Optimización de Ventana de Contexto: Escribiendo para la 'Curva de Atención en U'
Última actualización: 5 December 2025
Aquí hay una frase que te hará repensar cómo estructuras tu contenido: Los Modelos de Lenguaje Grande son malos prestando atención al medio de documentos largos.
Esto no es una peculiaridad menor — es una característica fundamental de cómo funciona la IA basada en transformers. La investigación ha demostrado consistentemente que los LLMs exhiben lo que se llama la "curva de atención en U" — prestan la mayor atención a la información al principio y al final de su ventana de contexto, mientras que la información en el medio se ignora parcialmente.
Para creadores de contenido, marketeros y cualquiera que intente que su contenido sea citado por IA, esto tiene implicaciones profundas. Si tus datos clave están enterrados en el párrafo 7 de un artículo de 15 párrafos, la IA podría literalmente no "verlos," incluso si el rastreador recuperó tu página.
Entender y optimizar para la atención de la ventana de contexto es uno de los aspectos más ignorados de la Optimización para Motores Generativos. Arreglemos eso.
Tabla de Contenidos
- El Fenómeno "Lost in the Middle"
- Cómo Funciona Realmente la Atención de la IA
- La Curva de Atención en U
- Implicaciones para la Estructura del Contenido
- La Pirámide Invertida: Tu Nuevo Mejor Aliado
- Técnicas Prácticas de Reestructuración
- Probando Tu Contenido por Riesgo de Pérdida Media
- Consideraciones sobre el Tamaño de la Ventana de Contexto
- FAQ
El Fenómeno "Lost in the Middle"
La Investigación
Un paper histórico de 2023 de investigadores de Stanford, Berkeley y Samaya AI titulado "Lost in the Middle" demostró una limitación crítica de los LLMs: cuando se les dan ventanas de contexto largas, los modelos tienen dificultades para usar la información del medio de ese contexto.
Hallazgos Clave:
- El rendimiento cae significativamente cuando la información relevante está en el medio
- Incluso modelos con ventanas de 4K, 16K o 32K tokens exhiben este comportamiento
- El efecto es pronunciado incluso en modelos comerciales bien entrenados
- Ventanas de contexto más grandes no resuelven el problema
Qué Significa para el Contenido
Cuando tu página es recuperada por RAG (Generación Aumentada por Recuperación), se convierte en parte de la ventana de contexto de la IA. Si tu punto de venta clave está en el medio de tu página, puede "perderse" para la atención del modelo.
| Posición en el Documento | Atención de la IA | Probabilidad de Citación |
|---|---|---|
| Primer 10% | Alta | Alta |
| Medio 80% | Menor | Reducida |
| Último 10% | Alta | Alta |
Por Qué Sucede
No es un error — es cómo funcionan los mecanismos de atención de los transformers. El entrenamiento anima a los modelos a depender de los extremos posicionales. La información al principio establece contexto; la información al final proporciona conclusiones.
Cómo Funciona Realmente la Atención de la IA
El Mecanismo de Atención
Los LLMs usan "atención" para decidir en qué tokens (palabras/piezas) del input enfocarse al generar la salida. Para cada token de salida, el modelo calcula puntuaciones de atención a través de todos los tokens de entrada.
En teoría, la atención permite enfocarse en cualquier parte del input. En la práctica, los patrones de atención muestran fuertes sesgos hacia:
- Recencia (tokens cercanos)
- Posición (tokens tempranos y tardíos)
- Relevancia semántica (tokens coincidentes)
Embeddings de Posición
Los LLMs codifican información de posición junto con el contenido. "Saben" que el token #1 vino antes del token #1000. Pero los sesgos de los datos de entrenamiento significan:
- Los tokens tempranos reciben más peso (establecen contexto)
- Los tokens tardíos reciben más peso (proporcionan conclusiones)
- Los tokens del medio deben ser excepcionalmente relevantes para superar la desventaja posicional
La Curva de Atención en U
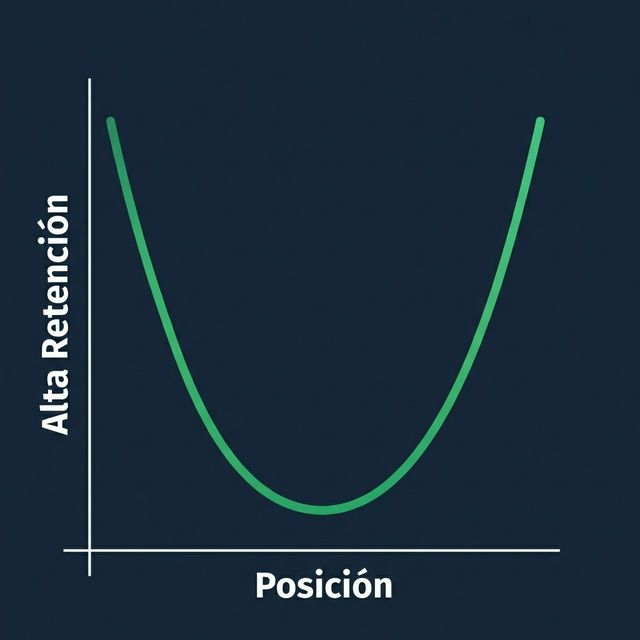
Rendimiento Medido
Del paper "Lost in the Middle," cuando la información relevante se colocó en diferentes posiciones:
| Posición | Precisión del Modelo |
|---|---|
| Posición 1 (Inicio) | ~75% |
| Posición 10 (Medio) | ~55% |
| Posición 20 (Final) | ~72% |
¡Esa es una caída de más de 20 puntos porcentuales en precisión solo por la posición!
