Entity-SEO: So bauen Sie die Präsenz Ihrer Marke im Knowledge Graph auf
Letzte Aktualisierung: 12. March 2025
Kurzes Experiment: Gehen Sie zu ChatGPT und bitten Sie es, Ihr Unternehmen zu beschreiben.
Wenn Sie wie die meisten Unternehmen sind, ist eines von drei Dingen passiert:
- Die KI hat Sie korrekt beschrieben (Glückwunsch — Sie haben eine starke Entity-Präsenz)
- Die KI hat Sie vage oder teilweise falsch beschrieben (Sie brauchen Entity-Arbeit)
- Die KI sagte, sie habe keine Informationen über Sie (Ihre Entität existiert kaum)
Hier die unbequeme Wahrheit: Für eine KI sind Sie keine Website. Sie sind eine Entität. Und wenn Ihre Entität schwach, verwirrt oder nicht existent ist, wird keine Keyword-Optimierung der Welt Sie retten.
2012 kündigte Google den Knowledge Graph mit dem berühmten Satz „Dinge, nicht Zeichenketten" an. Ein Jahrzehnt später haben Large Language Models dieses Konzept zu seinem logischen Schluss geführt. ChatGPT, Claude und Gemini matchen nicht einfach Ihre Keywords — sie bilden mentale Modelle von Entitäten und deren Beziehungen.
„Apple" ist für diese Systeme nicht nur ein 5-Buchstaben-Wort. Es ist ein Unternehmen (Entity-Typ) mit Attributen (Gründer: Steve Jobs, Produkte: iPhone, Mac) und Beziehungen (Wettbewerber: Samsung, Mutterunternehmen von: Beats).
Wenn Sie möchten, dass KI Ihre Marke korrekt versteht, Sie souverän empfiehlt und nie falsche Fakten über Sie halluziniert, müssen Sie Entity-SEO meistern.
Inhaltsverzeichnis
- Keywords vs. Entitäten: Die fundamentale Verschiebung
- Wie KI Entitäten versteht
- Die Anatomie einer starken Entität
- Ihre Entität aufbauen: Ein strategisches Framework
- Die „sameAs"-Strategie: Ihre digitale Identität verbinden
- N-A-P-Konsistenz: Das Fundament
- Knowledge-Graph-Präsenz: Der heilige Gral
- Entity-Stärke messen
- Entity-Kontamination beheben
- FAQ
Keywords vs. Entitäten: Die fundamentale Verschiebung
Die Keyword-Ära (im Sterben)
Im traditionellen SEO war das Spiel Keyword-Matching:
- Nutzer sucht „bestes CRM-Tool"
- Sie optimieren die Seite für „bestes CRM-Tool"
- Google matcht die Zeichenketten
- Sie ranken
Das zählt für die traditionelle Suche immer noch, aber es reicht zunehmend nicht mehr aus.
Die Entity-Ära (im Aufstieg)
In modernen KI-Systemen ist das Spiel Entity-Verständnis:
- Nutzer fragt: „Welches CRM wäre am besten für ein 50-köpfiges Vertriebsteam?"
- KI ruft Informationen über CRM-Entitäten ab (Salesforce, HubSpot, Pipedrive)
- KI bewertet Attribute und Beziehungen jeder Entität
- KI empfiehlt basierend auf Entity-Verständnis, nicht auf Keyword-Matching
| Keyword-SEO | Entity-SEO |
|---|---|
| Für Zeichenketten optimieren | Für Konzepte optimieren |
| Spezifische Anfragen anvisieren | Umfassendes Verständnis aufbauen |
| Seitenfokussiert | Entity-fokussiert |
| Gemessen an Rankings | Gemessen an KI-Sichtbarkeit |
| Backlinks als Autorität | Knowledge Graph als Autorität |
Warum das wichtig ist
Keyword-Optimierung: „Wir ranken auf Platz 1 für ‚Projektmanagement-Software'" Entity-Optimierung: „KI versteht, dass wir die Projektmanagement-Lösung sind, die am besten für Kreativagenturen geeignet ist — wegen unserer Figma-Integration, visuellen Workflows und designfokussierten Oberfläche"
Der zweite Ansatz gewinnt in der KI-Ära, weil er abbildet, wie Nutzer tatsächlich Fragen stellen.
