Kontextfenster-Optimierung: Schreiben für die 'U-förmige Aufmerksamkeitskurve'
Letzte Aktualisierung: 5. December 2025
Hier ist ein Satz, der Sie dazu bringen wird, Ihre Content-Struktur zu überdenken: Large Language Models sind schlecht darin, der Mitte langer Dokumente Aufmerksamkeit zu schenken.
Das ist keine kleine Eigenart — es ist eine fundamentale Eigenschaft der transformer-basierten KI. Forschung hat konsistent gezeigt, dass LLMs die sogenannte „U-förmige Aufmerksamkeitskurve" aufweisen — sie schenken Informationen am Anfang und Ende ihres Kontextfensters die meiste Aufmerksamkeit, während Informationen in der Mitte teilweise ignoriert werden.
Für Content-Ersteller, Marketer und alle, die ihren Content von KI zitiert haben möchten, hat das tiefgreifende Implikationen. Wenn Ihre Schlüsselfakten in Absatz 7 eines 15-Absatz-Artikels vergraben sind, „sieht" die KI sie möglicherweise buchstäblich nicht, selbst wenn der Crawler Ihre Seite abgerufen hat.
Das Verstehen und Optimieren für die Aufmerksamkeit des Kontextfensters ist einer der am meisten übersehenen Aspekte der Generative Engine Optimization. Ändern wir das.
Inhaltsverzeichnis
- Das „Lost in the Middle"-Phänomen
- Wie KI-Aufmerksamkeit tatsächlich funktioniert
- Die U-förmige Aufmerksamkeitskurve
- Implikationen für die Content-Struktur
- Die umgekehrte Pyramide: Ihr neuer bester Freund
- Praktische Restrukturierungstechniken
- Content auf Middle-Loss-Risiko testen
- Überlegungen zur Kontextfenstergröße
- FAQ
Das „Lost in the Middle"-Phänomen
Die Forschung
Ein wegweisendes Paper von 2023 von Forschern der Stanford University, Berkeley und Samaya AI mit dem Titel „Lost in the Middle" demonstrierte eine kritische Einschränkung von LLMs: Bei langen Kontextfenstern haben Modelle Schwierigkeiten, Informationen aus der Mitte dieses Kontexts zu nutzen.
Wichtigste Erkenntnisse:
- Die Leistung sinkt signifikant, wenn relevante Informationen in der Mitte stehen
- Selbst Modelle mit 4K-, 16K- oder 32K-Token-Fenstern zeigen dieses Verhalten
- Der Effekt ist selbst bei gut trainierten kommerziellen Modellen ausgeprägt
- Größere Kontextfenster lösen das Problem nicht
Was das für Content bedeutet
Wenn Ihre Seite durch RAG (Retrieval-Augmented Generation) abgerufen wird, wird sie Teil des KI-Kontextfensters. Wenn Ihr Alleinstellungsmerkmal in der Mitte Ihrer Seite steht, könnte es für die Aufmerksamkeit des Modells „verloren" gehen.
| Position im Dokument | KI-Aufmerksamkeit | Zitierungswahrscheinlichkeit |
|---|---|---|
| Erste 10% | Hoch | Hoch |
| Mittlere 80% | Niedriger | Reduziert |
| Letzte 10% | Hoch | Hoch |
Warum das passiert
Es ist kein Bug — so funktionieren Transformer-Aufmerksamkeitsmechanismen. Das Training ermutigt Modelle, sich auf positionelle Extreme zu stützen. Informationen am Anfang setzen den Kontext; Informationen am Ende liefern Schlussfolgerungen. Mittlerer Content wird oft als „unterstützendes Material" eingestuft.
Wie KI-Aufmerksamkeit tatsächlich funktioniert
Der Aufmerksamkeitsmechanismus
LLMs nutzen „Aufmerksamkeit", um zu entscheiden, auf welche Tokens (Wörter/Teile) im Input sie sich bei der Generierung des Outputs konzentrieren. Für jedes Output-Token berechnet das Modell Aufmerksamkeits-Scores über alle Input-Tokens.
