pour le sens sémantique
- Vos faits clés sont peut-être noyés dans des paragraphes de remplissage
- Votre page ne répond peut-être pas directement à la question que les utilisateurs posent
Exemple :
- L'utilisateur demande : « Quel est le meilleur CRM pour les petites entreprises à moins de 50 €/mois ? »
- Votre page est classée #1 pour « meilleur CRM petite entreprise »
- Mais votre page dit « Contactez notre service commercial pour les tarifs »
- L'IA récupère le concurrent dont la page dit « HubSpot Starter : 45 €/mois »
- Le concurrent est cité, pas vous.
Le Découpage de Contenu : Écrire pour la Consommation IA
Le changement le plus radical en optimisation RAG est de penser votre contenu comme des chunks, pas comme des pages.
La Règle du Paragraphe Autonome
Chaque paragraphe (ou petit groupe de paragraphes) doit être compréhensible seul. Évitez :
| ❌ À Éviter | ✅ À Préférer |
|---|---|
| « Comme mentionné dans la section précédente... » | Reformuler le point clé |
| « Cet outil a plusieurs avantages... » (vague) | « [Nom de l'Outil] offre trois avantages clés : [les lister] » |
| « La solution à ce problème est... » | « La solution au [problème spécifique] est [solution spécifique] » |
| Références à « ci-dessus » ou « ci-dessous » | Liens explicites ou contexte complet |
Pourquoi : Quand votre paragraphe est extrait comme chunk, l'IA n'a peut-être pas accès au paragraphe précédent. Si votre chunk n'a pas de sens seul, il ne sera pas utile — et ne sera pas cité.
Le Pattern Titre-Réponse
Pour chaque titre H2 ou H3, le paragraphe qui suit immédiatement doit répondre directement à la question impliquée par le titre.
## Qu'est-ce que l'Optimisation pour les Moteurs Génératifs ?
L'Optimisation pour les Moteurs Génératifs (GEO) est la pratique
consistant à optimiser le contenu et la présence digitale pour
apparaître dans les réponses générées par l'IA, notamment les
grands modèles de langage comme ChatGPT, Claude et Gemini.
Contrairement au SEO traditionnel qui se concentre sur les
classements dans les moteurs de recherche, le GEO se concentre
sur la fréquence de citation et l'inclusion dans les
recommandations des réponses synthétisées par l'IA.
Ce pattern est idéal pour le RAG car :
- Le titre fournit le contexte sémantique
- Le premier paragraphe répond directement
- Le chunk est autonome et citable
Recommandations de Longueur des Chunks
La plupart des systèmes RAG utilisent des chunks de 200 à 500 tokens (~150-400 mots). Écrivez en gardant cela à l'esprit :
- Chaque section majeure (H2) devrait couvrir ~300-500 mots
- Les sous-sections (H3) devraient faire ~150-250 mots
- Gardez les paragraphes à 3-5 phrases
Plus long ne signifie pas mieux pour le RAG. Un méga-guide de 5 000 mots peut en réalité moins bien performer que cinq articles focalisés de 1 000 mots car :
- La clarté sémantique est plus élevée dans les articles ciblés
- Chaque article crée des chunks plus propres
- Le maillage interne entre les articles préserve toujours la relation
La Densité Sémantique : La Métrique de Qualité que l'IA Mesure
La densité sémantique désigne la quantité d'informations significatives et spécifiques par unité de texte. C'est peut-être le facteur le plus important en optimisation RAG.
Faible vs Haute Densité Sémantique
| Faible Densité (Mauvais pour le RAG) | Haute Densité (Bon pour le RAG) |
|---|---|
| « Notre solution leader du marché fournit des résultats best-in-class » | « AICarma surveille 12 plateformes IA dont ChatGPT, Claude et Gemini » |
| « Nous avons aidé de nombreuses entreprises à réussir » | « Nous avons augmenté la visibilité IA de 340 % pour 127 entreprises SaaS B2B » |
| « Tarification compétitive disponible » | « Les plans démarrent à 299 €/mois pour jusqu'à 50 requêtes suivies » |
| « Les fonctionnalités incluent des capacités avancées » | « Fonctionnalités : monitoring en temps réel, analyse de sentiment, suivi concurrentiel, accès API » |
L'Audit du Superflu
Parcourez votre contenu et identifiez :
- Phrases de remplissage : « Dans le monde effréné d'aujourd'hui », « Il va sans dire »
- Affirmations vagues : « apprécié par les entreprises leaders », « best-in-class »
- Redondances : Dire la même chose de plusieurs façons
- Préambules : Introductions qui retardent l'information réelle
Chacun de ces éléments dilue votre densité sémantique. Dans un monde où l'IA saisit des chunks de 300 mots, chaque mot compte.
Tableaux, Listes et Formats Structurés
Les systèmes RAG ont plus de facilité à extraire et utiliser des informations structurées. Les tableaux et les listes sont de l'or.
Pourquoi les Tableaux Fonctionnent
Les tableaux compriment l'information de manière facile à parser programmatiquement :
| Produit | Prix | Fonctionnalités | Idéal Pour |
|---|---|---|---|
| HubSpot | 45 €/mois | CRM, Email | Petites équipes |
| Salesforce | 75 €/mois | Suite complète | Enterprise |
| Pipedrive | 29 €/mois | Focus ventes | Startups |
Quand un utilisateur demande « Quel CRM coûte moins de 50 € ? », un système RAG peut plus facilement extraire et présenter ces données de tableau que de parser la même information dans de la prose fluide.
