Context Window Optimization: Writing for the 'U-Shaped Attention Curve'
Last Updated: December 5, 2025
Here's a sentence that will make you rethink how you structure content: Large Language Models are bad at paying attention to the middle of long documents.
This isn't a minor quirk—it's a fundamental characteristic of how transformer-based AI works. Research has consistently shown that LLMs exhibit what's called the "U-shaped attention curve"—they pay the most attention to information at the beginning and end of their context window, while information in the middle gets partially ignored.
For content creators, marketers, and anyone trying to get their content cited by AI, this has profound implications. If your key facts are buried in paragraph 7 of a 15-paragraph article, AI might literally not "see" them, even if the crawler retrieved your page.
Understanding and optimizing for context window attention is one of the most overlooked aspects of Generative Engine Optimization. Let's fix that.
Table of Contents
- The "Lost in the Middle" Phenomenon
- How AI Attention Actually Works
- The U-Shaped Attention Curve
- Content Structure Implications
- The Inverted Pyramid: Your New Best Friend
- Practical Restructuring Techniques
- Testing Your Content for Middle-Loss Risk
- Context Window Size Considerations
- FAQ
The "Lost in the Middle" Phenomenon
The Research
A landmark 2023 paper from researchers at Stanford, Berkeley, and Samaya AI titled "Lost in the Middle" demonstrated a critical limitation of LLMs: when given long context windows, models struggle to use information from the middle of that context.
Key Findings:
- Performance drops significantly when relevant information is in the middle
- Even models with 4K, 16K, or 32K token windows exhibit this behavior
- The effect is pronounced even in well-trained, commercial-grade models
- Larger context windows don't solve the problem
What This Means for Content
When your page is retrieved by RAG (Retrieval-Augmented Generation), it becomes part of the AI's context window. If your key selling point is in the middle of your page, it may be "lost" to the model's attention.
| Position in Document | AI Attention | Citation Likelihood |
|---|---|---|
| First 10% | High | High |
| Middle 80% | Lower | Reduced |
| Last 10% | High | High |
Why This Happens
It's not a bug—it's how transformer attention mechanisms work. Training encourages models to rely on positional extremes. Information at the beginning sets context; information at the end provides conclusions. Middle content is often deemed "supporting material."
How AI Attention Actually Works
The Attention Mechanism
LLMs use "attention" to decide which tokens (words/pieces) in the input to focus on when generating output. For each output token, the model calculates attention scores across all input tokens.
In theory, attention allows focusing on any part of the input. In practice, attention patterns show strong biases toward:
- Recency (nearby tokens)
- Position (early and late tokens)
- Semantic relevance (matching tokens)
Position Embeddings
LLMs encode position information alongside content. They "know" that token #1 came before token #1000. But training data biases mean:
- Early tokens are often given more weight (they establish context)
- Late tokens are often given more weight (they provide conclusions)
- Middle tokens must be exceptionally relevant to overcome positional disadvantage
The Practical Effect
Imagine you're writing about a software product. Your page has:
- Paragraph 1: Company intro
- Paragraph 3-7: Feature descriptions
- Paragraph 8: Pricing
- Paragraph 10: Conclusion
If AI is answering "What does [Product] cost?", the pricing info in paragraph 8 (middle) may receive less attention than the intro or conclusion, even though it's the answer to the question.
