Model Polling: How Synthetic Respondents Are Replacing Focus Groups
Last Updated: November 2, 2025
What if you could run a focus group with 10,000 participants—each representing a distinct demographic profile—and have results in hours instead of months? What if those participants never experienced fatigue, never tried to please the moderator, and always answered honestly about sensitive topics?
This isn't a thought experiment. It's happening now in enterprise research departments worldwide, and it's called Model Polling.
Table of Contents
- The Concept of Synthetic Respondents
- How LLMs Become Focus Group Participants
- The Multi-Model Advantage
- Real-Time Data Integration: The RAG Architecture
- Accuracy and Validation
- Technical Architecture for Enterprise
- FAQ
The Concept of Synthetic Respondents
Traditional market research operates on a fundamental assumption: to understand consumers, you must ask consumers. This assumption drove a multi-billion dollar industry of panels, surveys, and focus groups.
Model Polling challenges this paradigm with a revolutionary premise: Large Language Models trained on the entire public internet contain a compressed model of human society itself.
When an LLM like GPT-4 or Claude generates text, it draws on patterns learned from billions of human-written documents—forum discussions, product reviews, social media posts, academic papers. In a meaningful sense, these models have "read" more consumer opinions than any human researcher could absorb in a thousand lifetimes.
Synthetic Personas in Practice
Instead of recruiting 500 people and paying them to complete surveys, enterprise companies now create synthetic personas. Using specialized system prompts, a single model can simulate diverse demographic and psychographic profiles:
Prompt example:
"You are a 42-year-old suburban father of three, household income $120,000, concerned about vehicle safety and fuel efficiency. You drive a 2019 Honda Pilot and are considering your next purchase. Respond as this person would to the following question..."
The same model can immediately become:
"You are a 23-year-old urban professional, environmentally conscious, car-free by choice but considering first vehicle purchase for weekend trips..."
Within minutes, researchers can simulate thousands of these personas, each answering the same questions from their unique perspective.
How LLMs Become Focus Group Participants
The synthetic respondent approach offers fundamental advantages over traditional methods:
| Dimension | Traditional Focus Group | Synthetic Respondents |
|---|---|---|
| Time to insights | 6-10 weeks | Hours |
| Cost per respondent | $50-200 | <$0.10 |
| Sample size limits | Logistics-constrained | Unlimited |
| Observer effect | Present | Absent |
| Social desirability bias | Significant | Eliminated |
| Sensitive topic honesty | Variable | Consistent |
| Scalability | Linear cost | Near-zero marginal cost |
The Bias Elimination Factor
Human respondents bring unavoidable biases to research settings. They try to appear consistent. They want to please interviewers. They're influenced by what others in the room say. They modify answers on sensitive topics like finances, health, or controversial preferences.
Synthetic respondents have none of these constraints. A model simulating a conservative voter and a progressive voter will give genuinely different responses—not performative ones designed to signal group membership.
Satisfaction Rates
Research from enterprise adopters shows 87% satisfaction rates among teams using synthetic data, with many reporting high correlation between synthetic predictions and actual market behavior.
The Multi-Model Advantage
Early adopters quickly discovered that relying on a single LLM created blind spots. Each model has different training data, different biases, and different response patterns. The solution: multi-model polling.