Wie KI Entitäten versteht
Large Language Models bauen Entity-Verständnis durch drei Mechanismen auf:
1. Trainingsdaten-Assoziationen
Während des Trainings absorbieren LLMs Millionen von Erwähnungen von Entitäten im Web. Sie lernen Assoziationen:
"Salesforce" erscheint häufig mit:
- "CRM", "Vertriebsautomatisierung", "Enterprise"
- "Marc Benioff" (Gründer)
- "Dreamforce" (Konferenz)
- "Einstein AI", "Data Cloud" (Produkte)
Diese Assoziationen bilden das initiale Verständnis der KI für die Salesforce-Entität.
2. Knowledge-Graph-Integration
Einige KI-Systeme (besonders Googles) sind mit strukturierten Wissensdatenbanken wie Wikidata verbunden. Diese liefern:
- Kanonische Entity-Identifikatoren
- Verifizierte Attribute (Gründungsdatum, Hauptsitz)
- Explizite Beziehungen (Gründer, besitzt, Wettbewerber von)
3. Schema-Markup-Parsing
Wenn KI Ihre Website crawlt, liefert Schema.org-Markup explizite Entity-Definitionen:
{
"@type": "Organization",
"name": "AICarma",
"foundingDate": "2023",
"founder": {"@type": "Person", "name": "..."},
"sameAs": ["https://linkedin.com/company/aicarma"]
}
Diese strukturierten Daten werden mit höherer Konfidenz behandelt als aus unstrukturiertem Text abgeleitete Daten.
Die Anatomie einer starken Entität
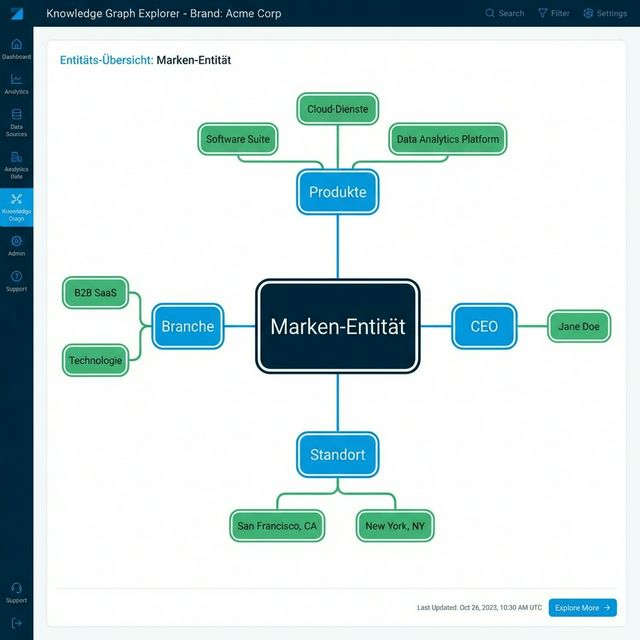
Was unterscheidet eine starke Entität (Apple, Nike, Salesforce) von einer schwachen (die meisten B2B-Startups)? Mehrere Schlüsselfaktoren:
Kern-Entity-Attribute
| Attribut | Beispiel | Wie etablieren |
|---|---|---|
| Kanonischer Name | „Salesforce" nicht „SFDC" | Konsistente Benennung überall |
| Entity-Typ | Organization: Software-Unternehmen | Schema Organization + Branche |
| Definierende Beschreibung | „Cloud-basierte CRM-Plattform" | Konsistent über alle Quellen wiederholt |
| Gründungsinformationen | 1999, San Francisco | Wikipedia, Crunchbase, Schema |
| Schlüsselpersonen | Marc Benioff (CEO/Gründer) | Person-Schema, LinkedIn, Nachrichten |
| Produkte/Dienste | Sales Cloud, Service Cloud | Product-Schema, Dokumentation |
Entity-Beziehungen
Starke Entitäten haben klare Beziehungen zu anderen Entitäten:
HubSpot
├── Gründer: Brian Halligan
├── Wettbewerber: Salesforce, Zoho
├── Kategorie: CRM, Marketing-Automatisierung
├── Integration: Gmail, Slack, Shopify
└── Kunde: Dropbox, Casper, Trello
Diese Beziehungen helfen KI, den Kontext zu verstehen — wann Sie empfohlen werden sollten versus Alternativen.