Theoretisch ermöglicht Aufmerksamkeit die Fokussierung auf jeden Teil des Inputs. In der Praxis zeigen Aufmerksamkeitsmuster starke Verzerrungen zugunsten von:
- Aktualität (nahegelegene Tokens)
- Position (frühe und späte Tokens)
- Semantische Relevanz (übereinstimmende Tokens)
Positions-Embeddings
LLMs kodieren Positionsinformationen zusammen mit dem Inhalt. Sie „wissen", dass Token #1 vor Token #1000 kam. Aber Verzerrungen in den Trainingsdaten bedeuten:
- Frühe Tokens erhalten oft mehr Gewicht (sie etablieren den Kontext)
- Späte Tokens erhalten oft mehr Gewicht (sie liefern Schlussfolgerungen)
- Mittlere Tokens müssen außergewöhnlich relevant sein, um den positionellen Nachteil zu überwinden
Der praktische Effekt
Stellen Sie sich vor, Sie schreiben über ein Softwareprodukt. Ihre Seite hat:
- Absatz 1: Unternehmensvorstellung
- Absatz 3-7: Feature-Beschreibungen
- Absatz 8: Preise
- Absatz 10: Fazit
Wenn KI die Frage „Was kostet [Produkt]?" beantwortet, könnte die Preisinformation in Absatz 8 (Mitte) weniger Aufmerksamkeit erhalten als die Einleitung oder das Fazit, obwohl sie die Antwort auf die Frage ist.
Die U-förmige Aufmerksamkeitskurve
Das Muster visualisieren
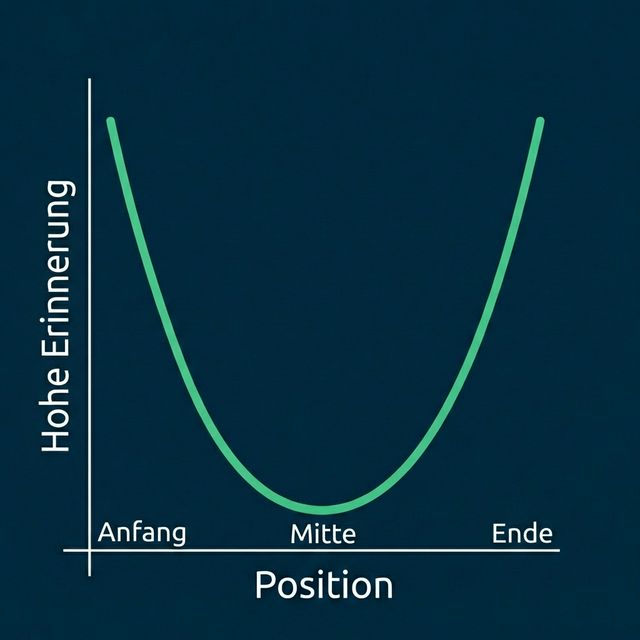
Die U-förmige Kurve zeigt deutlich: Das KI-Modell achtet am stärksten auf den Anfang und das Ende eines Inhalts, während die Mitte relativ vernachlässigt wird.
Gemessene Leistung
Aus dem „Lost in the Middle"-Paper, wenn relevante Informationen an verschiedenen Positionen platziert wurden:
| Position | Modellgenauigkeit |
|---|---|
| Position 1 (Anfang) | ~75% |
| Position 10 (Mitte) | ~55% |
| Position 20 (Ende) | ~72% |
Das ist ein Rückgang der Genauigkeit um über 20 Prozentpunkte — allein durch die Position!
Modellübergreifende Konsistenz
Dieses Muster tritt modelübergreifend auf:
- GPT-4
- Claude
- Llama
- Mistral
- Gemini
Einige Modelle gehen besser damit um als andere, aber keines ist immun.
Implikationen für die Content-Struktur
Die Kernerkenntnis
Setzen Sie Ihre wichtigsten Informationen an den Anfang und das Ende.
Das ist nicht nur für KI relevant — es ist tatsächlich gute Schreibpraxis. Der Journalismus nutzt die „umgekehrte Pyramide" seit einem Jahrhundert aus ähnlichen Gründen (menschliche Leser überfliegen auch Anfänge und überspringen die Mitte).
Was wo platzieren
| Position | Content-Typ |
|---|---|
| Anfang (Erste 10-15%) | Schlüsselfakten, Definitionen, Hauptaussagen, TL;DR |
| Mitte (60-80%) | Belege, Beispiele, Vertiefung |
| Ende (Letzte 10-15%) | Zusammenfassung, zentrale Erkenntnisse, Handlungsaufforderungen |
Die Doppelbelichtungs-Strategie
Kritische Fakten sollten zweimal erscheinen: einmal am Anfang, einmal am Ende (möglicherweise umformuliert). So wird sichergestellt, dass die Schlüsselinformationen unabhängig von Aufmerksamkeitsmustern erfasst werden.
Beispiel:
- Anfang: „AICarma überwacht KI-Sichtbarkeit über ChatGPT, Claude und Gemini."
- Mitte: [detaillierte Erklärungen]
- Ende: „Um die Präsenz Ihrer Marke über alle großen KI-Plattformen einschließlich ChatGPT, Claude und Gemini zu verfolgen, testen Sie AICarma."
