Optimisation de la Fenêtre de Contexte : Écrire pour la 'Courbe d'Attention en U'
Dernière mise à jour : 5 December 2025
Voici une phrase qui vous fera repenser la façon dont vous structurez votre contenu : Les grands modèles de langage sont mauvais pour prêter attention au milieu des longs documents.
Ce n'est pas un détail mineur — c'est une caractéristique fondamentale du fonctionnement de l'IA basée sur les transformers. La recherche a constamment montré que les LLMs présentent ce qu'on appelle la « courbe d'attention en U » — ils prêtent le plus d'attention à l'information au début et à la fin de leur fenêtre de contexte, tandis que l'information au milieu est partiellement ignorée.
Pour les créateurs de contenu, les marketeurs et toute personne essayant de faire citer son contenu par l'IA, cela a des implications profondes. Si vos faits clés sont enterrés au paragraphe 7 d'un article de 15 paragraphes, l'IA pourrait littéralement ne pas les « voir », même si le crawler a récupéré votre page.
Comprendre et optimiser pour l'attention de la fenêtre de contexte est l'un des aspects les plus négligés de l'Optimisation pour les Moteurs Génératifs. Corrigeons cela.
Table des Matières
- Le Phénomène « Perdu au Milieu »
- Comment l'Attention IA Fonctionne Réellement
- La Courbe d'Attention en U
- Implications pour la Structure du Contenu
- La Pyramide Inversée : Votre Nouvelle Meilleure Amie
- Techniques Pratiques de Restructuration
- Tester Votre Contenu pour le Risque de Perte au Milieu
- Considérations sur la Taille de la Fenêtre de Contexte
- FAQ
Le Phénomène « Perdu au Milieu »
La Recherche
Un article majeur de 2023 de chercheurs de Stanford, Berkeley et Samaya AI intitulé « Lost in the Middle » a démontré une limitation critique des LLMs : face à de longues fenêtres de contexte, les modèles peinent à utiliser les informations du milieu de ce contexte.
Résultats Clés :
- La performance chute significativement quand l'information pertinente est au milieu
- Même les modèles avec des fenêtres de 4K, 16K ou 32K tokens présentent ce comportement
- L'effet est prononcé même dans les modèles commerciaux bien entraînés
- Les fenêtres de contexte plus grandes ne résolvent pas le problème
Ce que Cela Signifie pour le Contenu
Quand votre page est récupérée par le RAG (Génération Augmentée par Récupération), elle devient partie de la fenêtre de contexte de l'IA. Si votre argument de vente clé est au milieu de votre page, il peut être « perdu » pour l'attention du modèle.
| Position dans le Document | Attention IA | Probabilité de Citation |
|---|---|---|
| Premiers 10 % | Élevée | Élevée |
| 80 % du milieu | Plus faible | Réduite |
| Derniers 10 % | Élevée | Élevée |
Pourquoi Cela Se Produit
Ce n'est pas un bug — c'est le fonctionnement des mécanismes d'attention des transformers. L'entraînement encourage les modèles à s'appuyer sur les extrêmes de position. L'information au début établit le contexte ; l'information à la fin fournit les conclusions. Le contenu du milieu est souvent considéré comme du « matériel d'appui ».
Comment l'Attention IA Fonctionne Réellement
Le Mécanisme d'Attention
Les LLMs utilisent l'« attention » pour décider quels tokens (mots/fragments) de l'entrée privilégier lors de la génération de la sortie. Pour chaque token de sortie, le modèle calcule des scores d'attention à travers tous les tokens d'entrée.