Entity-Konfidenz
KI-Systeme haben unterschiedliche Konfidenzniveaus in ihrem Entity-Wissen. Hochkonfidenz-Entitäten:
- Erscheinen in autoritativen Quellen (Wikipedia, große Medien)
- Haben konsistente Informationen über Quellen hinweg
- Sind in Knowledge Graphs verifiziert
- Haben umfangreiche strukturierte Daten auf eigenen Websites
Niedrigkonfidenz-Entitäten bekommen vorsichtige Formulierungen: „Laut ihrer Website..." vs. „HubSpot ist..."
Ihre Entität aufbauen: Ein strategisches Framework
Phase 1: Fundament (Kernidentität)
Ziel: Ihre kanonische Entity-Definition etablieren
-
Kernbeschreibung definieren (1-2 Sätze, die überall erscheinen sollten):
- Was Sie sind (Entity-Typ)
- Was Sie tun (primäres Angebot)
- Wen Sie bedienen (Zielgruppe)
Beispiel: „AICarma ist eine KI-Sichtbarkeitsmonitoring-Plattform, die B2B-Unternehmen hilft, ihre Präsenz in ChatGPT, Claude und Gemini zu verfolgen und zu optimieren."
-
Namen standardisieren: Eine kanonische Version wählen und überall verwenden. Nicht „AICarma GmbH" an manchen Stellen und „AI Carma" an anderen.
-
Gründungsfakten etablieren: Gründungsjahr, Standort, Gründer. Diese in strukturierte Daten und Profile einfließen lassen.
Phase 2: Präsenz (Verifikationsquellen)
Ziel: Präsenz in autoritativen Quellen schaffen
| Quelle | Priorität | Warum es wichtig ist |
|---|---|---|
| Crunchbase | Kritisch | Stark gewichtet in Trainingsdaten |
| LinkedIn-Unternehmensseite | Kritisch | Kreuzreferenziert Identität |
| Google-Unternehmensprofil | Hoch | Betreibt Knowledge Panel |
| Wikipedia | Hoch (wenn berechtigt) | Höchste Autoritätsquelle |
| Wikidata | Hoch | Strukturierter Knowledge Graph |
| Branchenverzeichnisse | Mittel | G2, Capterra, branchenspezifisch |
| Nachrichtenberichterstattung | Mittel | Kontextuelle Erwähnungen |
Phase 3: Verbindungen (Beziehungsmapping)
Ziel: Beziehungen etablieren, um Kontextverständnis zu stärken
Schema sameAs nutzen, um Ihre Website mit allen verifizierten Profilen zu verbinden:
"sameAs": [
"https://www.linkedin.com/company/ihrunternehmen",
"https://www.crunchbase.com/organization/ihrunternehmen",
"https://twitter.com/ihrunternehmen",
"https://g2.com/products/ihrunternehmen"
]
Explizite Erwähnungen von Beziehungen erstellen:
- Gründer/Teammitglieder (Person-Entitäten)
- Partnerschaften (Organization-Entitäten)
- Integrationspartner (deren Entitäten erwähnen)
- Branchenkategorien (CategoryCode)
Phase 4: Verstärkung (fortlaufend)
Ziel: Entity-Signale kontinuierlich stärken
- Sicherstellen, dass alle neuen Inhalte Ihren kanonischen Entity-Namen referenzieren
- Alle Profile mit konsistenten Informationen aktuell halten
- Laufend autoritative Erwähnungen generieren (Presse, Podcasts, Gastbeiträge)
- Entity-Kontamination überwachen und korrigieren
Die „sameAs"-Strategie: Ihre digitale Identität verbinden
Die sameAs-Eigenschaft in Schema.org ist vielleicht das am meisten unterschätzte Power-Tool im Entity-SEO. Sie sagt der KI explizit: „Diese verschiedenen Profile sind alle DIESELBE Entität."
Ohne sameAs
KI sieht:
- AICarma (Ihre Website)
- AICarma (LinkedIn-Unternehmensseite)
- AICarma (Crunchbase-Profil)
- 🤷 Sind das dasselbe?
