Le Framework T.R.U.S.T. : Un Audit en 5 Piliers pour Dominer la Recherche IA
Dernière mise à jour : 25 August 2025
Quand la visibilité IA chute, le premier réflexe est la panique. Le deuxième est de deviner.
« Peut-être qu'il faut plus de contenu. » « Peut-être que c'est une mise à jour de modèle. » « Peut-être qu'on devrait essayer l'injection de prompt. » (S'il vous plaît, ne le faites pas.)
Deviner, c'est ce qui arrive quand vous n'avez pas de framework de diagnostic. Et dans un domaine aussi complexe que l'Optimisation pour les Moteurs Génératifs, où des dizaines de variables interagissent simultanément à travers plusieurs modèles IA, deviner coûte cher.
C'est pourquoi nous avons développé le Framework T.R.U.S.T. — un système d'audit structuré en cinq piliers pour diagnostiquer et améliorer la visibilité de votre marque dans la recherche IA.
Tout comme le framework E-E-A-T de Google (Expérience, Expertise, Autorité, Fiabilité) a donné aux praticiens SEO un modèle mental pour l'évaluation de la qualité, T.R.U.S.T. donne aux praticiens GEO un modèle diagnostique pour la visibilité IA :
- T — Technique
- R — Relevance
- U — Utilisateurs
- S — Signaux
- T — Trust (Confiance)
Chaque pilier traite un mode de défaillance distinct. Quand votre visibilité chute, vous auditez selon T.R.U.S.T. pour identifier quel pilier se fissure — puis vous le corrigez systématiquement au lieu de lancer des idées au hasard.
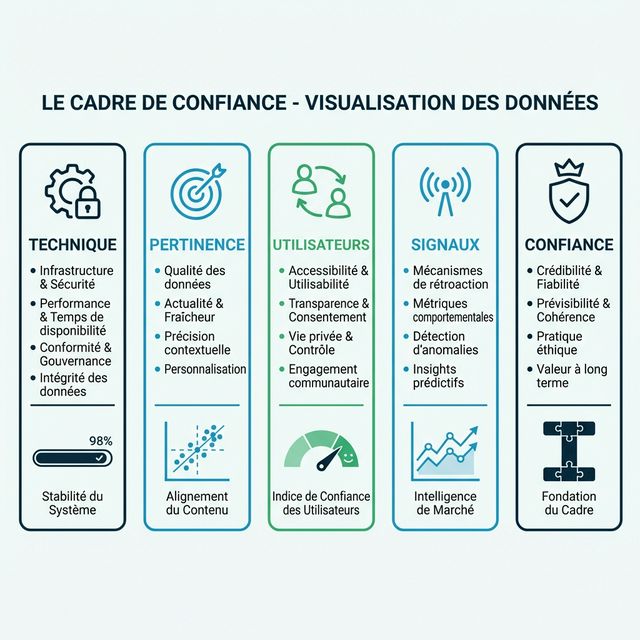
Table des Matières
- Pourquoi les Frameworks Comptent en GEO
- T — Technique : L'IA Peut-elle Accéder à Vos Données ?
- R — Relevance : Votre Contenu Correspond-il à l'Intention ?
- U — Utilisateurs : Résolvez-vous des Tâches, Pas Seulement des Clics ?
- S — Signaux : Qui d'Autre Dit Que Vous Êtes Bon ?
- T — Trust : Pourquoi l'IA Devrait-elle Vous Croire ?
- Diagnostiquer les Baisses : L'Arbre de Décision
- Noter Votre Marque contre T.R.U.S.T.
- Étude de Cas : Appliquer le Framework
- FAQ
Pourquoi les Frameworks Comptent en GEO
Le paysage de la recherche IA est véritablement complexe. Votre visibilité est influencée par la composition des données d'entraînement, la qualité de récupération en temps réel, la reconnaissance d'entités, les contraintes du prompt système, la température du modèle, le contexte de conversation, et plus encore.