The U-Shaped Attention Curve
Visualizing the Pattern
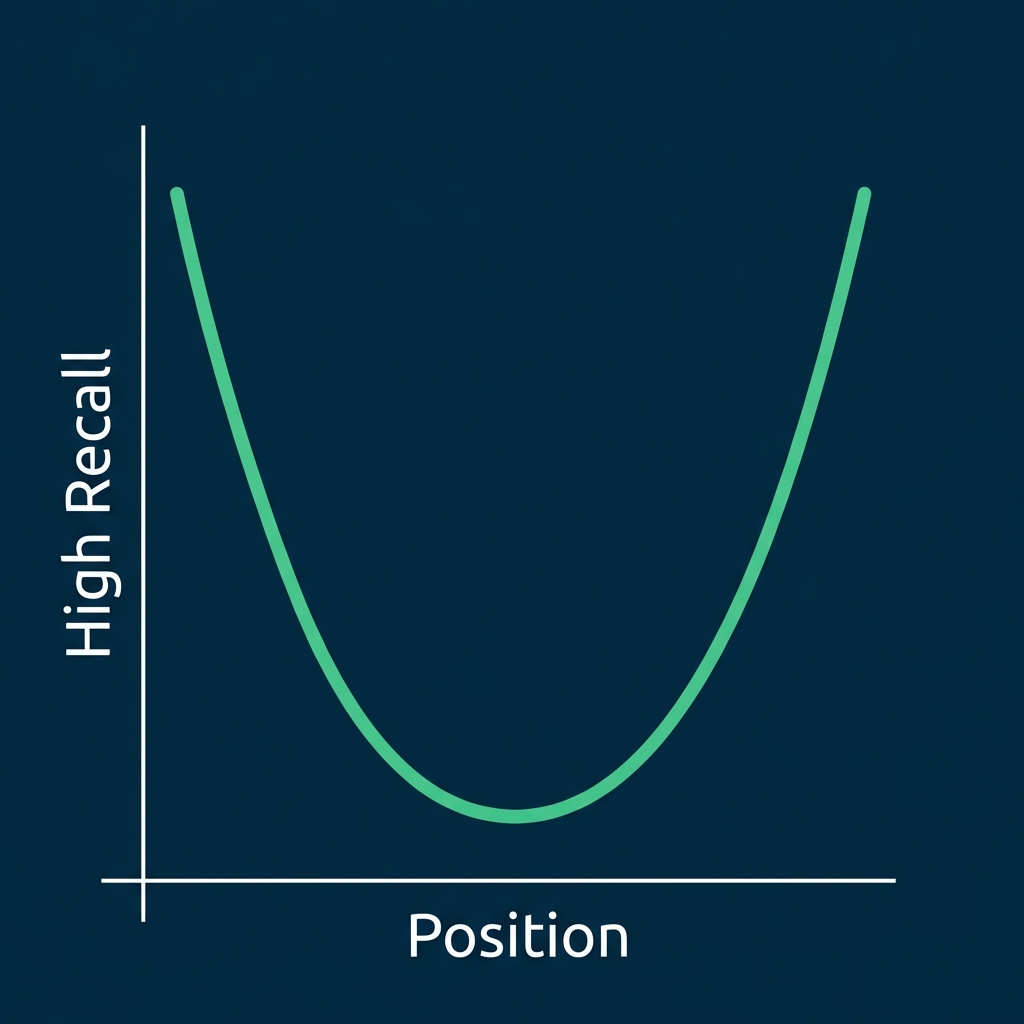
Measured Performance
From the "Lost in the Middle" paper, when relevant information was placed at different positions:
| Position | Model Accuracy |
|---|---|
| Position 1 (Start) | ~75% |
| Position 10 (Middle) | ~55% |
| Position 20 (End) | ~72% |
That's a 20+ percentage point drop in accuracy just from position!
Cross-Model Consistency
This pattern appears across models:
- GPT-4
- Claude
- Llama
- Mistral
- Gemini
Some models handle it better than others, but none are immune.
Content Structure Implications
The Key Insight
Put your most important information at the beginning and end.
This isn't just about AI—it's actually good writing practice. Journalism has used the "inverted pyramid" for a century for similar reasons (human readers also scan beginnings and skim middles).
What to Put Where
| Position | Content Type |
|---|---|
| Beginning (First 10-15%) | Key facts, definitions, main claims, TL;DR |
| Middle (60-80%) | Supporting evidence, examples, depth |
| End (Last 10-15%) | Summary, key takeaways, calls to action |
The Double-Exposure Strategy
Critical facts should appear twice: once at the beginning, once at the end (possibly rephrased). This ensures that regardless of attention patterns, the key information is exposed.
Example:
- Beginning: "AICarma monitors AI visibility across ChatGPT, Claude, and Gemini."
- Middle: [detailed explanations]
- End: "To track your brand's presence across all major AI platforms including ChatGPT, Claude, and Gemini, try AICarma."
The Inverted Pyramid: Your New Best Friend
What Is the Inverted Pyramid?
Journalism's "inverted pyramid" puts the most newsworthy information first, followed by supporting details, then background:

Applying It to AI Optimization
For every page/article:
- Headline: Contains key claim/keyword
- First paragraph: Answers the core question directly
- Second paragraph: Expands with specifics
- Following paragraphs: Evidence and examples
- Conclusion: Restates key points + CTA
Example Transformation
Before (Buried lede):
In today's fast-paced digital landscape, businesses are constantly
looking for ways to improve their online presence. Marketing has
evolved significantly over the past decade. [3 more paragraphs of
preamble]
Our pricing starts at $99/month for the Basic plan, $299 for Pro,
and $599 for Enterprise.
After (Inverted pyramid):
AICarma pricing: Basic $99/month, Pro $299/month, Enterprise $599/month.
All plans include AI visibility monitoring across ChatGPT, Claude,
and Gemini.