Mit sameAs
KI versteht:
- Das sind alles dieselbe Entität
- Signale aus allen Quellen kombinieren
- Höhere Konfidenz im Entity-Verständnis
Implementierung
Auf Ihrer Homepage Organization-Schema mit umfassendem sameAs hinzufügen:
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "AICarma",
"@id": "https://aicarma.io/#organization",
"url": "https://aicarma.io",
"sameAs": [
"https://www.linkedin.com/company/aicarma",
"https://www.crunchbase.com/organization/aicarma",
"https://twitter.com/aicarma",
"https://www.g2.com/products/aicarma",
"https://www.facebook.com/aicarma",
"https://github.com/aicarma"
]
}
Welche Plattformen einschließen
| Plattform | In sameAs einschließen? | Warum |
|---|---|---|
| Immer | Hohe Autorität, weit gecrawlt | |
| Crunchbase | Immer | Kritisch für B2B/Startups |
| Twitter/X | Immer | Häufig in Trainingsdaten |
| Wenn aktiv | Nützlich für Consumer-Marken | |
| G2/Capterra | Für SaaS | Wichtig für Software-Entitäten |
| Wikipedia | Wenn vorhanden | Höchste Autorität |
| GitHub | Wenn relevant | Für Tech-Unternehmen |
| YouTube | Wenn Kanal existiert | Für Video-Präsenz |
N-A-P-Konsistenz: Das Fundament
N-A-P steht für Name, Adresse, Phone (Telefon) — die grundlegende Identitätstriade. Inkonsistenz hier erzeugt Entity-Verwirrung.
Das Problem mit Inkonsistenz
| Quelle | Unternehmensname | Ergebnis |
|---|---|---|
| Website | AICarma GmbH | ❌ Verwirrung |
| AICarma | ❌ Anders? | |
| Crunchbase | AI Carma | ❌ Dritte Entität? |
| G2 | AiCarma | ❌ Vierte Entität? |
KI-Systeme könnten diese als verschiedene Entitäten behandeln und Ihre Autorität fragmentieren.
Das N-A-P-Audit
- Alle Profile und Verzeichnisse auflisten, in denen Ihre Marke erscheint
- Das exakte NAP von jedem extrahieren
- Inkonsistenzen identifizieren
- Überall auf kanonische Version aktualisieren
Über grundlegendes NAP hinaus
Für B2B-Unternehmen erweitern um:
- Gründungsdatum (muss überall übereinstimmen)
- Kernbeschreibung (sollte hochgradig ähnlich sein)
- Schlüsselproduktnamen (standardisiert über Plattformen)
- Kategorie-/Branchenbezeichnungen
Knowledge-Graph-Präsenz: Der heilige Gral
Wenn Ihr Unternehmen im Google Knowledge Panel erscheint, wenn man danach sucht, haben Sie eine bedeutende Entity-Präsenz erreicht. Dieses Panel wird vom Knowledge Graph angetrieben — Googles strukturierte Datenbank realer Entitäten.
So bekommen Sie ein Knowledge Panel
- Wikipedia: Wenn Sie die Relevanzkriterien erfüllen, löst ein Wikipedia-Artikel Panels aus
- Wikidata: Auch ohne Wikipedia können Wikidata-Einträge Panels speisen
- Konsistente strukturierte Daten: Umfassendes Schema auf Ihrer Website
- Autoritative Erwähnungen: Nachrichtenberichterstattung, große Publikationen
Wenn Sie ein Panel haben
Beanspruchen Sie es: Gehen Sie zum Google-Unternehmensprofil und verifizieren Sie die Inhaberschaft. Dies ermöglicht Ihnen, Änderungen vorzuschlagen.
Auf Genauigkeit prüfen: Alle Fakten checken — Gründungsdatum, Standort, Beschreibung. Ungenauigkeiten melden.
Wenn Sie noch kein Panel haben
Konzentrieren Sie sich auf:
- Umfassendes Crunchbase-Profil aufbauen
- Berichterstattung in Mainstream-Medien erreichen (nicht nur Pressemitteilungen)
- Umfangreiches Schema auf Ihrer Website implementieren
- Wikidata-Eintrag erstellen (erfordert keine Relevanzkriterien)
Entity-Stärke messen
Wie wissen Sie, ob Ihre Entity-Building-Maßnahmen wirken?