Sans framework, vous optimisez des variables individuelles en isolation — comme ajuster les basses d'une chaîne stéréo sans comprendre la chanson. Avec un framework, vous voyez le mix complet et pouvez faire des ajustements éclairés.
La recherche du Computer Science and Artificial Intelligence Laboratory (CSAIL) du MIT a montré que les approches diagnostiques systématiques surpassent le dépannage ad hoc dans les systèmes adaptatifs complexes d'un facteur de 3-5x (Sontag & Shah, « Causal Identification in Complex Systems », 2023). T.R.U.S.T. applique ce principe au GEO.
T — Technique : L'IA Peut-elle Accéder à Vos Données ?
Le premier pilier est le plus fondamental et le plus souvent négligé. Si les crawlers IA ne peuvent pas physiquement accéder à votre contenu, rien d'autre ne compte.
La Checklist Technique
| Vérification | Question | Ressource |
|---|---|---|
| robots.txt | GPTBot, ClaudeBot et PerplexityBot sont-ils autorisés ? | Guide Robots.txt pour l'IA |
| llms.txt | Avez-vous une carte de contenu lisible par machine ? | Qu'est-ce que llms.txt ? |
| Vitesse de Page | Votre contenu peut-il être récupéré dans les limites de timeout RAG (~2-5 secondes) ? | Google PageSpeed Insights |
| Rendu | Votre contenu est-il dans le code source HTML, ou caché derrière JavaScript/SPA ? | Test View Page Source |
| Tags Canoniques | Les crawlers IA suivent-ils les bonnes URLs canoniques ? | Outils d'audit de site |
Pourquoi C'est Plus Important Maintenant
Les moteurs de recherche traditionnels comme Google ont investi des décennies dans des pipelines de rendu sophistiqués capables d'exécuter JavaScript, suivre les redirections et extraire le contenu de SPAs complexes. Les crawlers IA sont comparativement primitifs. Beaucoup fonctionnent comme Googlebot du début des années 2000 : ils lisent le HTML brut, suivent les liens basiques et passent à autre chose.
Si votre contenu est rendu côté client avec React mais n'a pas de rendu côté serveur ou de génération statique, les crawlers IA peuvent voir une page blanche. La recherche de l'étude Ahrefs 2024 sur le crawling IA a trouvé que 23 % des sites entreprise bloquent involontairement au moins un bot IA majeur via un robots.txt mal configuré ou des barrières techniques.
Diagnostiquer une Défaillance Technique
Symptôme : Chute soudaine et drastique de visibilité sur tous les modèles IA simultanément.
Cause Racine : Généralement un déploiement qui a modifié robots.txt, une mauvaise configuration CDN, ou une migration qui a cassé le rendu côté serveur.
Correctif : Audit d'urgence de tous les points d'accès. Vérifier robots.txt, tester avec curl pour voir ce que les bots IA voient, vérifier que llms.txt est accessible.
R — Relevance : Votre Contenu Correspond-il à l'Intention ?
L'accès technique est nécessaire mais insuffisant. Une fois que l'IA peut lire votre contenu, la question devient : trouve-t-elle ce qu'elle cherche ?
Relevance Sémantique vs. Correspondance de Mots-Clés
Le SEO traditionnel nous a formés à l'optimisation de mots-clés. Le GEO exige la relevance sémantique — votre contenu doit correspondre au sens de la requête, pas seulement aux mots.
Les LLMs traitent le texte à travers des vecteurs d'embedding — des représentations mathématiques du sens dans un espace de haute dimension. La « distance » de votre contenu par rapport à la requête dans cet espace vectoriel détermine la relevance de récupération. Comme démontré par Reimers & Gurevych (« Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks », EMNLP 2019), le contenu sémantiquement similaire se regroupe indépendamment du choix exact des mots.
Implication : Écrire pour l'IA signifie couvrir le territoire sémantique d'un sujet, pas juste saupoudrer des mots-clés ciblés. Si quelqu'un demande « Comment améliorer la présence de ma marque dans ChatGPT ? », votre contenu doit couvrir des concepts comme la visibilité IA, le polling de modèle, la probabilité de citation et la reconnaissance d'entités — même si ces phrases exactes n'apparaissent pas dans la requête.