En théorie, l'attention permet de se concentrer sur n'importe quelle partie de l'entrée. En pratique, les patterns d'attention montrent de forts biais vers :
- La récence (tokens proches)
- La position (tokens en début et fin)
- La pertinence sémantique (tokens correspondants)
Les Embeddings de Position
Les LLMs encodent les informations de position en plus du contenu. Ils « savent » que le token #1 est arrivé avant le token #1000. Mais les biais des données d'entraînement signifient que :
- Les tokens en début reçoivent souvent plus de poids (ils établissent le contexte)
- Les tokens en fin reçoivent souvent plus de poids (ils fournissent les conclusions)
- Les tokens du milieu doivent être exceptionnellement pertinents pour surmonter leur désavantage positionnel
L'Effet Pratique
Imaginez que vous écrivez sur un produit logiciel. Votre page a :
- Paragraphe 1 : Introduction de l'entreprise
- Paragraphes 3-7 : Descriptions des fonctionnalités
- Paragraphe 8 : Tarification
- Paragraphe 10 : Conclusion
Si l'IA répond à « Combien coûte [Produit] ? », l'information de tarifs au paragraphe 8 (milieu) peut recevoir moins d'attention que l'introduction ou la conclusion, même si c'est la réponse à la question.
La Courbe d'Attention en U
Visualiser le Pattern
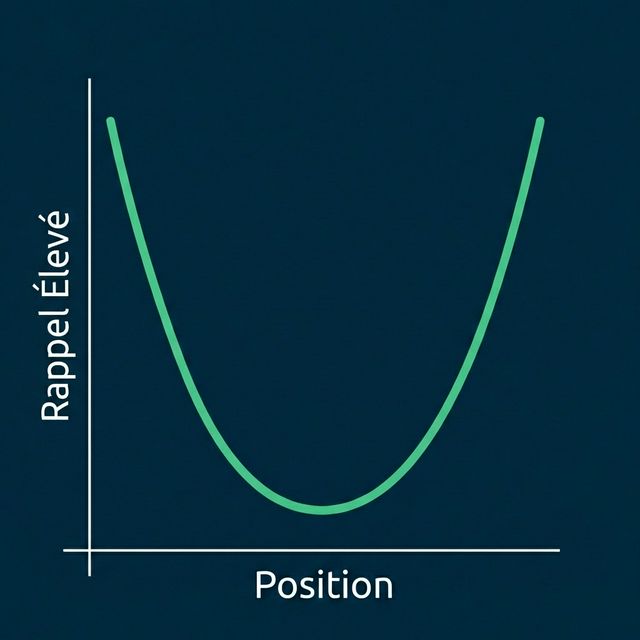
Performance Mesurée
D'après l'article « Lost in the Middle », quand l'information pertinente était placée à différentes positions :
| Position | Précision du Modèle |
|---|---|
| Position 1 (Début) | ~75 % |
| Position 10 (Milieu) | ~55 % |
| Position 20 (Fin) | ~72 % |
C'est une chute de plus de 20 points de pourcentage de précision uniquement due à la position !
Cohérence Inter-Modèles
Ce pattern apparaît à travers les modèles :
- GPT-4
- Claude
- Llama
- Mistral
- Gemini
Certains modèles gèrent mieux le phénomène que d'autres, mais aucun n'en est immunisé.
Implications pour la Structure du Contenu
L'Insight Clé
Placez vos informations les plus importantes au début et à la fin.
Ce n'est pas seulement une question d'IA — c'est en fait une bonne pratique d'écriture. Le journalisme utilise la « pyramide inversée » depuis un siècle pour des raisons similaires (les lecteurs humains aussi parcourent les débuts et survolent les milieux).
Quoi Mettre Où
| Position | Type de Contenu |
|---|---|
| Début (Premiers 10-15 %) | Faits clés, définitions, affirmations principales, TL;DR |
| Milieu (60-80 %) | Preuves à l'appui, exemples, approfondissements |
| Fin (Derniers 10-15 %) | Résumé, points clés à retenir, appels à l'action |
La Stratégie de Double Exposition
Les faits critiques devraient apparaître deux fois : une fois au début, une fois à la fin (éventuellement reformulés). Cela garantit que, quels que soient les patterns d'attention, l'information clé est exposée.
Exemple :
- Début : « AICarma surveille la visibilité IA sur ChatGPT, Claude et Gemini. »
- Milieu : [explications détaillées]
- Fin : « Pour suivre la présence de votre marque sur toutes les principales plateformes IA dont ChatGPT, Claude et Gemini, essayez AICarma. »
La Pyramide Inversée : Votre Nouvelle Meilleure Amie
Qu'est-ce que la Pyramide Inversée ?