Die umgekehrte Pyramide: Ihr neuer bester Freund
Was ist die umgekehrte Pyramide?

Die journalistische „umgekehrte Pyramide" setzt die nachrichtenwürdigsten Informationen zuerst, gefolgt von unterstützenden Details, dann Hintergrund.
Anwendung auf KI-Optimierung
Für jede Seite/jeden Artikel:
- Überschrift: Enthält Kernaussage/Keyword
- Erster Absatz: Beantwortet die Kernfrage direkt
- Zweiter Absatz: Erweitert mit Spezifika
- Folgende Absätze: Belege und Beispiele
- Fazit: Wiederholt Kernpunkte + CTA
Beispiel-Transformation
Vorher (Vergrabene Kernaussage):
In der heutigen schnelllebigen digitalen Landschaft suchen Unternehmen
ständig nach Wegen, ihre Online-Präsenz zu verbessern. Marketing hat
sich im letzten Jahrzehnt erheblich weiterentwickelt. [3 weitere
Absätze Vorgeplänkel]
Unsere Preise beginnen bei 99€/Monat für den Basic-Plan, 299€ für Pro
und 599€ für Enterprise.
Nachher (Umgekehrte Pyramide):
AICarma Preise: Basic 99€/Monat, Pro 299€/Monat, Enterprise 599€/Monat.
Alle Pläne beinhalten KI-Sichtbarkeitsmonitoring über ChatGPT, Claude
und Gemini.
[Dann Features erklären, dann Hintergrund]
Praktische Restrukturierungstechniken
Technik 1: Die TL;DR-Eröffnung
Starten Sie jedes wichtige Stück mit einer TL;DR-Zusammenfassung:
## TL;DR
- KI-Sichtbarkeit misst, wie oft Ihre Marke in KI-Antworten erscheint
- Ihre aktuelle Sichtbarkeit liegt wahrscheinlich bei 5-30% (die meisten Marken)
- Verbesserung erfordert technische + Content- + Entity-Optimierung
- Erwarteter Zeitrahmen: 3-6 Monate für bedeutende Verbesserung
Dies stellt sicher, dass kritische Informationen ganz oben stehen.
Technik 2: Definition zuerst
Für konzepterklärende Inhalte mit der Definition führen:
Statt: „In den letzten Jahren hat sich die Art, wie wir über Suche denken, weiterentwickelt..."
So machen: „Generative Engine Optimization (GEO) ist die Praxis der Content-Optimierung für die Erscheinung in KI-generierten Antworten von LLMs wie ChatGPT."
Technik 3: Zusammenfassungstabellen am Anfang
Vergleichs-/Datentabellen früh platzieren, nicht spät:
Feature-Vergleich
| Feature | Wir | Wettbewerber A | Wettbewerber B |
|---|---|---|---|
| Preis | 99€ | 149€ | 199€ |
| Überwachte KI-Modelle | 12 | 4 | 6 |
Technik 4: Wiederholung der Kernpunkte
Wichtige Punkte im Fazit wiedergeben:
## Fazit
Zusammenfassung der Kernpunkte:
- [Kritischer Punkt 1 wiederholt]
- [Kritischer Punkt 2 wiederholt]
- [Kritischer Punkt 3 wiederholt]
[Handlungsaufforderung]
Technik 5: Optimierung auf Abschnittsebene
Das Prinzip auf jeden Abschnitt anwenden, nicht nur auf das gesamte Dokument:
## Warum Preistransparenz für KI-Sichtbarkeit wichtig ist
**Kernerkenntnis**: Transparente Preise verbessern die
KI-Empfehlungsrate signifikant.
[Unterstützende Erklärung]
Wenn Preise öffentlich sind, kann KI Sie souverän in Vergleiche
einbeziehen.
Der erste Satz jedes Abschnitts = Kernaussage.
Content auf Middle-Loss-Risiko testen
Manuelle Testmethode
- Ihren vollständigen Content in ChatGPT/Claude kopieren
- Eine spezifische Frage stellen, deren Antwort in der Mitte steht
- Prüfen, ob die KI sie korrekt abruft
- Mit Fragen vergleichen, deren Antworten am Anfang/Ende stehen
Beispiel-Testprompts:
- „Was kostet [Produkt] laut diesem Content?" (wenn Preise in der Mitte)
- „Wann wurde das Unternehmen laut diesem Artikel gegründet?"
- „Was sagt dieser Autor über [in Absatz 6 vergrabenes Thema]?"