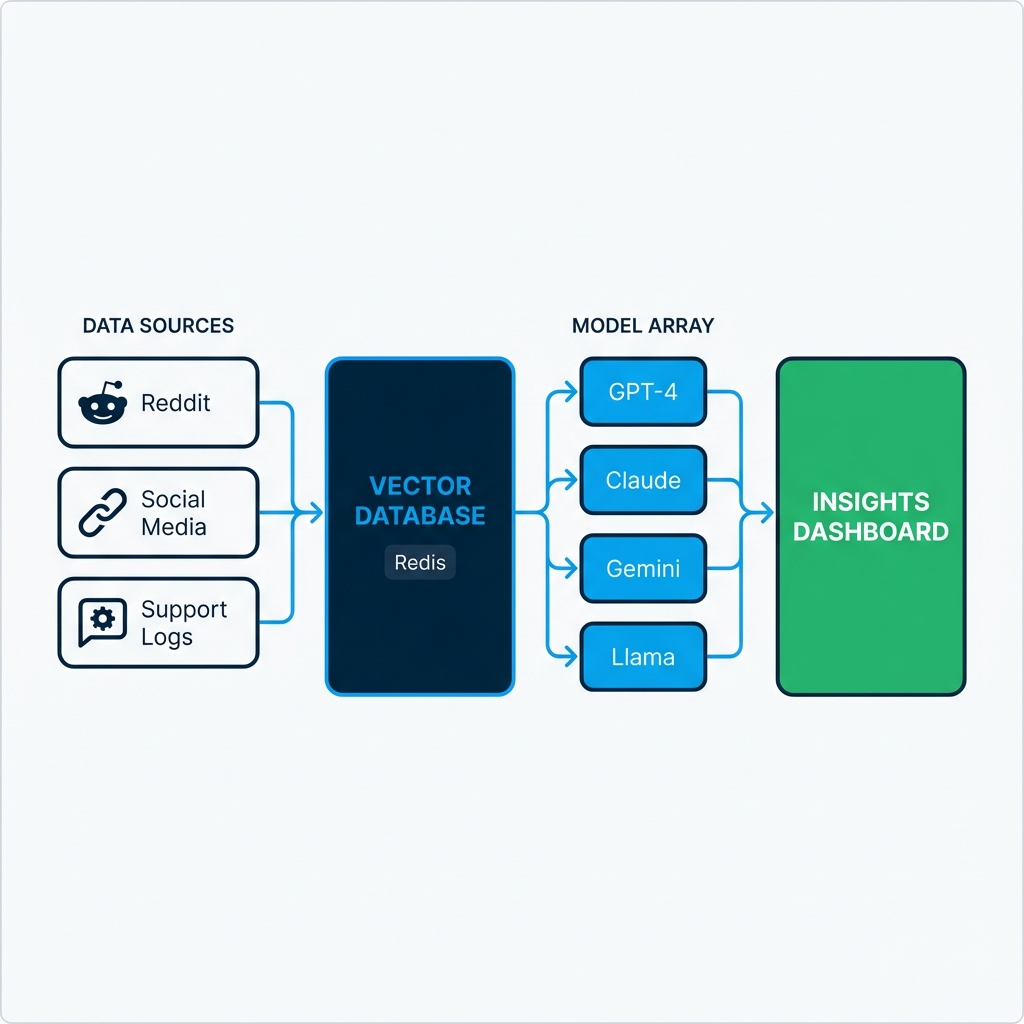
Instead of querying one model, sophisticated enterprise systems poll arrays of models simultaneously:
- GPT-4 and GPT-4o from OpenAI
- Claude 3.5 from Anthropic
- Gemini from Google
- Llama 3 and other open-source models
Response patterns are then analyzed for:
- Consensus: Where models agree, confidence increases
- Divergence: Disagreement signals areas requiring human investigation
- Model-specific biases: Known tendencies are factored out
This multi-model approach mirrors how enterprises monitor brand visibility across AI platforms—recognizing that different models may have radically different "perspectives" on the same topic.
Real-Time Data Integration: The RAG Architecture
The most powerful synthetic research systems don't rely solely on model training data. They integrate real-time information through Retrieval-Augmented Generation (RAG).
How RAG Transforms Model Polling
Traditional LLMs have a knowledge cutoff date—they can only know what existed in their training data. RAG overcomes this limitation:
- Live data ingestion: Systems continuously collect data from Reddit, Twitter/X, review sites, support logs, and news sources
- Vectorization: This data is converted to mathematical embeddings and stored in vector databases (often using Redis for speed)
- Contextual retrieval: When a synthetic persona is queried, relevant recent data is retrieved and injected into the prompt
- Grounded generation: The model generates responses informed by yesterday's forum posts, not two-year-old training data
Example: When asking "What do consumers think about [Brand X]'s new pricing?"—the model doesn't hallucinate from training data. It synthesizes actual social media discussions from the past 24 hours.