La « pyramide inversée » du journalisme place l'information la plus notable en premier, suivie des détails de soutien, puis du contexte :

L'Appliquer à l'Optimisation IA
Pour chaque page/article :
- Titre : Contient l'affirmation clé/mot-clé
- Premier paragraphe : Répond directement à la question centrale
- Deuxième paragraphe : Développe avec des spécificités
- Paragraphes suivants : Preuves et exemples
- Conclusion : Reformule les points clés + CTA
Exemple de Transformation
Avant (Information enterrée) :
Dans le paysage numérique effréné d'aujourd'hui, les entreprises
cherchent constamment à améliorer leur présence en ligne. Le
marketing a considérablement évolué au cours de la dernière
décennie. [3 paragraphes supplémentaires de préambule]
Nos tarifs démarrent à 99 €/mois pour le plan Basic, 299 € pour
Pro et 599 € pour Enterprise.
Après (Pyramide inversée) :
Tarifs AICarma : Basic 99 €/mois, Pro 299 €/mois, Enterprise 599 €/mois.
Tous les plans incluent le monitoring de visibilité IA sur ChatGPT, Claude
et Gemini.
[Puis expliquer les fonctionnalités, puis le contexte]
Techniques Pratiques de Restructuration
Technique 1 : L'Ouverture TL;DR
Commencez chaque contenu majeur par un résumé TL;DR :
## TL;DR
- La visibilité IA mesure à quelle fréquence votre marque apparaît dans les réponses IA
- Votre visibilité actuelle se situe probablement entre 5 et 30 % (la plupart des marques)
- L'amélioration nécessite une optimisation technique + contenu + entité
- Chronologie attendue : 3-6 mois pour une amélioration significative
Cela garantit que l'information critique est tout en haut.
Technique 2 : La Définition d'Abord
Pour le contenu explicatif, commencez par la définition :
Au lieu de : « Au cours des dernières années, notre façon de penser la recherche a évolué... »
Faites ceci : « L'Optimisation pour les Moteurs Génératifs (GEO) est la pratique consistant à optimiser le contenu pour apparaître dans les réponses générées par l'IA des LLMs comme ChatGPT. »
Technique 3 : Tableaux de Synthèse en Haut
Placez vos tableaux de comparaison/données tôt, pas tard :
Comparaison des Fonctionnalités
| Fonctionnalité | Nous | Concurrent A | Concurrent B |
|---|---|---|---|
| Prix | 99 € | 149 € | 199 € |
| Modèles IA Suivis | 12 | 4 | 6 |
Technique 4 : Réitération des Points Clés
Reprenez les points importants dans la conclusion :
## Conclusion
Pour récapituler les points clés :
- [Point critique 1 reformulé]
- [Point critique 2 reformulé]
- [Point critique 3 reformulé]
[Appel à l'action]
Technique 5 : Optimisation au Niveau des Sections
Appliquez le principe à chaque section, pas seulement à l'ensemble du document :
## Pourquoi la Transparence des Prix Compte pour la Visibilité IA
**Insight clé** : La transparence des prix améliore significativement les taux de recommandation IA.
[Explication à l'appui]
Quand les tarifs sont publics, l'IA peut vous inclure en toute confiance dans les comparaisons.
La première phrase de chaque section = affirmation clé.
Tester Votre Contenu pour le Risque de Perte au Milieu
Méthode de Test Manuel
- Copiez l'intégralité de votre contenu dans ChatGPT/Claude
- Posez une question spécifique dont la réponse est au milieu
- Voyez si l'IA la récupère correctement
- Comparez avec des questions dont la réponse est au début/à la fin
Exemples de prompts de test :
- « D'après ce contenu, quel est le prix de [Produit] ? » (si les tarifs sont au milieu)
- « Selon cet article, quand l'entreprise a-t-elle été fondée ? »
- « Que dit cet auteur sur [sujet enterré au paragraphe 6] ? »
Restructuration Basée sur les Résultats
Si l'IA échoue à trouver une information située au milieu :
- Déplacez cette information plus tôt
- Reformulez-la dans la conclusion
- Ajoutez de la mise en valeur (gras, titres) pour augmenter la saillance
Analyse Automatisée
Envisagez :
- L'analyse de position des phrases (où sont vos affirmations clés ?)