Restrukturierung basierend auf Ergebnissen
Wenn KI mittig platzierte Informationen nicht findet:
- Diese Informationen weiter nach vorne verschieben
- Sie im Fazit wiederholen
- Hervorhebungen (fett, Überschriften) hinzufügen, um Salienz zu erhöhen
Automatisierte Analyse
Erwägen Sie:
- Satzpositionsanalyse (wo stehen Ihre Kernaussagen?)
- Keyword-Positionierung (sind Ziel-Keywords in den ersten/letzten 15%?)
- Informationsdichte-Mapping (steckt Ihr „Fleisch" in der Mitte?)
Überlegungen zur Kontextfenstergröße
Kontextfenster-Grundlagen
| Modell | Kontextfenster |
|---|---|
| GPT-4 | 8K - 128K Tokens |
| Claude | 100K - 200K Tokens |
| Gemini | 32K - 1M Tokens |
| Llama 3 | 8K - 128K Tokens |
Größere Fenster = mehr Content aufnehmbar. Aber „Lost in the Middle" besteht auch bei großen Fenstern fort.
Was das für die Content-Länge bedeutet
Kurzer Content (Unter 1000 Tokens / ~750 Wörter): Weniger Middle-Loss-Risiko; der meiste Content ist „Rand"-Content.
Mittlerer Content (1000-3000 Tokens): Moderates Risiko; Restrukturierungstechniken anwenden.
Langer Content (3000+ Tokens): Hohes Middle-Loss-Risiko; aggressive Restrukturierung nötig oder Aufteilung in mehrere Seiten erwägen.
Die Chunking-Realität
Für RAG-Systeme wird Ihr Content in Chunks aufgeteilt (~200-500 Token-Stücke). Jeder Chunk wird semi-unabhängig abgerufen.
Implikation: Jeder Chunk sollte eigenständig und optimiert sein. Verlassen Sie sich nicht auf „später im Artikel"-Verweise.
Wann Content aufteilen
Wenn Ihr Artikel über 5000 Wörter hat, erwägen Sie:
- Aufteilung in eine Reihe fokussierter Artikel
- Erstellen einer Hub-and-Spoke-Struktur
- Sicherstellen, dass jedes Segment für sich steht
Kürzerer, fokussierter Content performt oft besser als umfassende Mega-Guides für KI-Retrieval.
FAQ
Moment — mir wurde gesagt, Long-Form-Content rankt besser. Stimmt das nicht mehr?
Für traditionelles SEO performt längerer Content oft gut. Aber für KI-Sichtbarkeit bedeutet das Middle-Loss-Problem, dass längerer Content nicht automatisch besser für KI-Zitierungen ist. Der Schlüssel ist Struktur: Langer Content mit guter Struktur (TL;DR, klare Abschnitte, Fazit-Zusammenfassung) kann funktionieren. Langer, unstrukturierter Content scheitert. Überlegen Sie, ob eine Reihe fokussierter Beiträge einen Mega-Guide übertreffen könnte.
Beeinflusst das, wie ich FAQ-Content schreibe?
Ja. FAQ-Abschnitte sind großartig, weil jedes Q&A ein eigenständiger Chunk ist. Platzieren Sie Ihre wichtigsten Q&As am Anfang und Ende des FAQ-Abschnitts. Die mittleren Q&As haben immer noch relatives Middle-Loss-Risiko.
Sollte ich Schlüsselpunkte buchstäblich am Anfang und Ende wiederholen?
Ja, mit Variation. Wörtliche Wiederholung kann für Menschen unnatürlich wirken. Aber umformulierte Wiederholung (dasselbe anders sagen) stellt sicher, dass KI die Informationen in Hochaufmerksamkeitspositionen antrifft, während es für menschliche Leser natürlich bleibt.
Löst Chunking für RAG das Lost-in-the-Middle-Problem?
Teilweise. Chunking hilft, weil jeder Chunk unabhängig bewertet wird. Aber innerhalb des zusammengesetzten Kontexts (wenn mehrere Chunks zur Beantwortung einer Anfrage kombiniert werden) gilt Middle-Loss weiterhin für den zusammengesetzten Kontext. Optimieren Sie auf beiden Ebenen: einzelne Chunks UND Gesamtdokumentstruktur.
Wie interagiert das mit Schema-Markup?
Schema ist positionsunabhängig — JSON-LD steht typischerweise am Ende des HTML, wird aber separat verarbeitet. Schema liefert strukturierte Fakten, die nicht unter Aufmerksamkeitsverzerrungen leiden. Nutzen Sie Schema für kritische Fakten (Preise, Features, FAQs) als Versicherung gegen prosabasiertes Middle-Loss.