This architecture is closely related to how RAG optimizes content for AI discovery, but applied in reverse: instead of making content findable by AI, enterprises make AI findings actionable for humans.
Accuracy and Validation
The natural question: How accurate are synthetic respondents compared to real humans?
Validation Studies
Enterprise teams using synthetic research report strong performance across multiple dimensions:
| Metric | Typical Performance |
|---|---|
| Directional accuracy | 80-90% alignment with real survey results |
| Ranking accuracy | Synthetic respondents rank preferences similarly to humans |
| Trend detection | Earlier identification of emerging sentiment shifts |
| Outlier detection | Better identification of edge cases and niche segments |
Where Humans Still Win
Synthetic respondents excel at aggregating known patterns but may struggle with:
- Genuinely novel product categories with no historical discussion
- Deep emotional dynamics requiring empathy
- Cultural nuances specific to very narrow communities
The emerging best practice is hybrid validation: use synthetic respondents for speed and scale, validate critical decisions with targeted human research.
This mirrors the human-in-the-loop approach recommended for high-stakes AI applications.
Technical Architecture for Enterprise
Building enterprise-grade model polling infrastructure requires sophisticated engineering. The complexity often surprises organizations attempting to build in-house.
Core Components
1. Data Ingestion Layer
- API connections to social platforms, forums, review aggregators
- Real-time streaming vs. batch processing decisions
- Data cleaning and deduplication
2. Vector Database
- Storage for embeddings at scale
- Millisecond retrieval latency requirements
- Often Redis, Pinecone, or Weaviate
3. Model Orchestration Layer
- Unified API abstraction across providers
- Prompt management and versioning
- Rate limiting and cost controls
- Fallback routing when providers fail
4. Analytics and Monitoring
- Response quality scoring
- Hallucination detection
- Cross-model consistency analysis
- Executive dashboard and alerting
Integration Challenges
Different LLM providers (OpenAI, Anthropic, Google) have incompatible APIs, different rate limits, and varying response formats. Without a middleware abstraction layer, codebases become tangled with provider-specific adaptations.
Platforms like AICarma have invested years building these abstraction layers—enabling enterprises to start polling 10+ models immediately rather than spending months on integration engineering. The architectural patterns required mirror those needed for multi-model brand monitoring, making integrated solutions particularly valuable.
FAQ
Can synthetic respondents replace all human research?
Not entirely. They excel at speed, scale, and pattern aggregation. However, genuinely novel scenarios, deep emotional exploration, and culturally specific nuances still benefit from human involvement. The optimal approach is hybrid: synthetic for breadth and speed, human for depth and validation.
How do you prevent model "hallucinations" in research responses?
RAG architecture grounds responses in real data. Multi-model polling identifies outliers. Confidence scoring flags uncertain responses. Combined, these techniques reduce hallucination risk significantly—though monitoring remains essential.
What's the cost comparison with traditional research?
Synthetic research typically costs 10-25% of traditional methods. A study that might require $200,000 in panel fees, incentives, and agency costs can often be approximated for $20,000-50,000 in API costs and platform fees—with results in days rather than months.
Is the data as defensible for regulatory or board purposes?
This varies by context. Synthetic data is increasingly accepted for directional guidance and rapid iteration. For regulated industries or board-level decisions, hybrid approaches that include human validation provide the defensibility traditional methods offered.
What infrastructure is required to start?
Enterprises can build from scratch or buy platforms. Building requires ML engineering talent, multi-provider API management, vector database expertise, and ongoing maintenance. Platforms offer faster deployment but less customization. Most Fortune 500 companies are choosing platforms for speed-to-value.
Model polling represents a fundamental shift in how enterprises understand markets. The companies mastering this capability today are building competitive advantages that compound over time—seeing market shifts faster, testing hypotheses cheaper, and making decisions with confidence their slower competitors cannot match.