Positionnement dans la Fenêtre de Contexte
Notre guide d'Optimisation de la Fenêtre de Contexte couvre cela en profondeur, mais les résultats clés de la recherche « Lost in the Middle » de Liu et al. méritent d'être rappelés :
- Les modèles font plus attention aux informations au début et à la fin de leur fenêtre de contexte
- L'information au milieu est « perdue » — recevant littéralement des poids d'attention plus faibles
- Mettre vos affirmations clés en avant augmente leur probabilité d'être citées
Fraîcheur et Récence
Pour les systèmes alimentés par RAG comme Perplexity, la fraîcheur du contenu compte. La recherche de Microsoft (Kasai et al., « RealTime QA », 2022) montre que les systèmes de récupération préfèrent fortement le contenu récemment mis à jour pour répondre aux requêtes d'actualité.
Action : Mettez à jour vos pages clés régulièrement. Même des rafraîchissements mineurs (statistiques actualisées, références à l'année en cours) signalent la récence aux systèmes de récupération.
U — Utilisateurs : Résolvez-vous des Tâches, Pas Seulement des Clics ?
Le « U » est peut-être le pilier le plus tourné vers l'avenir. À mesure que l'IA évolue de répondre à des questions à accomplir des tâches — via les agents IA autonomes — votre contenu doit servir des actions, pas seulement des informations.
De l'Information à l'Accomplissement de Tâches
Quand un utilisateur demande à ChatGPT « Réserve-moi un restaurant à Paris pour vendredi soir », l'IA ne veut pas montrer une liste de 10 restaurants. Elle veut accomplir la tâche :
- Trouver la disponibilité
- Correspondre aux préférences
- Faire la réservation
- Confirmer les détails
Si votre restaurant a un système de réservation accessible par API, des données de disponibilité structurées et des tarifs clairs — vous êtes optimisé pour l'accomplissement de tâches. Si vous avez un beau menu PDF et un numéro « appelez-nous » — vous êtes invisible pour l'agent.
Signaux d'Expérience Utilisateur
Même pour les requêtes d'information, les signaux d'engagement utilisateur comptent. Si les utilisateurs cliquent systématiquement sur votre site depuis les citations IA et passent du temps à lire, cette boucle de rétroaction positive renforce votre visibilité.
| Signal | Impact | Optimisation |
|---|---|---|
| Clic depuis la citation | Élevé | Écrire des méta-descriptions et titres de page convaincants |
| Temps sur la page | Moyen | Créer du contenu véritablement précieux et approfondi |
| Taux de rebond | Moyen | S'assurer que le contenu tient la promesse de l'IA |
| Accomplissement de tâche | Très Élevé | Permettre les actions (réservation, achat, téléchargement) |
La recherche sur le comportement zéro-clic (SparkToro, « Zero-Click Search Study », 2024) révèle que si les taux de clic globaux baissent, la qualité des clics restants augmente. Les utilisateurs qui cliquent depuis les recommandations IA sont de haute intention — et les plateformes le remarquent.
S — Signaux : Qui d'Autre Dit Que Vous Êtes Bon ?
Le quatrième pilier traite de la corroboration externe — l'équivalent IA des backlinks, mais plus large et plus nuancé.
Pourquoi les Signaux l'Emportent sur l'Auto-Promotion
Un LLM qui évalue votre marque ne lit pas juste votre site web. Il lit ce que tout le monde dit de vous. Si votre site affirme « Nous sommes le meilleur CRM pour les startups » mais que les avis G2 disent « Support client terrible » et les fils Reddit disent « Évitez ce produit » — l'IA reflétera le consensus, pas votre copie marketing.
C'est le principe de la triangulation multi-source, documenté extensivement dans la littérature des graphes de connaissances (Dong et al., « Knowledge Vault: A Web-Scale Approach to Probabilistic Knowledge Fusion », KDD 2014). L'IA assigne une confiance plus élevée aux faits corroborés à travers plusieurs sources indépendantes.