Types de Contenu Structuré à Ajouter
- Tableaux comparatifs (fonctionnalité vs fonctionnalité, produit vs produit)
- Tableaux de tarifs avec des chiffres clairs
- Fiches techniques avec des détails techniques
- Tableaux chronologiques (quand, quoi, qui)
- Formats checklist pour les processus
- Listes de définitions pour la terminologie
Optimisation des Listes
Les listes à puces et numérotées sont plus faciles à découper que la prose :
Caractéristiques clés d'un contenu optimisé GEO :
- Paragraphes autonomes fonctionnant comme des chunks indépendants
- Affirmations spécifiques et citables avec des chiffres et des noms
- Patterns titre-réponse clairs tout au long du texte
- Tableaux pour les données comparatives
- Sections FAQ avec balisage structuré
Checklist Pratique d'Optimisation RAG
Utilisez cette checklist lors de la création ou mise à jour de contenu :
Structure du Contenu
- [ ] Définition/affirmation clé dans le premier paragraphe
- [ ] Paragraphes autonomes (pas de « comme mentionné ci-dessus »)
- [ ] Pattern titre-réponse pour toutes les sections H2/H3
- [ ] Résumé/points clés à retenir à la fin
- [ ] Séparations de sections claires tous les 300-500 mots
Densité Sémantique
- [ ] Toutes les phrases de remplissage et préambules supprimés
- [ ] Chaque paragraphe contient au moins un fait spécifique
- [ ] Toutes les affirmations sont quantifiées quand possible
- [ ] Les noms de produits/services sont explicites (pas « notre solution »)
- [ ] Les tarifs sont visibles et spécifiques
Données Structurées
- [ ] Au moins un tableau de comparaison/données par article
- [ ] Listes à puces pour les affirmations multi-points
- [ ] Balisage Schema sur la page
- [ ] Section FAQ avec schema FAQ
Utilisabilité
- [ ] La page charge en moins de 2 secondes
- [ ] Le contenu est disponible sans JavaScript
- [ ] Rendu adapté au mobile
- [ ] Pas de contenu derrière des murs de connexion
Mesurer la Performance RAG
Comment savoir si votre optimisation RAG fonctionne ?
Tests Directs
- Posez à Perplexity vos questions cibles
- Notez si votre contenu est cité
- Suivez la fréquence de citation dans le temps
Indicateurs Indirects
| Métrique | Où la Trouver | Quoi Chercher |
|---|---|---|
| Score de Visibilité IA | AICarma | Taux de citation en augmentation |
| Utilisation des Sources | Module d'Attribution des Sources d'AICarma | Quels domaines (Reddit, Wikipedia, presse) influencent les recommandations IA |
| Extraits Optimisés | Google Search Console | Apparitions en P0 (souvent liées au RAG) |
| Référents depuis les domaines IA | Analytics | Référents perplexity.ai, chat.openai.com |
| Temps sur la Page | Analytics | Plus élevé pour du contenu bien structuré |
| Taux de Rebond | Analytics | Plus bas pour du contenu sémantiquement clair |
Tests A/B pour le RAG
Essayez cette expérience :
- Prenez une page importante
- Créez deux versions : originale vs optimisée RAG
- Posez à Perplexity la même question avec chaque version indexée
- Suivez laquelle est citée le plus souvent
FAQ
Le RAG SEO est-il identique au SEO traditionnel ?
Non. Le SEO traditionnel vous aide à être trouvé par les crawlers des moteurs de recherche et à vous classer pour des mots-clés. Le RAG SEO aide votre contenu à être sélectionné par le LLM après avoir été récupéré. Vous avez besoin des deux : le SEO pour être crawlé et indexé, l'optimisation RAG pour être cité une fois récupéré.
La longueur du contenu est-elle importante pour le RAG ?
Contre-intuitivement, le court bat souvent le long pour le RAG. Le « remplissage » nuit à la performance RAG car il dilue le signal sémantique de vos chunks. Un guide concis de 800 mots peut surpasser un article divagant de 3 000 mots. La qualité et la densité comptent plus que la longueur.
Comment tester si mon contenu est RAG-friendly ?
Collez votre contenu dans la fenêtre de contexte de ChatGPT et posez-lui des questions spécifiques basées sur votre texte. Des questions comme : « Selon ce contenu, quel est le prix de [produit] ? » ou « Quelles sont les trois fonctionnalités principales mentionnées ? » Si l'IA a du mal à répondre, la structure de votre contenu a peut-être besoin d'être retravaillée.
Dois-je découper de longs articles en plusieurs articles plus courts ?
Souvent oui. Une série de 5 articles interconnectés de 1 000 mots performe typiquement mieux en récupération RAG qu'un méga-guide unique de 5 000 mots. Chaque article plus court crée des chunks plus propres avec un focus sémantique plus clair. Utilisez le maillage interne pour maintenir la relation entre les articles.
Comment le RAG interagit-il avec le Balisage Schema ?
Le Balisage Schema et l'optimisation RAG sont complémentaires. Le Schema aide le crawler à comprendre ce que votre contenu représente. L'optimisation RAG garantit que votre contenu est sélectionné pour les requêtes pertinentes. Utilisez les deux : le Schema sur chaque page, plus une structure de contenu optimisée RAG partout.