[Then explain features, then background]
Practical Restructuring Techniques
Technique 1: The TL;DR Opening
Start every major piece with a TL;DR summary:
## TL;DR
- AI visibility measures how often your brand appears in AI responses
- Your current visibility probably ranges from 5-30% (most brands)
- Improving requires technical + content + entity optimization
- Expected timeline: 3-6 months for meaningful improvement
This ensures critical information is at the absolute top.
Technique 2: Definition First
For concept-explaining content, lead with the definition:
Instead of: "Over the past few years, the way we think about search has evolved..."
Do this: "Generative Engine Optimization (GEO) is the practice of optimizing content to appear in AI-generated responses from LLMs like ChatGPT."
Technique 3: Summary Tables at Top
Put your comparison/data tables early, not late:
Feature Comparison
| Feature | Us | Competitor A | Competitor B |
|---|---|---|---|
| Price | $99 | $149 | $199 |
| AI Models Tracked | 12 | 4 | 6 |
Technique 4: Key Points Reiteration
Echo important points in the conclusion:
## Conclusion
To recap the key points:
- [Critical point 1 restated]
- [Critical point 2 restated]
- [Critical point 3 restated]
[Call to action]
Technique 5: Section-Level Optimization
Apply the principle to each section, not just the whole document:
## Why Pricing Matters for AI Visibility
**Key insight**: Transparent pricing significantly improves AI recommendation rates.
[Supporting explanation]
When pricing is public, AI can confidently include you in comparisons.
Each section's first sentence = key claim.
Testing Your Content for Middle-Loss Risk
Manual Testing Method
- Copy your full content into ChatGPT/Claude
- Ask a specific question whose answer is in the middle
- See if the AI correctly retrieves it
- Compare to questions whose answers are at the beginning/end
Example test prompts:
- "Based on this content, what is the price of [Product]?" (if pricing is in middle)
- "According to this article, when was the company founded?"
- "What does this author say about [topic buried in paragraph 6]?"
Restructuring Based on Results
If AI fails to find middle-located information:
- Move that information earlier
- Reiterate it in the conclusion
- Add highlighting (bold, headers) to increase salience
Automated Analysis
Consider:
- Sentence position analysis (where are your key claims?)
- Keyword positioning (are target keywords in first/last 15%?)
- Information density mapping (is your "meat" in the middle?)
Context Window Size Considerations
Context Window Basics
| Model | Context Window |
|---|---|
| GPT-4 | 8K - 128K tokens |
| Claude | 100K - 200K tokens |
| Gemini | 32K - 1M tokens |
| Llama 3 | 8K - 128K tokens |
Larger windows = can hold more content. But "lost in the middle" persists even in large windows.
What This Means for Content Length
Short content (Under 1000 tokens / ~750 words): Less middle-loss risk; most content is "edge" content.
Medium content (1000-3000 tokens): Moderate risk; apply restructuring techniques.
Long content (3000+ tokens): High middle-loss risk; aggressive restructuring needed or consider splitting into multiple pages.
The Chunking Reality
For RAG systems, your content is chunked (split into ~200-500 token pieces). Each chunk is retrieved semi-independently.
Implication: Each chunk should be self-contained and optimized. Don't rely on "later in the article" references.
When to Split Content
If your article is 5000+ words, consider:
- Splitting into a series of focused articles
- Creating a hub-and-spoke structure
- Ensuring each segment stands alone
Shorter, focused content often performs better than comprehensive mega-guides for AI retrieval.
FAQ
Wait—I've been told long-form content ranks better. Is that wrong now?
For traditional SEO, longer content often does perform well. But for AI visibility, the middle-loss problem means that longer content may not be better for AI citation. The key is structure: long content with good structure (TL;DR, clear sections, conclusion summary) can work. Long rambling content fails. Consider whether a series of focused pieces might outperform one mega-guide.
Does this affect how I write FAQ content?
Yes. FAQ sections are great because each Q&A is essentially a self-contained chunk. Place your most important Q&As at the beginning and end of the FAQ section. The middle Q&As still have middle-loss risk relative to each other.
Should I literally repeat key points at the beginning and end?
Yes, with variation. Verbatim repetition may look awkward to humans. But rephrased repetition (saying the same thing differently) ensures AI encounters the information in high-attention positions while remaining natural for human readers.
Does chunking for RAG solve the lost-in-the-middle problem?
Partially. Chunking helps because each chunk is independently evaluated. But within the assembled context (when multiple chunks are combined to answer a query), middle-loss still applies to the assembled context. Optimize at both levels: individual chunks AND overall document structure.
How does this interact with Schema markup?
Schema is position-independent—JSON-LD is typically at the end of HTML but processed separately. Schema provides structured facts that don't suffer from attention biases. Use Schema for critical facts (pricing, features, FAQs) as insurance against prose-based middle-loss.