Sources de Signaux Classées par Poids IA
| Type de Source | Poids IA | Votre Stratégie |
|---|---|---|
| Wikipedia | ★★★★★ | Maintenir une présence Wikipedia précise |
| Citations académiques | ★★★★★ | Publier des recherches, se faire citer par des articles |
| Plateformes d'avis (G2, Capterra) | ★★★★ | Gérer activement les profils d'avis |
| ★★★★ | Construire une présence communautaire authentique (Stratégie Reddit) | |
| Presse sectorielle | ★★★★ | Gagner de la couverture, pas juste des placements payants |
| Réseaux sociaux | ★★ | Utile pour les signaux de récence, moins pour l'autorité |
| Votre propre blog | ★★ | Important mais insuffisant seul |
Le Sentiment comme Signal
Il ne suffit pas d'être mentionné. Vous devez être mentionné positivement. Notre méthodologie du Score de Visibilité IA suit non seulement la fréquence de citation mais le sentiment — car un LLM qui « connaît » votre marque mais l'associe à des expériences négatives recommandera activement contre vous.
Les organisations entreprise suivent de plus en plus le sentiment de marque à travers les modèles IA dans le cadre de leur stratégie de gestion de réputation.
T — Trust : Pourquoi l'IA Devrait-elle Vous Croire ?
Le pilier final est la clé de voûte. La confiance est le résultat cumulatif de tous les autres piliers, mais elle possède aussi ses propres facteurs indépendants.
Autorité et Auctorialité
L'E-E-A-T de Google met l'accent sur « l'Expérience » et « l'Expertise ». Les modèles IA vont plus loin. La recherche de l'Allen Institute for AI (Wadden et al., « SciFact: Joint Scientific Document Retrieval and Fact-Checking », EMNLP 2020) démontre que les LLMs évaluent la crédibilité de la source quand ils pèsent des affirmations concurrentes.
Implications pratiques :
- Auteurs nommés : Le contenu avec des auteurs nommés et accrédités est mieux pondéré que les blogs d'entreprise anonymes
- Affiliation institutionnelle : Une étude publiée par « des chercheurs du MIT » a plus de poids qu'une de « notre équipe data »
- Réseaux de citations : Si votre contenu cite des sources crédibles, et que des sources crédibles vous citent, vous créez une boucle de confiance
YMYL : Le Gardien de la Confiance
Pour le contenu santé, finance, juridique et sécurité — ce que les systèmes IA classifient comme YMYL (Your Money or Your Life) — la confiance n'est pas un simple facteur de classement. C'est un gardien. Les modèles supprimeront activement le contenu non fiable dans ces catégories pour réduire la responsabilité en cas de dommage.
Si vous opérez dans un espace YMYL, le pilier Confiance n'est pas optionnel — il est existentiel.
La Consistance Construit la Confiance
La confiance se compose dans le temps. Une marque qui a été constamment présente, constamment précise et constamment citée à travers les versions de modèles développe une « adhérence au Knowledge Graph » que les nouveaux entrants ne peuvent pas répliquer du jour au lendemain.
C'est pourquoi l'Entity SEO compte autant. Les entités fortes persistent à travers les mises à jour de modèles. Les entités faibles dérivent et disparaissent.
Diagnostiquer les Baisses : L'Arbre de Décision
Quand votre visibilité IA chute, ne paniquez pas. Auditez méthodiquement :
| Symptôme | Première Vérification | Pilier Probable |
|---|---|---|
| Chute soudaine, tous les modèles | Accès technique (robots.txt, site en panne ?) | Technique |
| Déclin graduel, requêtes catégorie | Fraîcheur du contenu, alignement sémantique | Relevance |
| Visible mais faible taux de clic | Expérience utilisateur, qualité du contenu | Utilisateurs |
| Concurrent monte, vous stagnez | Mentions externes, profils d'avis | Signaux |
| Volatil, dépendant du modèle | Marqueurs d'autorité, présence d'entité | Trust |
Noter Votre Marque contre T.R.U.S.T.