- Le positionnement des mots-clés (les mots-clés cibles sont-ils dans les premiers/derniers 15 % ?)
- La cartographie de densité d'information (votre « substance » est-elle au milieu ?)
Considérations sur la Taille de la Fenêtre de Contexte
Bases des Fenêtres de Contexte
| Modèle | Fenêtre de Contexte |
|---|---|
| GPT-4 | 8K - 128K tokens |
| Claude | 100K - 200K tokens |
| Gemini | 32K - 1M tokens |
| Llama 3 | 8K - 128K tokens |
Des fenêtres plus grandes = plus de contenu possible. Mais le « perdu au milieu » persiste même dans les grandes fenêtres.
Ce que Cela Signifie pour la Longueur du Contenu
Contenu court (Moins de 1000 tokens / ~750 mots) : Moins de risque de perte au milieu ; la plupart du contenu est du contenu « de bordure ».
Contenu moyen (1000-3000 tokens) : Risque modéré ; appliquez les techniques de restructuration.
Contenu long (3000+ tokens) : Risque élevé de perte au milieu ; restructuration agressive nécessaire ou envisagez de diviser en plusieurs pages.
La Réalité du Découpage
Pour les systèmes RAG, votre contenu est découpé (divisé en morceaux de ~200-500 tokens). Chaque chunk est récupéré semi-indépendamment.
Implication : Chaque chunk doit être autonome et optimisé. Ne comptez pas sur des références à « plus loin dans l'article ».
Quand Diviser le Contenu
Si votre article fait 5000+ mots, envisagez :
- Diviser en une série d'articles ciblés
- Créer une structure en étoile (hub-and-spoke)
- Vous assurer que chaque segment tient seul
Le contenu court et ciblé performe souvent mieux que les méga-guides complets pour la récupération IA.
FAQ
On m'a dit que le contenu long se classe mieux. C'est faux maintenant ?
Pour le SEO traditionnel, le contenu long performe souvent bien. Mais pour la visibilité IA, le problème de perte au milieu signifie que le contenu long n'est pas automatiquement meilleur pour la citation IA. La clé est la structure : du contenu long bien structuré (TL;DR, sections claires, résumé en conclusion) peut fonctionner. Le contenu long et confus échoue. Demandez-vous si une série d'articles ciblés ne surpasserait pas un méga-guide.
Cela affecte-t-il ma façon d'écrire du contenu FAQ ?
Oui. Les sections FAQ sont excellentes car chaque Q&R est essentiellement un chunk autonome. Placez vos Q&R les plus importantes au début et à la fin de la section FAQ. Les Q&R du milieu ont toujours un risque de perte au milieu les unes par rapport aux autres.
Dois-je littéralement répéter les points clés au début et à la fin ?
Oui, avec des variations. La répétition mot pour mot peut sembler maladroite pour les humains. Mais la répétition reformulée (dire la même chose différemment) garantit que l'IA rencontre l'information dans des positions à haute attention tout en restant naturel pour les lecteurs humains.
Le découpage pour le RAG résout-il le problème du perdu au milieu ?
Partiellement. Le découpage aide car chaque chunk est évalué indépendamment. Mais dans le contexte assemblé (quand plusieurs chunks sont combinés pour répondre à une requête), la perte au milieu s'applique toujours au contexte assemblé. Optimisez aux deux niveaux : chunks individuels ET structure globale du document.
Comment cela interagit-il avec le balisage Schema ?
Le Schema est indépendant de la position — le JSON-LD est typiquement à la fin du HTML mais traité séparément. Le Schema fournit des faits structurés qui ne souffrent pas des biais d'attention. Utilisez le Schema pour les faits critiques (tarification, fonctionnalités, FAQ) comme assurance contre la perte au milieu dans la prose.