Consistencia Entre Modelos
Este patrón aparece en todos los modelos:
- GPT-4
- Claude
- Llama
- Mistral
- Gemini
Algunos modelos lo manejan mejor que otros, pero ninguno es inmune.
Implicaciones para la Estructura del Contenido
El Insight Clave
Pon tu información más importante al principio y al final.
Esto no es solo sobre IA — es realmente una buena práctica de escritura. El periodismo ha usado la "pirámide invertida" durante un siglo por razones similares (los lectores humanos también escanean los principios y hojean los medios).
Qué Poner Dónde
| Posición | Tipo de Contenido |
|---|---|
| Principio (Primer 10-15%) | Datos clave, definiciones, afirmaciones principales, TL;DR |
| Medio (60-80%) | Evidencia de soporte, ejemplos, profundidad |
| Final (Último 10-15%) | Resumen, conclusiones clave, llamadas a la acción |
La Estrategia de Doble Exposición
Los datos críticos deben aparecer dos veces: una al principio, otra al final (posiblemente reformulados). Esto asegura que, independientemente de los patrones de atención, la información clave esté expuesta.
Ejemplo:
- Principio: "AICarma monitorea la visibilidad IA en ChatGPT, Claude y Gemini."
- Medio: [explicaciones detalladas]
- Final: "Para rastrear la presencia de tu marca en todas las principales plataformas de IA incluyendo ChatGPT, Claude y Gemini, prueba AICarma."
La Pirámide Invertida: Tu Nuevo Mejor Aliado
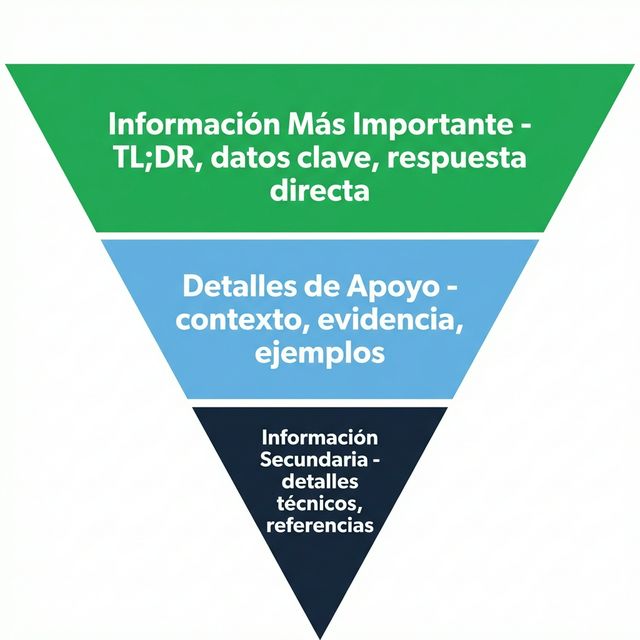
¿Qué Es la Pirámide Invertida?
La "pirámide invertida" del periodismo pone la información más noticiable primero, seguida de detalles de soporte, luego el contexto.
Aplicándola a la Optimización para IA
Para cada página/artículo:
- Titular: Contiene la afirmación clave/keyword
- Primer párrafo: Responde directamente la pregunta central
- Segundo párrafo: Expande con especificaciones
- Párrafos siguientes: Evidencia y ejemplos
- Conclusión: Reafirma puntos clave + CTA
Ejemplo de Transformación
Antes (Lede enterrado):
En el panorama digital acelerado de hoy, las empresas buscan
constantemente formas de mejorar su presencia online. El marketing
ha evolucionado significativamente en la última década.
[3 párrafos más de preámbulo]
Nuestros precios comienzan en $99/mes para el plan Básico...
Después (Pirámide invertida):
Precios de AICarma: Básico $99/mes, Pro $299/mes, Enterprise $599/mes.
Todos los planes incluyen monitoreo de visibilidad IA en ChatGPT,
Claude y Gemini.