Direkte Tests
Der ChatGPT-Beschreibungstest: Fragen Sie: „Beschreibe [Ihr Unternehmen]"
- Genau & detailliert = Starke Entität
- Vage oder vorsichtig = Schwache Entität
- „Ich habe keine Informationen" = Existiert kaum
Der Vergleichstest: Fragen Sie: „Vergleiche [Ihr Unternehmen] mit [Wettbewerber]"
- Detaillierter Vergleich = Starke Entitäten
- Einseitig (nur Wettbewerber) = Ihre Entität ist schwächer
- Verwechselte Attribute = Entity-Kontamination
Quantitative Indikatoren
| Metrik | Wie messen | Gutes Zeichen |
|---|---|---|
| Knowledge Panel | Ihren Markennamen googlen | Panel erscheint |
| Wikipedia | Wikipedia durchsuchen | Artikel existiert |
| Wikidata | Wikidata durchsuchen | Eintrag mit Eigenschaften |
| Branded Search Volume | Google Search Console | Wächst über Zeit |
| KI-Sichtbarkeits-Score | AICarma oder manuelles Testing | Hohe Erwähnungsrate |
Entity-Kontamination beheben
Entity-Kontamination tritt auf, wenn KI falsche Informationen über Ihre Marke hat — falsche Produkte, falsche Preise, falsche Gründer etc.
Häufige Ursachen
- Veraltete Informationen: Ihre Preise von 2019 sind noch in den Trainingsdaten
- Wettbewerber-Verwirrung: Ähnliche Namen verursachen Attributmischung
- Inkonsistente Quellen: Widersprüchliche Informationen über Profile hinweg
- Trainingsdaten-Fehler: Fehler in für das Training verwendeten Quellen
Die Lösung: Signal-Überwältigung
Sie können falsche Informationen nicht aus KI-Trainingsdaten löschen. Aber Sie können sie mit korrekten Signalen überwältigen:
- Alle Profile mit korrekten Informationen aktualisieren
- Umfangreiches Schema mit verifizierten Fakten hinzufügen
- Neue Berichterstattung mit korrekten Informationen erhalten
- Dedizierte FAQ-Inhalte erstellen, die häufig halluzinierte Fakten adressieren
- llms.txt mit kuratierten korrekten Informationen implementieren
Prävention
- Alle öffentlichen Profile vierteljährlich auditieren
- Informationen auf keiner Plattform veralten lassen
- Auf falsche Informationen in Bewertungen/Erwähnungen reagieren
- KI-Antworten auf Drift überwachen
FAQ
Brauche ich eine Wikipedia-Seite?
Sie hilft erheblich, ist aber nicht erforderlich. Wikidata-Einträge, umfassende Crunchbase-Profile und starkes Schema-Markup können Entity-Präsenz auch ohne Wikipedia etablieren. Wenn Sie jedoch die Relevanzkriterien erfüllen, steigert ein Wikipedia-Artikel die Knowledge-Graph-Präsenz dramatisch.
Wie beeinflusst Entity-SEO Sprachsuche?
Sprachassistenten (Siri, Alexa, Google Assistant) stützen sich stark auf den Knowledge Graph. Wenn jemand fragt „Wer hat [Ihr Unternehmen] gegründet?", kommt die Antwort aus Ihren Entity-Attributen, nicht aus Web-Seiten-Rankings. Starke Entity-Präsenz = akkurate Sprachsuche-Antworten.
Kann ich eine „halluzinierte" Entity-Beschreibung korrigieren?
Wenn KI Ihr Unternehmen falsch beschreibt (falsche Branche, falsche Produkte), müssen Sie das Ökosystem mit korrekten Signalen fluten. Alle Profile aktualisieren, detailliertes Schema implementieren, frische Presseberichterstattung mit korrekten Informationen erhalten. Es dauert 3-12 Monate, bis neue Trainingszyklen Korrekturen aufnehmen.
Was, wenn mein Unternehmen einen häufigen Namen hat?
Das ist eine Entity-Disambiguierungs-Herausforderung. Strategien umfassen:
- Immer Deskriptoren verwenden („Acme Software" nicht nur „Acme")
- Starke sameAs-Verbindungen aufbauen, die eine einzigartige Signatur erzeugen
- Spezifische Attributkombinationen anvisieren, die Sie differenzieren
- Bei schwerwiegender Verwirrung eine Markenentwicklung erwägen
Hilft Entity-Präsenz auch bei traditionellem SEO?
Ja. Google setzt zunehmend Entity-Verständnis in der traditionellen Suche ein. Websites mit starker Entity-Präsenz:
- Haben größere Chancen auf Knowledge Panels
- Bessere Chance auf Featured Snippets
- Verbesserte E-E-A-T-Signale
- Stärkere Performance bei Markenanfragen