Faites cette auto-évaluation rapide (notez chaque pilier de 1 à 5) :
| Pilier | Note 1 (Faible) | Note 5 (Fort) |
|---|---|---|
| Technique | Crawlers IA partiellement bloqués | Accès complet + llms.txt + Schema |
| Relevance | Contenu générique, bourrage de mots-clés | Couverture sémantique, affirmations en avant, contenu frais |
| Utilisateurs | Information seule, pas d'actions | Permettant les tâches, accessible par API, données structurées |
| Signaux | Auto-promotion uniquement | Wikipedia + Avis + Reddit + Presse |
| Trust | Blog anonyme, pas de citations | Auteurs nommés, sources citées, autorité sectorielle |
Score 20-25 : Vous êtes compétitif. Concentrez-vous sur la progression. Score 15-19 : Vous avez des lacunes. Priorisez le pilier le plus faible. Score inférieur à 15 : Travail fondamental nécessaire. Commencez par le Technique.
Étude de Cas : Appliquer le Framework
Une entreprise SaaS B2B suivie par AICarma apparaissait dans 45 % des requêtes ChatGPT pertinentes mais seulement 12 % des requêtes Perplexity. En utilisant T.R.U.S.T. :
- Technique : Perplexity s'appuie sur le crawling en temps réel. Leur site avait
PerplexityBotbloqué dans robots.txt. (Corrigé → pilier T.) - Relevance : Leurs landing pages étaient lourdes en marketing avec une profondeur sémantique limitée. (Ajout de documentation technique → pilier R.)
- Signaux : Aucune présence sur Reddit ou Stack Overflow. (Construction d'un engagement communautaire authentique → pilier S.)
Résultat : La visibilité Perplexity s'est améliorée de 12 % à 38 % en 6 semaines. ChatGPT est resté stable. Le Score de Visibilité IA global a augmenté de 22 points.
FAQ
En quoi T.R.U.S.T. est-il différent de l'E-E-A-T de Google ?
L'E-E-A-T est un framework d'évaluation de la qualité conçu pour les classements de recherche organisés par des humains. T.R.U.S.T. est un framework de diagnostic et d'optimisation conçu pour les systèmes IA probabilistes. Il couvre l'accessibilité technique, l'accomplissement de tâches et la corroboration externe — des dimensions que l'E-E-A-T ne traite pas car elles n'étaient pas pertinentes pour la recherche traditionnelle.
Par quel pilier dois-je commencer ?
Commencez toujours par le Technique. Si les crawlers IA ne peuvent pas accéder à votre contenu, rien d'autre ne compte. Après le Technique, priorisez le pilier qui a obtenu la note la plus basse dans votre auto-évaluation.
À quelle fréquence dois-je faire un audit T.R.U.S.T. ?
Nous recommandons un audit complet mensuel et un monitoring hebdomadaire des indicateurs clés. Comme décrit dans notre guide du Flywheel GEO, le monitoring continu détecte les problèmes plus vite que les audits périodiques.
T.R.U.S.T. s'applique-t-il à toutes les industries ?
Oui, mais la pondération des piliers varie. Pour les industries YMYL (santé, finance), le pilier Trust a un poids disproportionné. Pour les entreprises SaaS, Signaux et Relevance tendent à être les plus grands différenciateurs. Pour les commerces locaux, les piliers Technique et Utilisateurs sont critiques.
Puis-je utiliser T.R.U.S.T. pour l'analyse concurrentielle ?
Absolument. Notez vos trois principaux concurrents par rapport au framework. Là où ils sont faibles et vous êtes fort — c'est votre avantage compétitif. Là où ils sont forts et vous êtes faible — c'est votre priorité. Notre guide d'Intelligence Concurrentielle complète T.R.U.S.T. avec des méthodologies spécifiques de suivi concurrentiel.