[Luego explicar funcionalidades, luego contexto]
Técnicas Prácticas de Reestructuración
Técnica 1: La Apertura TL;DR
Comienza cada pieza importante con un resumen TL;DR:
## TL;DR
- La visibilidad IA mide con qué frecuencia tu marca aparece en respuestas IA
- Tu visibilidad actual probablemente está entre 5-30% (la mayoría de marcas)
- Mejorar requiere optimización técnica + contenido + entidad
- Cronograma esperado: 3-6 meses para mejora significativa
Técnica 2: Definición Primero
Para contenido que explica conceptos, lidera con la definición:
En lugar de: "En los últimos años, la forma en que pensamos sobre la búsqueda ha evolucionado..."
Haz esto: "La Optimización para Motores Generativos (GEO) es la práctica de optimizar contenido para aparecer en respuestas generadas por IA desde LLMs como ChatGPT."
Técnica 3: Tablas Resumen al Inicio
Coloca tus tablas de comparación/datos temprano, no tarde.
Técnica 4: Reiteración de Puntos Clave
Repite los puntos importantes en la conclusión.
Técnica 5: Optimización a Nivel de Sección
Aplica el principio a cada sección, no solo al documento completo. La primera frase de cada sección = afirmación clave.
Probando Tu Contenido por Riesgo de Pérdida Media
Método de Prueba Manual
- Copia tu contenido completo en ChatGPT/Claude
- Haz una pregunta específica cuya respuesta está en el medio
- Observa si la IA la recupera correctamente
- Compara con preguntas cuyas respuestas están al principio/final
Reestructuración Basada en Resultados
Si la IA falla en encontrar información ubicada en el medio:
- Mueve esa información más temprano
- Reitérala en la conclusión
- Agrega resaltado (negritas, encabezados) para aumentar la prominencia
Consideraciones sobre el Tamaño de la Ventana de Contexto
Conceptos Básicos de la Ventana de Contexto
| Modelo | Ventana de Contexto |
|---|---|
| GPT-4 | 8K - 128K tokens |
| Claude | 100K - 200K tokens |
| Gemini | 32K - 1M tokens |
| Llama 3 | 8K - 128K tokens |
Ventanas más grandes = pueden contener más contenido. Pero "lost in the middle" persiste incluso en ventanas grandes.
Qué Significa para la Longitud del Contenido
Contenido corto (Menos de 1000 tokens / ~750 palabras): Menos riesgo de pérdida media; la mayor parte del contenido es contenido de "borde."
Contenido medio (1000-3000 tokens): Riesgo moderado; aplica técnicas de reestructuración.
Contenido largo (3000+ tokens): Alto riesgo de pérdida media; reestructuración agresiva necesaria o considerar dividir en múltiples páginas.
La Realidad del Chunking
Para sistemas RAG, tu contenido se segmenta (divide en piezas de ~200-500 tokens). Cada segmento se recupera semi-independientemente.
Implicación: Cada segmento debe ser auto-contenido y optimizado. No dependas de referencias "más adelante en el artículo."
FAQ
Espera — me han dicho que el contenido largo posiciona mejor. ¿Eso está mal ahora?
Para SEO tradicional, el contenido largo a menudo funciona bien. Pero para visibilidad IA, el problema de pérdida media significa que más largo no es automáticamente mejor. La clave es la estructura: contenido largo con buena estructura (TL;DR, secciones claras, resumen de conclusión) puede funcionar. Contenido largo y divagante falla. Considera si una serie de piezas enfocadas podría superar a una mega-guía.
¿Esto afecta cómo escribo contenido FAQ?
Sí. Las secciones FAQ son geniales porque cada P&R es esencialmente un segmento auto-contenido. Coloca tus P&Rs más importantes al principio y al final de la sección FAQ. Las P&Rs del medio aún tienen riesgo relativo de pérdida media.
¿Debo literalmente repetir puntos clave al principio y al final?
Sí, con variación. La repetición literal puede verse incómoda para humanos. Pero la repetición reformulada (decir lo mismo de manera diferente) asegura que la IA encuentre la información en posiciones de alta atención mientras se mantiene natural para lectores humanos.
¿El chunking para RAG resuelve el problema de lost-in-the-middle?
Parcialmente. El chunking ayuda porque cada segmento se evalúa independientemente. Pero dentro del contexto ensamblado (cuando múltiples segmentos se combinan para responder una consulta), la pérdida media aún aplica. Optimiza en ambos niveles: segmentos individuales Y estructura general del documento.
¿Cómo interactúa esto con el Schema markup?
Schema es independiente de la posición — JSON-LD típicamente está al final del HTML pero se procesa por separado. Schema proporciona hechos estructurados que no sufren de sesgos de atención. Usa Schema para datos críticos (precios, funcionalidades, FAQs) como seguro contra la pérdida media basada en prosa.